 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting User Intents and Musical Attributes from Music Discovery Conversations
Nov 20, 2024Intent classification is a text understanding task that identifies user needs from input text queries. While intent classification has been extensively studied in various domains, it has not received much attention in the music domain. In this paper, we investigate intent classification models for music discovery conversation, focusing on pre-trained language models. Rather than only predicting functional needs: intent classification, we also include a task for classifying musical needs: musical attribute classification. Additionally, we propose a method of concatenating previous chat history with just single-turn user queries in the input text, allowing the model to understand the overall conversation context better. Our proposed model significantly improves the F1 score for both user intent and musical attribute classification, and surpasses the zero-shot and few-shot performance of the pretrained Llama 3 model.
Music Discovery Dialogue Generation Using Human Intent Analysis and Large Language Models
Nov 11, 2024A conversational music retrieval system can help users discover music that matches their preferences through dialogue. To achieve this, a conversational music retrieval system should seamlessly engage in multi-turn conversation by 1) understanding user queries and 2) responding with natural language and retrieved music. A straightforward solution would be a data-driven approach utilizing such conversation logs. However, few datasets are available for the research and are limited in terms of volume and quality. In this paper, we present a data generation framework for rich music discovery dialogue using a large language model (LLM) and user intents, system actions, and musical attributes. This is done by i) dialogue intent analysis using grounded theory, ii) generating attribute sequences via cascading database filtering, and iii) generating utterances using large language models. By applying this framework to the Million Song dataset, we create LP-MusicDialog, a Large Language Model based Pseudo Music Dialogue dataset, containing over 288k music conversations using more than 319k music items. Our evaluation shows that the synthetic dataset is competitive with an existing, small human dialogue dataset in terms of dialogue consistency, item relevance, and naturalness. Furthermore, using the dataset, we train a conversational music retrieval model and show promising results.
Enriching Music Descriptions with a Finetuned-LLM and Metadata for Text-to-Music Retrieval
Oct 04, 2024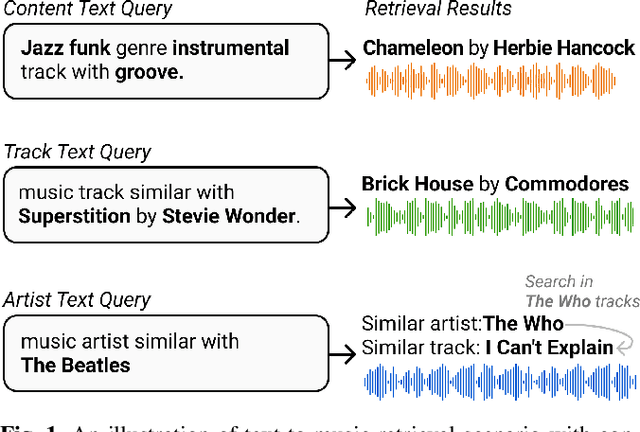
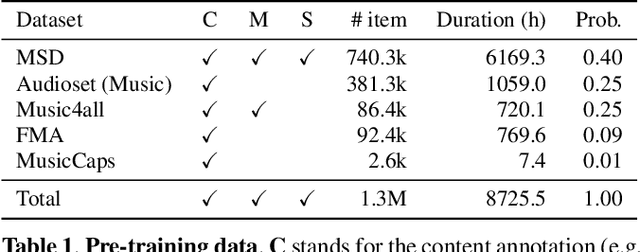
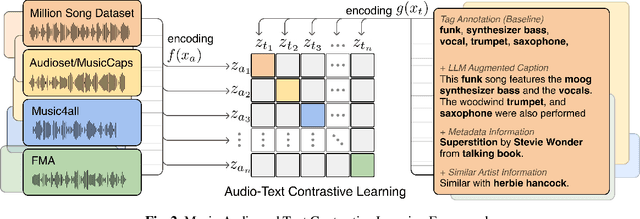
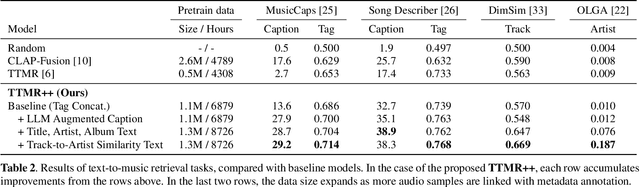
Text-to-Music Retrieval, finding music based on a given natural language query, plays a pivotal role in content discovery within extensive music databases. To address this challenge, prior research has predominantly focused on a joint embedding of music audio and text, utilizing it to retrieve music tracks that exactly match descriptive queries related to musical attributes (i.e. genre, instrument) and contextual elements (i.e. mood, theme). However, users also articulate a need to explore music that shares similarities with their favorite tracks or artists, such as \textit{I need a similar track to Superstition by Stevie Wonder}. To address these concerns, this paper proposes an improved Text-to-Music Retrieval model, denoted as TTMR++, which utilizes rich text descriptions generated with a finetuned large language model and metadata. To accomplish this, we obtained various types of seed text from several existing music tag and caption datasets and a knowledge graph dataset of artists and tracks. The experimental results show the effectiveness of TTMR++ in comparison to state-of-the-art music-text joint embedding models through a comprehensive evaluation involving various musical text queries.
