 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023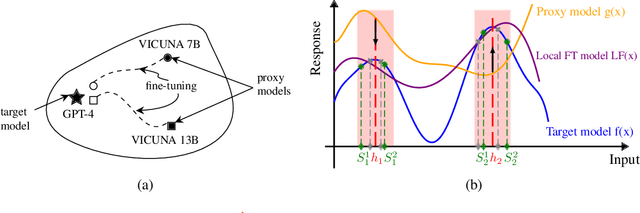

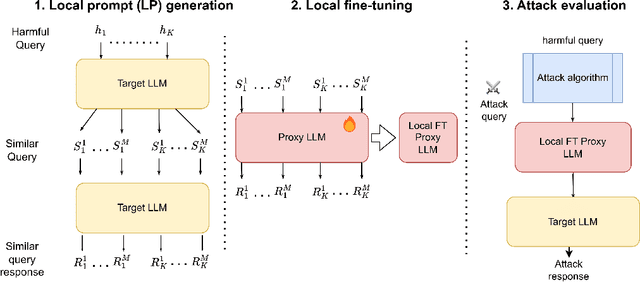

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Fixed Inter-Neuron Covariability Induces Adversarial Robustness
Aug 07, 2023The vulnerability to adversarial perturbations is a major flaw of Deep Neural Networks (DNNs) that raises question about their reliability when in real-world scenarios. On the other hand, human perception, which DNNs are supposed to emulate, is highly robust to such perturbations, indicating that there may be certain features of the human perception that make it robust but are not represented in the current class of DNNs. One such feature is that the activity of biological neurons is correlated and the structure of this correlation tends to be rather rigid over long spans of times, even if it hampers performance and learning. We hypothesize that integrating such constraints on the activations of a DNN would improve its adversarial robustness, and, to test this hypothesis, we have developed the Self-Consistent Activation (SCA) layer, which comprises of neurons whose activations are consistent with each other, as they conform to a fixed, but learned, covariability pattern. When evaluated on image and sound recognition tasks, the models with a SCA layer achieved high accuracy, and exhibited significantly greater robustness than multi-layer perceptron models to state-of-the-art Auto-PGD adversarial attacks \textit{without being trained on adversarially perturbed data