 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat and When to Learn: CURriculum Ranking Loss for Large-Scale Speaker Verification
Mar 25, 2026Speaker verification at large scale remains an open challenge as fixed-margin losses treat all samples equally regardless of quality. We hypothesize that mislabeled or degraded samples introduce noisy gradients that disrupt compact speaker manifolds. We propose Curry (CURriculum Ranking), an adaptive loss that estimates sample difficulty online via Sub-center ArcFace: confidence scores from dominant sub-center cosine similarity rank samples into easy, medium, and hard tiers using running batch statistics, without auxiliary annotations. Learnable weights guide the model from stable identity foundations through manifold refinement to boundary sharpening. To our knowledge, this is the largest-scale speaker verification system trained to date. Evaluated on VoxCeleb1-O, and SITW, Curry reduces EER by 86.8\% and 60.0\% over the Sub-center ArcFace baseline, establishing a new paradigm for robust speaker verification on imperfect large-scale data.
VerLM: Explaining Face Verification Using Natural Language
Jan 05, 2026Face verification systems have seen substantial advancements; however, they often lack transparency in their decision-making processes. In this paper, we introduce an innovative Vision-Language Model (VLM) for Face Verification, which not only accurately determines if two face images depict the same individual but also explicitly explains the rationale behind its decisions. Our model is uniquely trained using two complementary explanation styles: (1) concise explanations that summarize the key factors influencing its decision, and (2) comprehensive explanations detailing the specific differences observed between the images. We adapt and enhance a state-of-the-art modeling approach originally designed for audio-based differentiation to suit visual inputs effectively. This cross-modal transfer significantly improves our model's accuracy and interpretability. The proposed VLM integrates sophisticated feature extraction techniques with advanced reasoning capabilities, enabling clear articulation of its verification process. Our approach demonstrates superior performance, surpassing baseline methods and existing models. These findings highlight the immense potential of vision language models in face verification set up, contributing to more transparent, reliable, and explainable face verification systems.
CoLMbo: Speaker Language Model for Descriptive Profiling
Jun 11, 2025Speaker recognition systems are often limited to classification tasks and struggle to generate detailed speaker characteristics or provide context-rich descriptions. These models primarily extract embeddings for speaker identification but fail to capture demographic attributes such as dialect, gender, and age in a structured manner. This paper introduces CoLMbo, a Speaker Language Model (SLM) that addresses these limitations by integrating a speaker encoder with prompt-based conditioning. This allows for the creation of detailed captions based on speaker embeddings. CoLMbo utilizes user-defined prompts to adapt dynamically to new speaker characteristics and provides customized descriptions, including regional dialect variations and age-related traits. This innovative approach not only enhances traditional speaker profiling but also excels in zero-shot scenarios across diverse datasets, marking a significant advancement in the field of speaker recognition.
CAARMA: Class Augmentation with Adversarial Mixup Regularization
Mar 20, 2025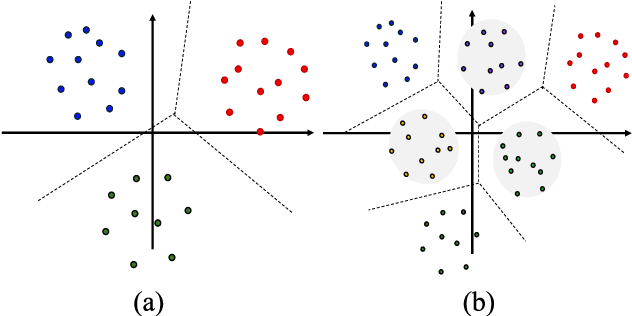
Speaker verification is a typical zero-shot learning task, where inference of unseen classes is performed by comparing embeddings of test instances to known examples. The models performing inference must hence naturally generate embeddings that cluster same-class instances compactly, while maintaining separation across classes. In order to learn to do so, they are typically trained on a large number of classes (speakers), often using specialized losses. However real-world speaker datasets often lack the class diversity needed to effectively learn this in a generalizable manner. We introduce CAARMA, a class augmentation framework that addresses this problem by generating synthetic classes through data mixing in the embedding space, expanding the number of training classes. To ensure the authenticity of the synthetic classes we adopt a novel adversarial refinement mechanism that minimizes categorical distinctions between synthetic and real classes. We evaluate CAARMA on multiple speaker verification tasks, as well as other representative zero-shot comparison-based speech analysis tasks and obtain consistent improvements: our framework demonstrates a significant improvement of 8\% over all baseline models. Code for CAARMA will be released.