Musical Word Embedding for Music Tagging and Retrieval
Apr 23, 2024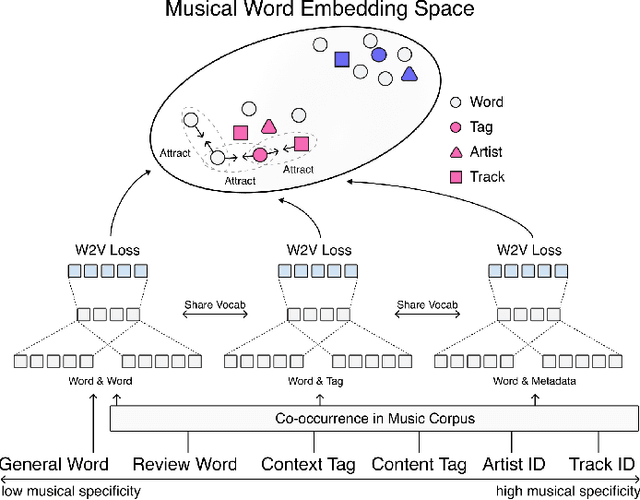
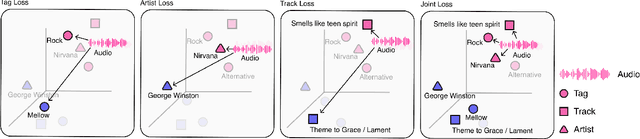
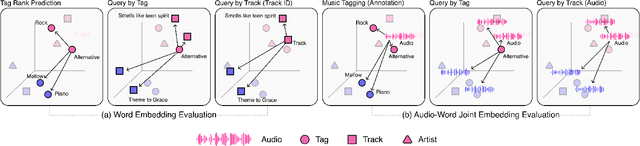
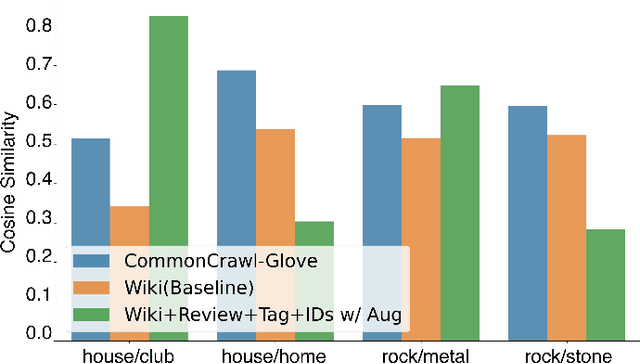
Word embedding has become an essential means for text-based information retrieval. Typically, word embeddings are learned from large quantities of general and unstructured text data. However, in the domain of music, the word embedding may have difficulty understanding musical contexts or recognizing music-related entities like artists and tracks. To address this issue, we propose a new approach called Musical Word Embedding (MWE), which involves learning from various types of texts, including both everyday and music-related vocabulary. We integrate MWE into an audio-word joint representation framework for tagging and retrieving music, using words like tag, artist, and track that have different levels of musical specificity. Our experiments show that using a more specific musical word like track results in better retrieval performance, while using a less specific term like tag leads to better tagging performance. To balance this compromise, we suggest multi-prototype training that uses words with different levels of musical specificity jointly. We evaluate both word embedding and audio-word joint embedding on four tasks (tag rank prediction, music tagging, query-by-tag, and query-by-track) across two datasets (Million Song Dataset and MTG-Jamendo). Our findings show that the suggested MWE is more efficient and robust than the conventional word embedding.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023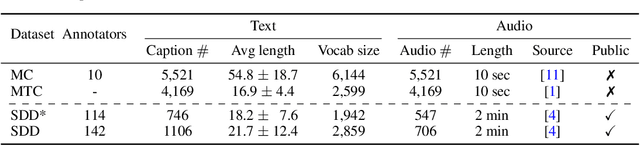
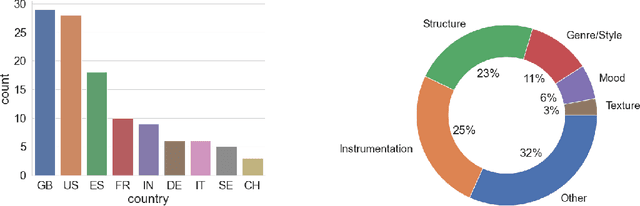


We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
LP-MusicCaps: LLM-Based Pseudo Music Captioning
Jul 31, 2023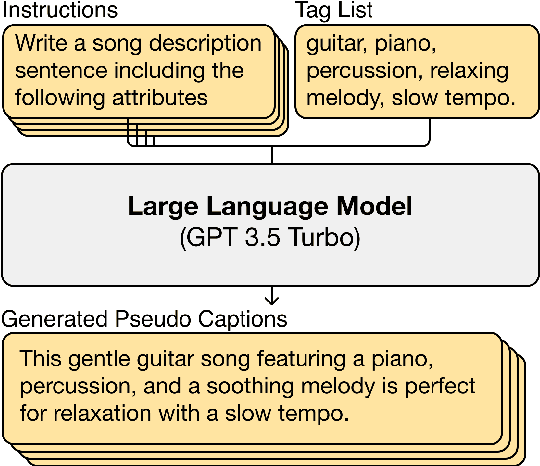

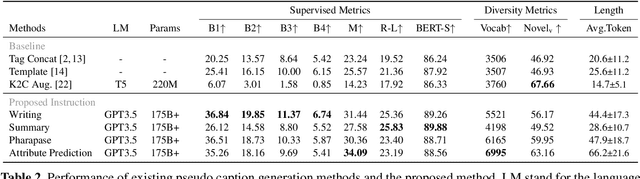
