 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
LAV: Audio-Driven Dynamic Visual Generation with Neural Compression and StyleGAN2
May 15, 2025This paper introduces LAV (Latent Audio-Visual), a system that integrates EnCodec's neural audio compression with StyleGAN2's generative capabilities to produce visually dynamic outputs driven by pre-recorded audio. Unlike previous works that rely on explicit feature mappings, LAV uses EnCodec embeddings as latent representations, directly transformed into StyleGAN2's style latent space via randomly initialized linear mapping. This approach preserves semantic richness in the transformation, enabling nuanced and semantically coherent audio-visual translations. The framework demonstrates the potential of using pretrained audio compression models for artistic and computational applications.
Boundary Regression for Leitmotif Detection in Music Audio
Mar 11, 2025

Leitmotifs are musical phrases that are reprised in various forms throughout a piece. Due to diverse variations and instrumentation, detecting the occurrence of leitmotifs from audio recordings is a highly challenging task. Leitmotif detection may be handled as a subcategory of audio event detection, where leitmotif activity is predicted at the frame level. However, as leitmotifs embody distinct, coherent musical structures, a more holistic approach akin to bounding box regression in visual object detection can be helpful. This method captures the entirety of a motif rather than fragmenting it into individual frames, thereby preserving its musical integrity and producing more useful predictions. We present our experimental results on tackling leitmotif detection as a boundary regression task.
MusicGen-Chord: Advancing Music Generation through Chord Progressions and Interactive Web-UI
Nov 30, 2024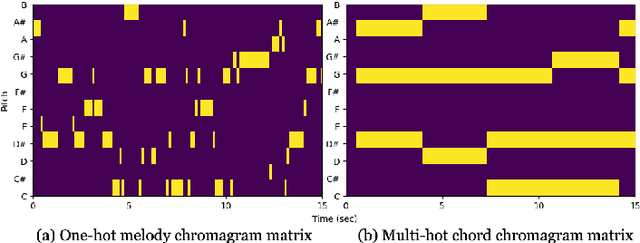
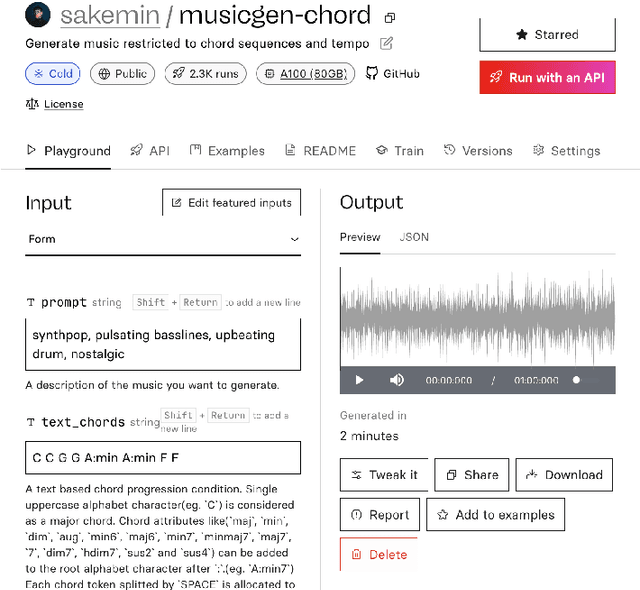
MusicGen is a music generation language model (LM) that can be conditioned on textual descriptions and melodic features. We introduce MusicGen-Chord, which extends this capability by incorporating chord progression features. This model modifies one-hot encoded melody chroma vectors into multi-hot encoded chord chroma vectors, enabling the generation of music that reflects both chord progressions and textual descriptions. Furthermore, we developed MusicGen-Remixer, an application utilizing MusicGen-Chord to generate remixes of input music conditioned on textual descriptions. Both models are integrated into Replicate's web-UI using cog, facilitating broad accessibility and user-friendly controllable interaction for creating and experiencing AI-generated music.
Towards Computational Analysis of Pansori Singing
Oct 16, 2024Pansori is one of the most representative vocal genres of Korean traditional music, which has an elaborated vocal melody line with strong vibrato. Although the music is transmitted orally without any music notation, transcribing pansori music in Western staff notation has been introduced for several purposes, such as documentation of music, education, or research. In this paper, we introduce computational analysis of pansori based on both audio and corresponding transcription, how modern Music Information Retrieval tasks can be used in analyzing traditional music and how it revealed different audio characteristics of what pansori contains.
