 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025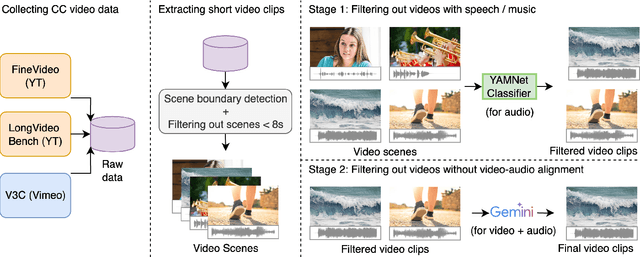
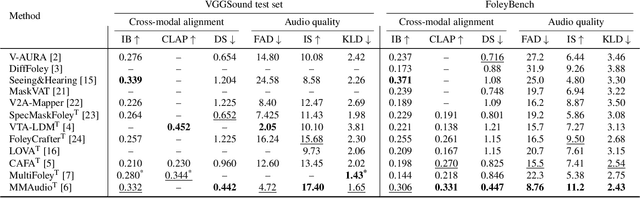
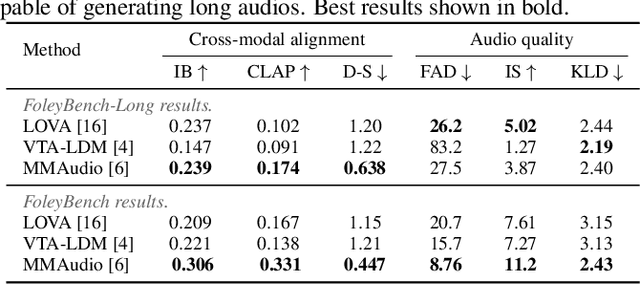

Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench
AURA Score: A Metric For Holistic Audio Question Answering Evaluation
Oct 06, 2025Audio Question Answering (AQA) is a key task for evaluating Audio-Language Models (ALMs), yet assessing open-ended responses remains challenging. Existing metrics used for AQA such as BLEU, METEOR and BERTScore, mostly adapted from NLP and audio captioning, rely on surface similarity and fail to account for question context, reasoning, and partial correctness. To address the gap in literature, we make three contributions in this work. First, we introduce AQEval to enable systematic benchmarking of AQA metrics. It is the first benchmark of its kind, consisting of 10k model responses annotated by multiple humans for their correctness and relevance. Second, we conduct a comprehensive analysis of existing AQA metrics on AQEval, highlighting weak correlation with human judgment, especially for longer answers. Third, we propose a new metric - AURA score, to better evaluate open-ended model responses. On AQEval, AURA achieves state-of-the-art correlation with human ratings, significantly outperforming all baselines. Through this work, we aim to highlight the limitations of current AQA evaluation methods and motivate better metrics. We release both the AQEval benchmark and the AURA metric to support future research in holistic AQA evaluation.
Mellow: a small audio language model for reasoning
Mar 11, 2025
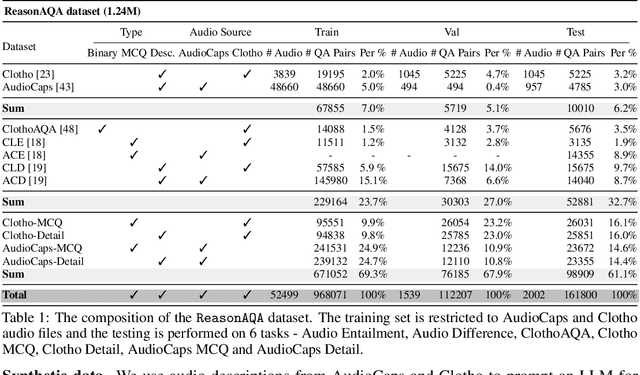
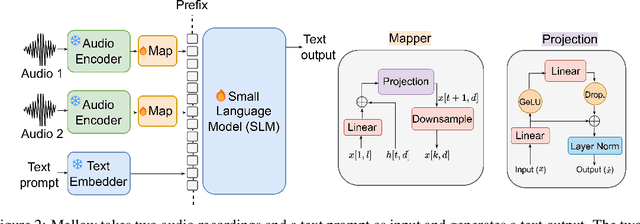
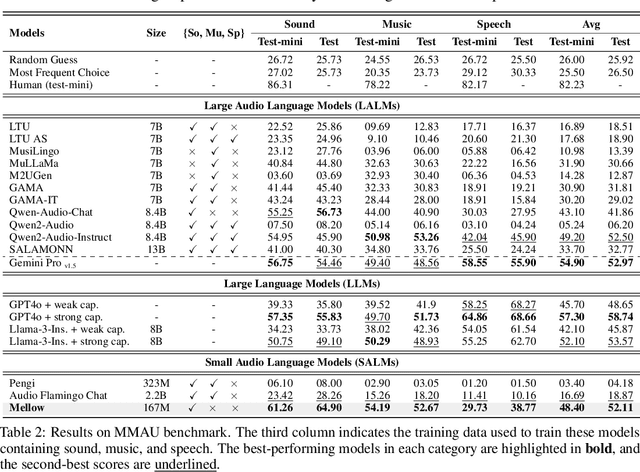
Multimodal Audio-Language Models (ALMs) can understand and reason over both audio and text. Typically, reasoning performance correlates with model size, with the best results achieved by models exceeding 8 billion parameters. However, no prior work has explored enabling small audio-language models to perform reasoning tasks, despite the potential applications for edge devices. To address this gap, we introduce Mellow, a small Audio-Language Model specifically designed for reasoning. Mellow achieves state-of-the-art performance among existing small audio-language models and surpasses several larger models in reasoning capabilities. For instance, Mellow scores 52.11 on MMAU, comparable to SoTA Qwen2 Audio (which scores 52.5) while using 50 times fewer parameters and being trained on 60 times less data (audio hrs). To train Mellow, we introduce ReasonAQA, a dataset designed to enhance audio-grounded reasoning in models. It consists of a mixture of existing datasets (30% of the data) and synthetically generated data (70%). The synthetic dataset is derived from audio captioning datasets, where Large Language Models (LLMs) generate detailed and multiple-choice questions focusing on audio events, objects, acoustic scenes, signal properties, semantics, and listener emotions. To evaluate Mellow's reasoning