Automatic music captioning, which generates natural language descriptions for given music tracks, holds significant potential for enhancing the understanding and organization of large volumes of musical data. Despite its importance, researchers face challenges due to the costly and time-consuming collection process of existing music-language datasets, which are limited in size. To address this data scarcity issue, we propose the use of large language models (LLMs) to artificially generate the description sentences from large-scale tag datasets. This results in approximately 2.2M captions paired with 0.5M audio clips. We term it Large Language Model based Pseudo music caption dataset, shortly, LP-MusicCaps. We conduct a systemic evaluation of the large-scale music captioning dataset with various quantitative evaluation metrics used in the field of natural language processing as well as human evaluation. In addition, we trained a transformer-based music captioning model with the dataset and evaluated it under zero-shot and transfer-learning settings. The results demonstrate that our proposed approach outperforms the supervised baseline model.
Textless Speech-to-Music Retrieval Using Emotion Similarity
Mar 19, 2023
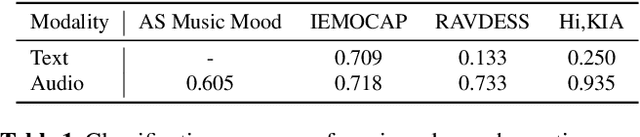


We introduce a framework that recommends music based on the emotions of speech. In content creation and daily life, speech contains information about human emotions, which can be enhanced by music. Our framework focuses on a cross-domain retrieval system to bridge the gap between speech and music via emotion labels. We explore different speech representations and report their impact on different speech types, including acting voice and wake-up words. We also propose an emotion similarity regularization term in cross-domain retrieval tasks. By incorporating the regularization term into training, similar speech-and-music pairs in the emotion space are closer in the joint embedding space. Our comprehensive experimental results show that the proposed model is effective in textless speech-to-music retrieval.
