 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speaker Representations Using Contrastive Losses on Multi-scale Features
Paper and Code
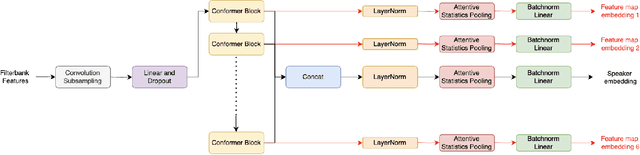
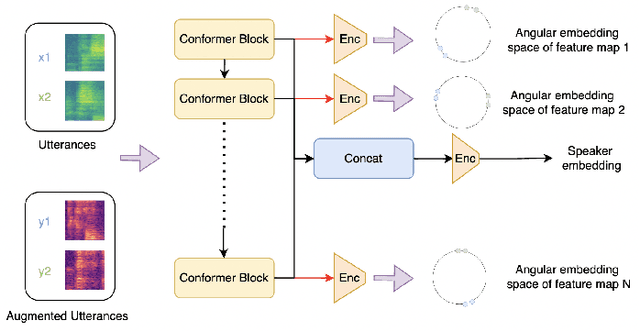
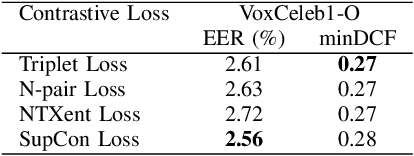

Speaker verification systems have seen significant advancements with the introduction of Multi-scale Feature Aggregation (MFA) architectures, such as MFA-Conformer and ECAPA-TDNN. These models leverage information from various network depths by concatenating intermediate feature maps before the pooling and projection layers, demonstrating that even shallower feature maps encode valuable speaker-specific information. Building upon this foundation, we propose a Multi-scale Feature Contrastive (MFCon) loss that directly enhances the quality of these intermediate representations. Our MFCon loss applies contrastive learning to all feature maps within the network, encouraging the model to learn more discriminative representations at the intermediate stage itself. By enforcing better feature map learning, we show that the resulting speaker embeddings exhibit increased discriminative power. Our method achieves a 9.05% improvement in equal error rate (EER) compared to the standard MFA-Conformer on the VoxCeleb-1O test set.