ability, we benchmark it on a diverse set of tasks, assessing on both in-distribution and out-of-distribution data, including audio understanding, deductive reasoning, and comparative reasoning. Finally, we conduct extensive ablation studies to explore the impact of projection layer choices, synthetic data generation methods, and language model pretraining on reasoning performance. Our training dataset, findings, and baseline pave the way for developing small ALMs capable of reasoning.
Vision Language Models Are Few-Shot Audio Spectrogram Classifiers
Nov 18, 2024We demonstrate that vision language models (VLMs) are capable of recognizing the content in audio recordings when given corresponding spectrogram images. Specifically, we instruct VLMs to perform audio classification tasks in a few-shot setting by prompting them to classify a spectrogram image given example spectrogram images of each class. By carefully designing the spectrogram image representation and selecting good few-shot examples, we show that GPT-4o can achieve 59.00% cross-validated accuracy on the ESC-10 environmental sound classification dataset. Moreover, we demonstrate that VLMs currently outperform the only available commercial audio language model with audio understanding capabilities (Gemini-1.5) on the equivalent audio classification task (59.00% vs. 49.62%), and even perform slightly better than human experts on visual spectrogram classification (73.75% vs. 72.50% on first fold). We envision two potential use cases for these findings: (1) combining the spectrogram and language understanding capabilities of VLMs for audio caption augmentation, and (2) posing visual spectrogram classification as a challenge task for VLMs.
MACE: Leveraging Audio for Evaluating Audio Captioning Systems
Nov 05, 2024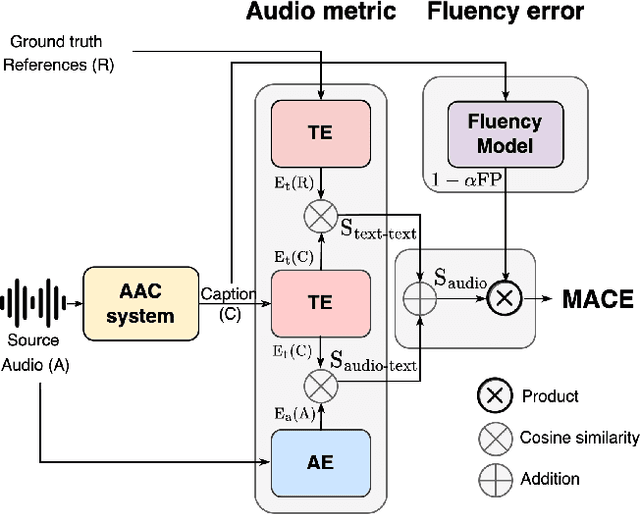
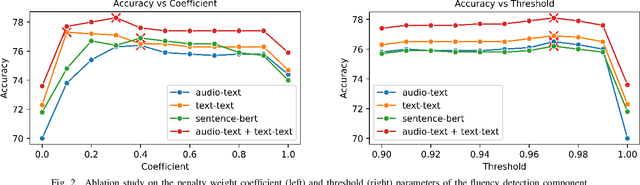
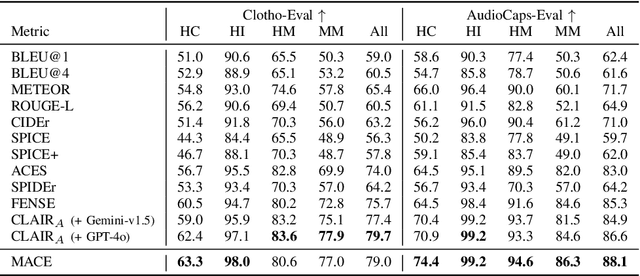
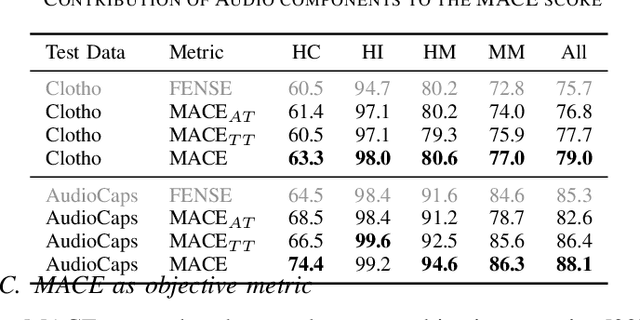
The Automated Audio Captioning (AAC) task aims to describe an audio signal using natural language. To evaluate machine-generated captions, the metrics should take into account audio events, acoustic scenes, paralinguistics, signal characteristics, and other audio information. Traditional AAC evaluation relies on natural language generation metrics like ROUGE and BLEU, image captioning metrics such as SPICE and CIDEr, or Sentence-BERT embedding similarity. However, these metrics only compare generated captions to human references, overlooking the audio signal itself. In this work, we propose MACE (Multimodal Audio-Caption Evaluation), a novel metric that integrates both audio and reference captions for comprehensive audio caption evaluation. MACE incorporates audio information from audio as well as predicted and reference captions and weights it with a fluency penalty. Our experiments demonstrate MACE's superior performance in predicting human quality judgments compared to traditional metrics. Specifically, MACE achieves a 3.28% and 4.36% relative accuracy improvement over the FENSE metric on the AudioCaps-Eval and Clotho-Eval datasets respectively. Moreover, it significantly outperforms all the previous metrics on the audio captioning evaluation task. The metric is opensourced at https://github.com/satvik-dixit/mace