Music Playlist Title Generation Using Artist Information
Jan 14, 2023Automatically generating or captioning music playlist titles given a set of tracks is of significant interest in music streaming services as customized playlists are widely used in personalized music recommendation, and well-composed text titles attract users and help their music discovery. We present an encoder-decoder model that generates a playlist title from a sequence of music tracks. While previous work takes track IDs as tokenized input for playlist title generation, we use artist IDs corresponding to the tracks to mitigate the issue from the long-tail distribution of tracks included in the playlist dataset. Also, we introduce a chronological data split method to deal with newly-released tracks in real-world scenarios. Comparing the track IDs and artist IDs as input sequences, we show that the artist-based approach significantly enhances the performance in terms of word overlap, semantic relevance, and diversity.
Toward Universal Text-to-Music Retrieval
Nov 26, 2022



This paper introduces effective design choices for text-to-music retrieval systems. An ideal text-based retrieval system would support various input queries such as pre-defined tags, unseen tags, and sentence-level descriptions. In reality, most previous works mainly focused on a single query type (tag or sentence) which may not generalize to another input type. Hence, we review recent text-based music retrieval systems using our proposed benchmark in two main aspects: input text representation and training objectives. Our findings enable a universal text-to-music retrieval system that achieves comparable retrieval performances in both tag- and sentence-level inputs. Furthermore, the proposed multimodal representation generalizes to 9 different downstream music classification tasks. We present the code and demo online.
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
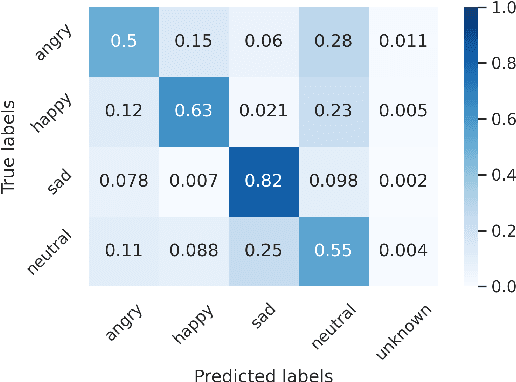
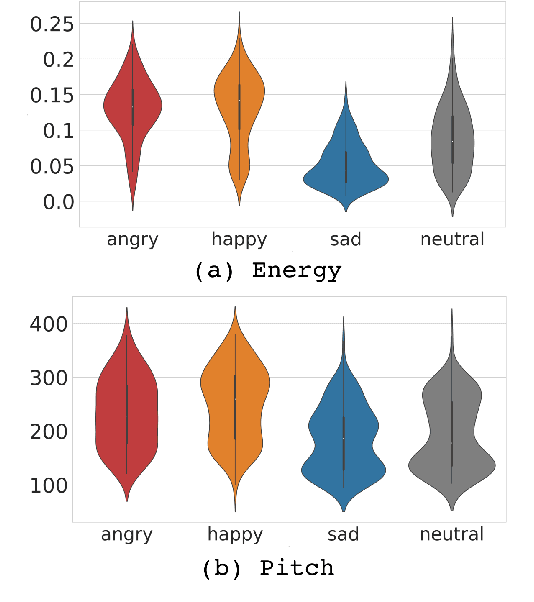
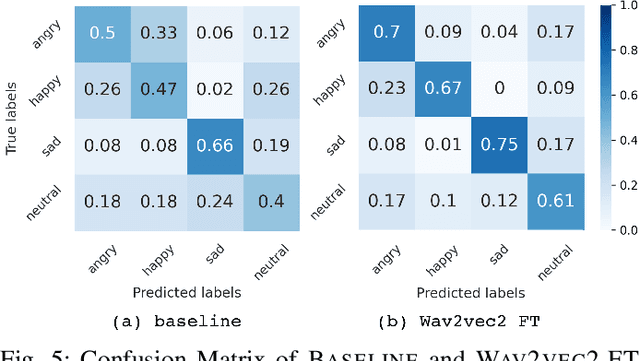
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.