 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Music Captioning with Music Metadata LLMs
Feb 03, 2026Music captioning, or the task of generating a natural language description of music, is useful for both music understanding and controllable music generation. Training captioning models, however, typically requires high-quality music caption data which is scarce compared to metadata (e.g., genre, mood, etc.). As a result, it is common to use large language models (LLMs) to synthesize captions from metadata to generate training data for captioning models, though this process imposes a fixed stylization and entangles factual information with natural language style. As a more direct approach, we propose metadata-based captioning. We train a metadata prediction model to infer detailed music metadata from audio and then convert it into expressive captions via pre-trained LLMs at inference time. Compared to a strong end-to-end baseline trained on LLM-generated captions derived from metadata, our method: (1) achieves comparable performance in less training time over end-to-end captioners, (2) offers flexibility to easily change stylization post-training, enabling output captions to be tailored to specific stylistic and quality requirements, and (3) can be prompted with audio and partial metadata to enable powerful metadata imputation or in-filling--a common task for organizing music data.
FoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025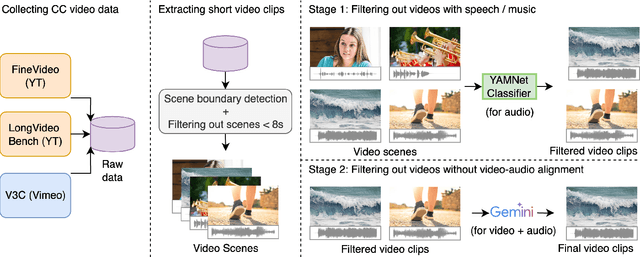
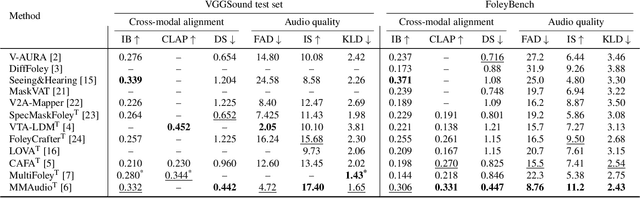
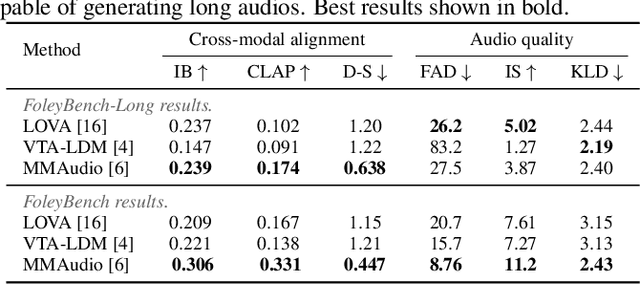

Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench
Live Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Music Arena: Live Evaluation for Text-to-Music
Jul 28, 2025We present Music Arena, an open platform for scalable human preference evaluation of text-to-music (TTM) models. Soliciting human preferences via listening studies is the gold standard for evaluation in TTM, but these studies are expensive to conduct and difficult to compare, as study protocols may differ across systems. Moreover, human preferences might help researchers align their TTM systems or improve automatic evaluation metrics, but an open and renewable source of preferences does not currently exist. We aim to fill these gaps by offering *live* evaluation for TTM. In Music Arena, real-world users input text prompts of their choosing and compare outputs from two TTM systems, and their preferences are used to compile a leaderboard. While Music Arena follows recent evaluation trends in other AI domains, we also design it with key features tailored to music: an LLM-based routing system to navigate the heterogeneous type signatures of TTM systems, and the collection of *detailed* preferences including listening data and natural language feedback. We also propose a rolling data release policy with user privacy guarantees, providing a renewable source of preference data and increasing platform transparency. Through its standardized evaluation protocol, transparent data access policies, and music-specific features, Music Arena not only addresses key challenges in the TTM ecosystem but also demonstrates how live evaluation can be thoughtfully adapted to unique characteristics of specific AI domains. Music Arena is available at: https://music-arena.org
Adaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
Unified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
Aligning Text-to-Music Evaluation with Human Preferences
Mar 20, 2025Despite significant recent advances in generative acoustic text-to-music (TTM) modeling, robust evaluation of these models lags behind, relying in particular on the popular Fr\'echet Audio Distance (FAD). In this work, we rigorously study the design space of reference-based divergence metrics for evaluating TTM models through (1) designing four synthetic meta-evaluations to measure sensitivity to particular musical desiderata, and (2) collecting and evaluating on MusicPrefs, the first open-source dataset of human preferences for TTM systems. We find that not only is the standard FAD setup inconsistent on both synthetic and human preference data, but that nearly all existing metrics fail to effectively capture desiderata, and are only weakly correlated with human perception. We propose a new metric, the MAUVE Audio Divergence (MAD), computed on representations from a self-supervised audio embedding model. We find that this metric effectively captures diverse musical desiderata (average rank correlation 0.84 for MAD vs. 0.49 for FAD and also correlates more strongly with MusicPrefs (0.62 vs. 0.14).
Hookpad Aria: A Copilot for Songwriters
Feb 12, 2025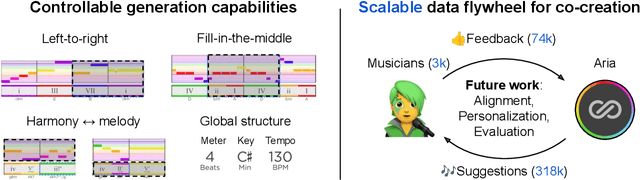