Improving Speaker Representations Using Contrastive Losses on Multi-scale Features
Oct 07, 2024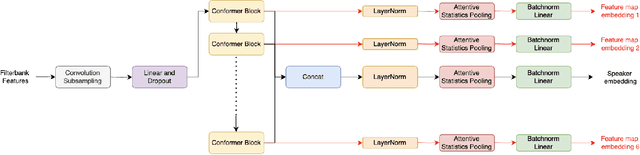
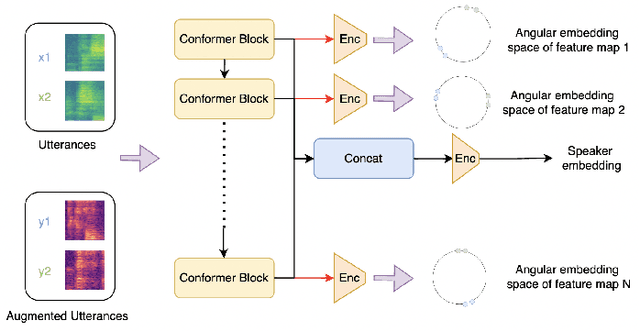
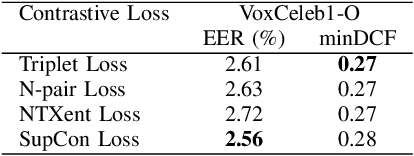

Speaker verification systems have seen significant advancements with the introduction of Multi-scale Feature Aggregation (MFA) architectures, such as MFA-Conformer and ECAPA-TDNN. These models leverage information from various network depths by concatenating intermediate feature maps before the pooling and projection layers, demonstrating that even shallower feature maps encode valuable speaker-specific information. Building upon this foundation, we propose a Multi-scale Feature Contrastive (MFCon) loss that directly enhances the quality of these intermediate representations. Our MFCon loss applies contrastive learning to all feature maps within the network, encouraging the model to learn more discriminative representations at the intermediate stage itself. By enforcing better feature map learning, we show that the resulting speaker embeddings exhibit increased discriminative power. Our method achieves a 9.05% improvement in equal error rate (EER) compared to the standard MFA-Conformer on the VoxCeleb-1O test set.
ESPnet-Codec: Comprehensive Training and Evaluation of Neural Codecs for Audio, Music, and Speech
Sep 24, 2024Neural codecs have become crucial to recent speech and audio generation research. In addition to signal compression capabilities, discrete codecs have also been found to enhance downstream training efficiency and compatibility with autoregressive language models. However, as extensive downstream applications are investigated, challenges have arisen in ensuring fair comparisons across diverse applications. To address these issues, we present a new open-source platform ESPnet-Codec, which is built on ESPnet and focuses on neural codec training and evaluation. ESPnet-Codec offers various recipes in audio, music, and speech for training and evaluation using several widely adopted codec models. Together with ESPnet-Codec, we present VERSA, a standalone evaluation toolkit, which provides a comprehensive evaluation of codec performance over 20 audio evaluation metrics. Notably, we demonstrate that ESPnet-Codec can be integrated into six ESPnet tasks, supporting diverse applications.