Improving Speaker Representations Using Contrastive Losses on Multi-scale Features
Oct 07, 2024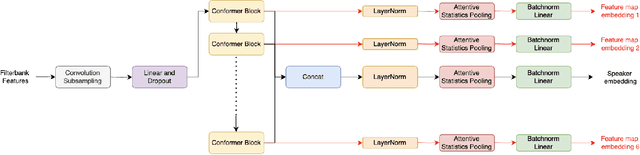
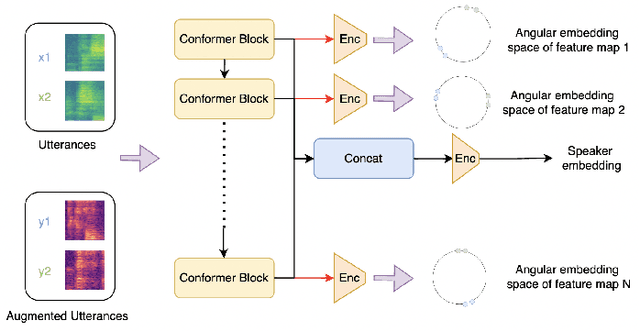
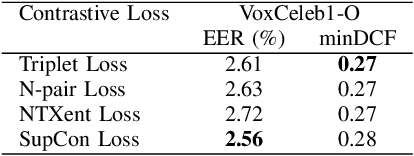

Speaker verification systems have seen significant advancements with the introduction of Multi-scale Feature Aggregation (MFA) architectures, such as MFA-Conformer and ECAPA-TDNN. These models leverage information from various network depths by concatenating intermediate feature maps before the pooling and projection layers, demonstrating that even shallower feature maps encode valuable speaker-specific information. Building upon this foundation, we propose a Multi-scale Feature Contrastive (MFCon) loss that directly enhances the quality of these intermediate representations. Our MFCon loss applies contrastive learning to all feature maps within the network, encouraging the model to learn more discriminative representations at the intermediate stage itself. By enforcing better feature map learning, we show that the resulting speaker embeddings exhibit increased discriminative power. Our method achieves a 9.05% improvement in equal error rate (EER) compared to the standard MFA-Conformer on the VoxCeleb-1O test set.
Explaining Deep Learning Embeddings for Speech Emotion Recognition by Predicting Interpretable Acoustic Features
Sep 14, 2024Pre-trained deep learning embeddings have consistently shown superior performance over handcrafted acoustic features in speech emotion recognition (SER). However, unlike acoustic features with clear physical meaning, these embeddings lack clear interpretability. Explaining these embeddings is crucial for building trust in healthcare and security applications and advancing the scientific understanding of the acoustic information that is encoded in them. This paper proposes a modified probing approach to explain deep learning embeddings in the SER space. We predict interpretable acoustic features (e.g., f0, loudness) from (i) the complete set of embeddings and (ii) a subset of the embedding dimensions identified as most important for predicting each emotion. If the subset of the most important dimensions better predicts a given emotion than all dimensions and also predicts specific acoustic features more accurately, we infer those acoustic features are important for the embedding model for the given task. We conducted experiments using the WavLM embeddings and eGeMAPS acoustic features as audio representations, applying our method to the RAVDESS and SAVEE emotional speech datasets. Based on this evaluation, we demonstrate that Energy, Frequency, Spectral, and Temporal categories of acoustic features provide diminishing information to SER in that order, demonstrating the utility of the probing classifier method to relate embeddings to interpretable acoustic features.