We present Hookpad Aria, a generative AI system designed to assist musicians in writing Western pop songs. Our system is seamlessly integrated into Hookpad, a web-based editor designed for the composition of lead sheets: symbolic music scores that describe melody and harmony. Hookpad Aria has numerous generation capabilities designed to assist users in non-sequential composition workflows, including: (1) generating left-to-right continuations of existing material, (2) filling in missing spans in the middle of existing material, and (3) generating harmony from melody and vice versa. Hookpad Aria is also a scalable data flywheel for music co-creation -- since its release in March 2024, Aria has generated 318k suggestions for 3k users who have accepted 74k into their songs. More information about Hookpad Aria is available at https://www.hooktheory.com/hookpad/aria
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024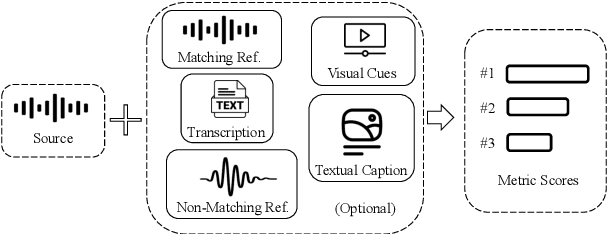
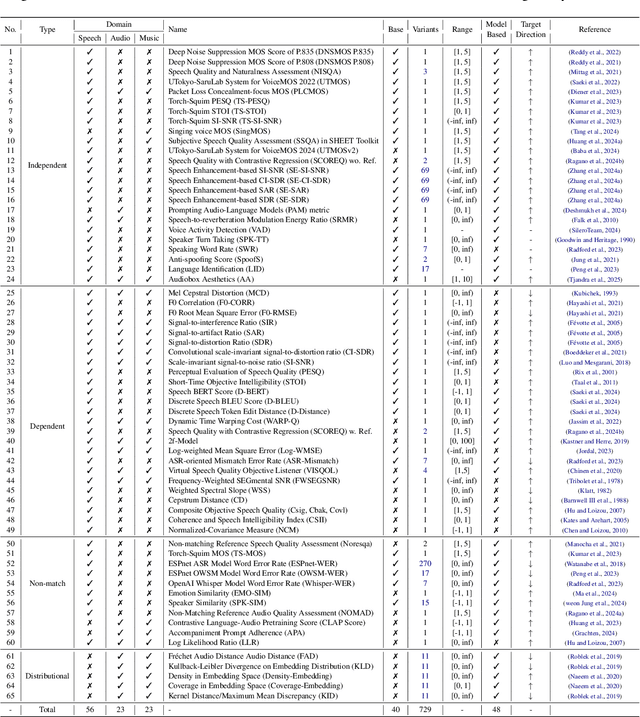

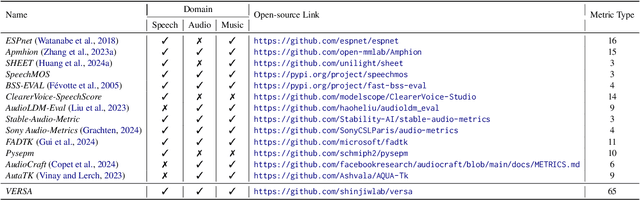
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Vision Language Models Are Few-Shot Audio Spectrogram Classifiers
Nov 18, 2024We demonstrate that vision language models (VLMs) are capable of recognizing the content in audio recordings when given corresponding spectrogram images. Specifically, we instruct VLMs to perform audio classification tasks in a few-shot setting by prompting them to classify a spectrogram image given example spectrogram images of each class. By carefully designing the spectrogram image representation and selecting good few-shot examples, we show that GPT-4o can achieve 59.00% cross-validated accuracy on the ESC-10 environmental sound classification dataset. Moreover, we demonstrate that VLMs currently outperform the only available commercial audio language model with audio understanding capabilities (Gemini-1.5) on the equivalent audio classification task (59.00% vs. 49.62%), and even perform slightly better than human experts on visual spectrogram classification (73.75% vs. 72.50% on first fold). We envision two potential use cases for these findings: (1) combining the spectrogram and language understanding capabilities of VLMs for audio caption augmentation, and (2) posing visual spectrogram classification as a challenge task for VLMs.