PDAF: A Phonetic Debiasing Attention Framework For Speaker Verification
Sep 09, 2024

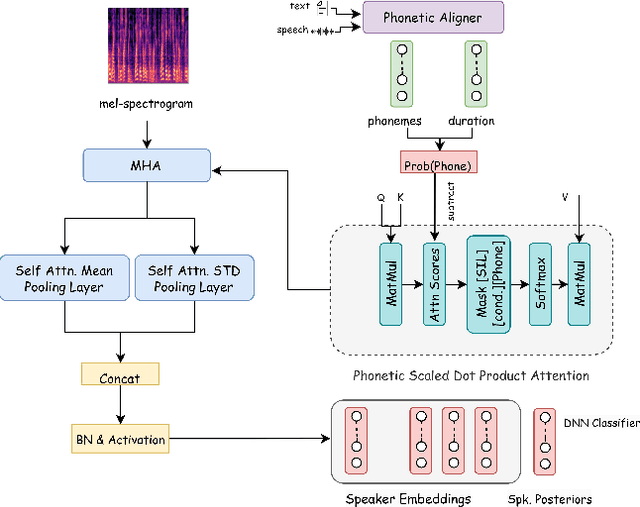

Speaker verification systems are crucial for authenticating identity through voice. Traditionally, these systems focus on comparing feature vectors, overlooking the speech's content. However, this paper challenges this by highlighting the importance of phonetic dominance, a measure of the frequency or duration of phonemes, as a crucial cue in speaker verification. A novel Phoneme Debiasing Attention Framework (PDAF) is introduced, integrating with existing attention frameworks to mitigate biases caused by phonetic dominance. PDAF adjusts the weighting for each phoneme and influences feature extraction, allowing for a more nuanced analysis of speech. This approach paves the way for more accurate and reliable identity authentication through voice. Furthermore, by employing various weighting strategies, we evaluate the influence of phonetic features on the efficacy of the speaker verification system.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023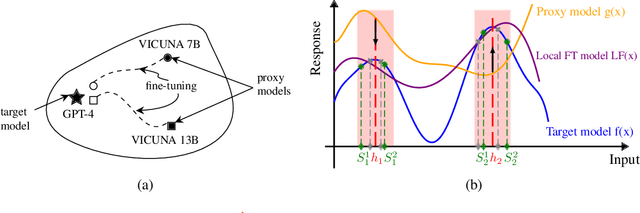

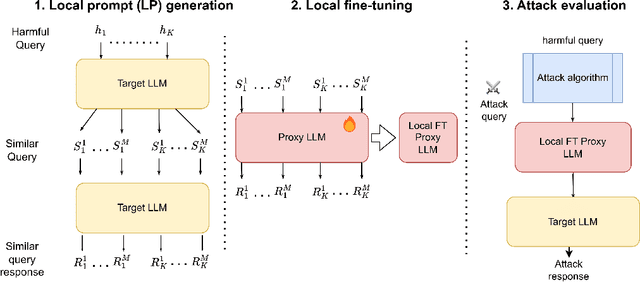

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
Aug 30, 2023
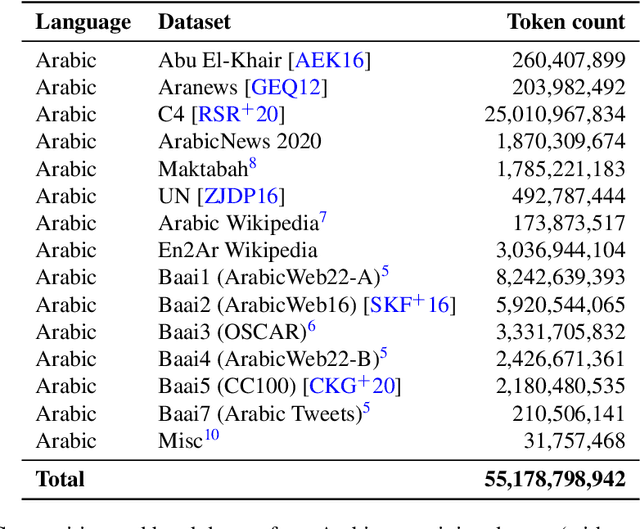
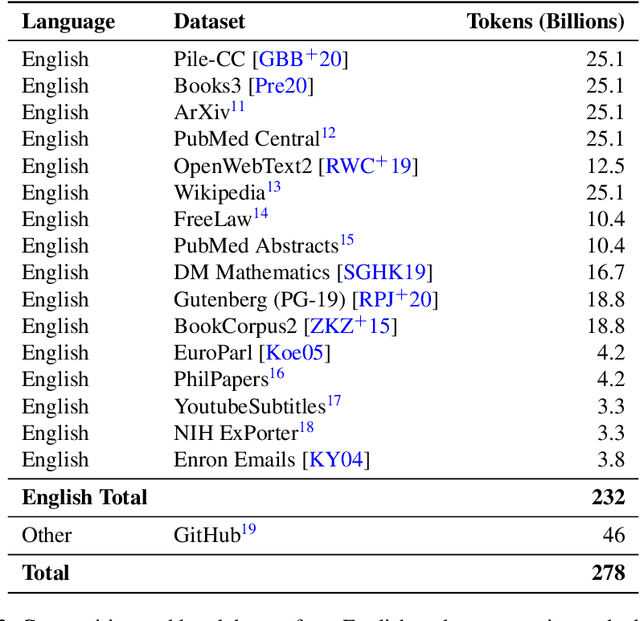
We introduce Jais and Jais-chat, new state-of-the-art Arabic-centric foundation and instruction-tuned open generative large language models (LLMs). The models are based on the GPT-3 decoder-only architecture and are pretrained on a mixture of Arabic and English texts, including