 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
LAV: Audio-Driven Dynamic Visual Generation with Neural Compression and StyleGAN2
May 15, 2025This paper introduces LAV (Latent Audio-Visual), a system that integrates EnCodec's neural audio compression with StyleGAN2's generative capabilities to produce visually dynamic outputs driven by pre-recorded audio. Unlike previous works that rely on explicit feature mappings, LAV uses EnCodec embeddings as latent representations, directly transformed into StyleGAN2's style latent space via randomly initialized linear mapping. This approach preserves semantic richness in the transformation, enabling nuanced and semantically coherent audio-visual translations. The framework demonstrates the potential of using pretrained audio compression models for artistic and computational applications.
MusicGen-Chord: Advancing Music Generation through Chord Progressions and Interactive Web-UI
Nov 30, 2024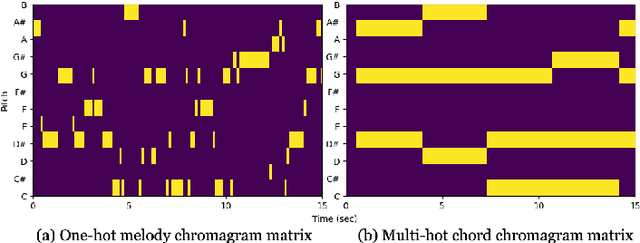
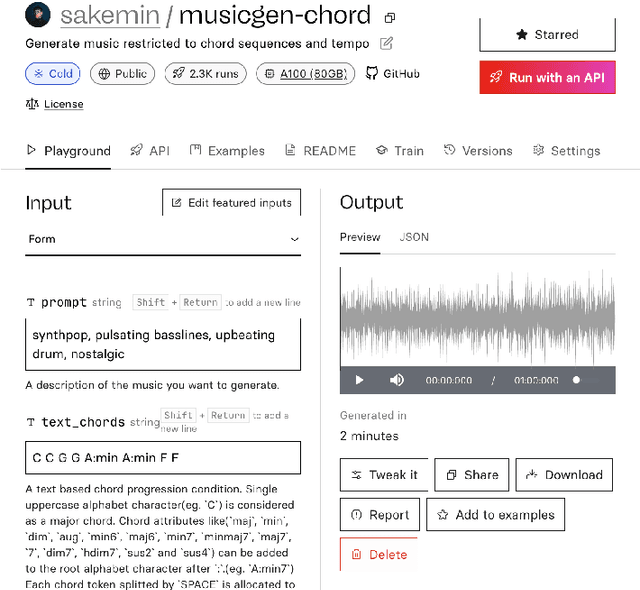
MusicGen is a music generation language model (LM) that can be conditioned on textual descriptions and melodic features. We introduce MusicGen-Chord, which extends this capability by incorporating chord progression features. This model modifies one-hot encoded melody chroma vectors into multi-hot encoded chord chroma vectors, enabling the generation of music that reflects both chord progressions and textual descriptions. Furthermore, we developed MusicGen-Remixer, an application utilizing MusicGen-Chord to generate remixes of input music conditioned on textual descriptions. Both models are integrated into Replicate's web-UI using cog, facilitating broad accessibility and user-friendly controllable interaction for creating and experiencing AI-generated music.
Nested Music Transformer: Sequentially Decoding Compound Tokens in Symbolic Music and Audio Generation
Aug 02, 2024



Representing symbolic music with compound tokens, where each token consists of several different sub-tokens representing a distinct musical feature or attribute, offers the advantage of reducing sequence length. While previous research has validated the efficacy of compound tokens in music sequence modeling, predicting all sub-tokens simultaneously can lead to suboptimal results as it may not fully capture the interdependencies between them. We introduce the Nested Music Transformer (NMT), an architecture tailored for decoding compound tokens autoregressively, similar to processing flattened tokens, but with low memory usage. The NMT consists of two transformers: the main decoder that models a sequence of compound tokens and the sub-decoder for modeling sub-tokens of each compound token. The experiment results showed that applying the NMT to compound tokens can enhance the performance in terms of better perplexity in processing various symbolic music datasets and discrete audio tokens from the MAESTRO dataset.
K-pop Lyric Translation: Dataset, Analysis, and Neural-Modelling
Sep 20, 2023

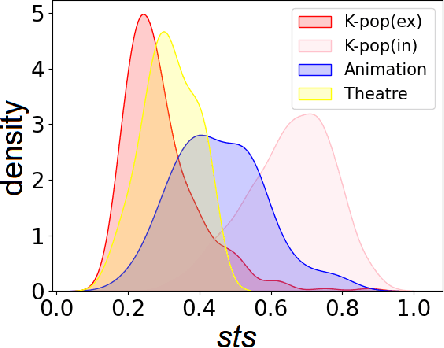
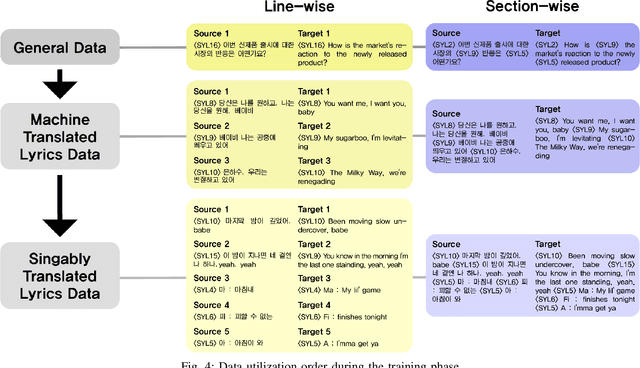
Lyric translation, a field studied for over a century, is now attracting computational linguistics researchers. We identified two limitations in previous studies. Firstly, lyric translation studies have predominantly focused on Western genres and languages, with no previous study centering on K-pop despite its popularity. Second, the field of lyric translation suffers from a lack of publicly available datasets; to the best of our knowledge, no such dataset exists. To broaden the scope of genres and languages in lyric translation studies, we introduce a novel singable lyric translation dataset, approximately 89\% of which consists of K-pop song lyrics. This dataset aligns Korean and English lyrics line-by-line and section-by-section. We leveraged this dataset to unveil unique characteristics of K-pop lyric translation, distinguishing it from other extensively studied genres, and to construct a neural lyric translation model, thereby underscoring the importance of a dedicated dataset for singable lyric translations.