Enriching Music Descriptions with a Finetuned-LLM and Metadata for Text-to-Music Retrieval
Oct 04, 2024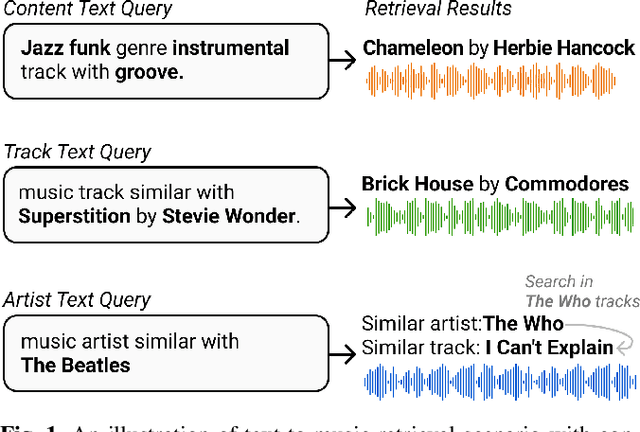
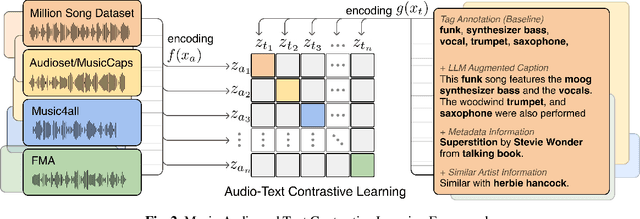
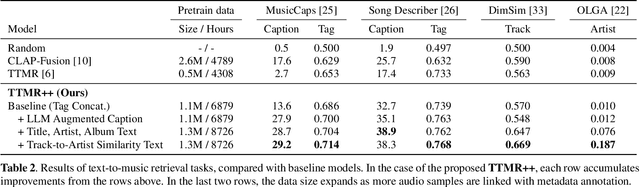
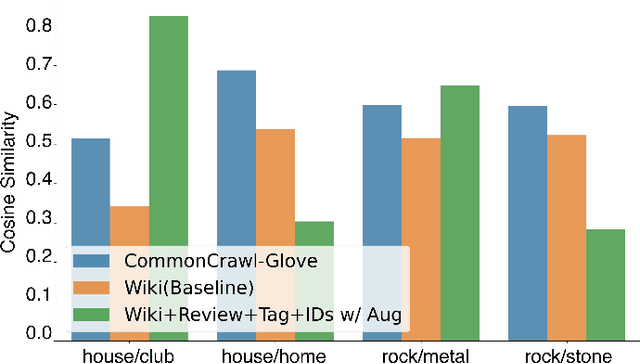
Text-to-Music Retrieval, finding music based on a given natural language query, plays a pivotal role in content discovery within extensive music databases. To address this challenge, prior research has predominantly focused on a joint embedding of music audio and text, utilizing it to retrieve music tracks that exactly match descriptive queries related to musical attributes (i.e. genre, instrument) and contextual elements (i.e. mood, theme). However, users also articulate a need to explore music that shares similarities with their favorite tracks or artists, such as \textit{I need a similar track to Superstition by Stevie Wonder}. To address these concerns, this paper proposes an improved Text-to-Music Retrieval model, denoted as TTMR++, which utilizes rich text descriptions generated with a finetuned large language model and metadata. To accomplish this, we obtained various types of seed text from several existing music tag and caption datasets and a knowledge graph dataset of artists and tracks. The experimental results show the effectiveness of TTMR++ in comparison to state-of-the-art music-text joint embedding models through a comprehensive evaluation involving various musical text queries.
Nested Music Transformer: Sequentially Decoding Compound Tokens in Symbolic Music and Audio Generation
Aug 02, 2024



Representing symbolic music with compound tokens, where each token consists of several different sub-tokens representing a distinct musical feature or attribute, offers the advantage of reducing sequence length. While previous research has validated the efficacy of compound tokens in music sequence modeling, predicting all sub-tokens simultaneously can lead to suboptimal results as it may not fully capture the interdependencies between them. We introduce the Nested Music Transformer (NMT), an architecture tailored for decoding compound tokens autoregressively, similar to processing flattened tokens, but with low memory usage. The NMT consists of two transformers: the main decoder that models a sequence of compound tokens and the sub-decoder for modeling sub-tokens of each compound token. The experiment results showed that applying the NMT to compound tokens can enhance the performance in terms of better perplexity in processing various symbolic music datasets and discrete audio tokens from the MAESTRO dataset.