source code in various programming languages. With 13 billion parameters, they demonstrate better knowledge and reasoning capabilities in Arabic than any existing open Arabic and multilingual models by a sizable margin, based on extensive evaluation. Moreover, the models are competitive in English compared to English-centric open models of similar size, despite being trained on much less English data. We provide a detailed description of the training, the tuning, the safety alignment, and the evaluation of the models. We release two open versions of the model -- the foundation Jais model, and an instruction-tuned Jais-chat variant -- with the aim of promoting research on Arabic LLMs. Available at https://huggingface.co/inception-mbzuai/jais-13b-chat
FOOCTTS: Generating Arabic Speech with Acoustic Environment for Football Commentator
Jun 07, 2023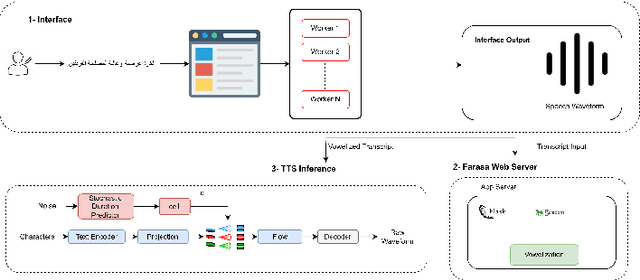
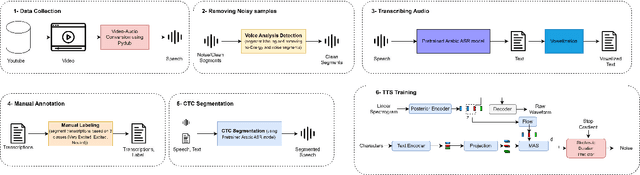
This paper presents FOOCTTS, an automatic pipeline for a football commentator that generates speech with background crowd noise. The application gets the text from the user, applies text pre-processing such as vowelization, followed by the commentator's speech synthesizer. Our pipeline included Arabic automatic speech recognition for data labeling, CTC segmentation, transcription vowelization to match speech, and fine-tuning the TTS. Our system is capable of generating speech with its acoustic environment within limited 15 minutes of football commentator recording. Our prototype is generalizable and can be easily applied to different domains and languages.