Six Dragons Fly Again: Reviving 15th-Century Korean Court Music with Transformers and Novel Encoding
Aug 02, 2024



We introduce a project that revives a piece of 15th-century Korean court music, Chihwapyeong and Chwipunghyeong, composed upon the poem Songs of the Dragon Flying to Heaven. One of the earliest examples of Jeongganbo, a Korean musical notation system, the remaining version only consists of a rudimentary melody. Our research team, commissioned by the National Gugak (Korean Traditional Music) Center, aimed to transform this old melody into a performable arrangement for a six-part ensemble. Using Jeongganbo data acquired through bespoke optical music recognition, we trained a BERT-like masked language model and an encoder-decoder transformer model. We also propose an encoding scheme that strictly follows the structure of Jeongganbo and denotes note durations as positions. The resulting machine-transformed version of Chihwapyeong and Chwipunghyeong were evaluated by experts and performed by the Court Music Orchestra of National Gugak Center. Our work demonstrates that generative models can successfully be applied to traditional music with limited training data if combined with careful design.
Musical Word Embedding for Music Tagging and Retrieval
Apr 23, 2024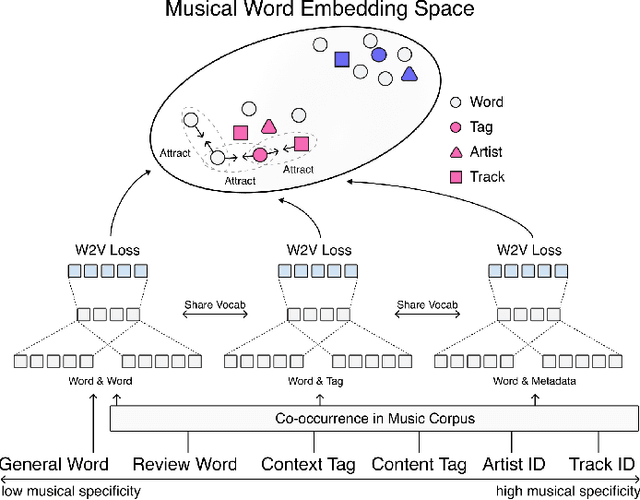
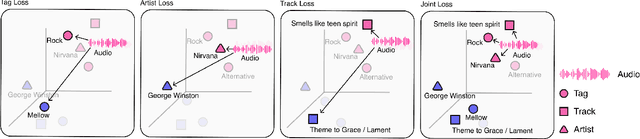
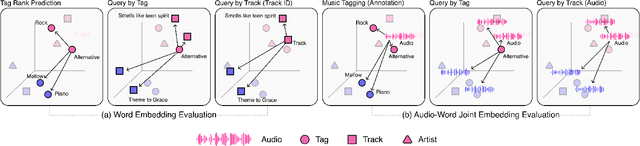
Word embedding has become an essential means for text-based information retrieval. Typically, word embeddings are learned from large quantities of general and unstructured text data. However, in the domain of music, the word embedding may have difficulty understanding musical contexts or recognizing music-related entities like artists and tracks. To address this issue, we propose a new approach called Musical Word Embedding (MWE), which involves learning from various types of texts, including both everyday and music-related vocabulary. We integrate MWE into an audio-word joint representation framework for tagging and retrieving music, using words like tag, artist, and track that have different levels of musical specificity. Our experiments show that using a more specific musical word like track results in better retrieval performance, while using a less specific term like tag leads to better tagging performance. To balance this compromise, we suggest multi-prototype training that uses words with different levels of musical specificity jointly. We evaluate both word embedding and audio-word joint embedding on four tasks (tag rank prediction, music tagging, query-by-tag, and query-by-track) across two datasets (Million Song Dataset and MTG-Jamendo). Our findings show that the suggested MWE is more efficient and robust than the conventional word embedding.
Towards Efficient and Real-Time Piano Transcription Using Neural Autoregressive Models
Apr 10, 2024In recent years, advancements in neural network designs and the availability of large-scale labeled datasets have led to significant improvements in the accuracy of piano transcription models. However, most previous work focused on high-performance offline transcription, neglecting deliberate consideration of model size. The goal of this work is to implement real-time inference for piano transcription while ensuring both high performance and lightweight. To this end, we propose novel architectures for convolutional recurrent neural networks, redesigning an existing autoregressive piano transcription model. First, we extend the acoustic module by adding a frequency-conditioned FiLM layer to the CNN module to adapt the convolutional filters on the frequency axis. Second, we improve note-state sequence modeling by using a pitchwise LSTM that focuses on note-state transitions within a note. In addition, we augment the autoregressive connection with an enhanced recursive context. Using these components, we propose two types of models; one for high performance and the other for high compactness. Through extensive experiments, we show that the proposed models are comparable to state-of-the-art models in terms of note accuracy on the MAESTRO dataset. We also investigate the effective model size and real-time inference latency by gradually streamlining the architecture. Finally, we conduct cross-data evaluation on unseen piano datasets and in-depth analysis to elucidate the effect of the proposed components in the view of note length and pitch range.