 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CMU-AIST submission for the ICME 2025 Audio Encoder Challenge
Jan 22, 2026This technical report describes our submission to the ICME 2025 audio encoder challenge. Our submitted system is built on BEATs, a masked speech token prediction based audio encoder. We extend the BEATs model using 74,000 hours of data derived from various speech, music, and sound corpora and scale its architecture upto 300 million parameters. We experiment with speech-heavy and balanced pre-training mixtures to study the impact of different domains on final performance. Our submitted system consists of an ensemble of the Dasheng 1.2 billion model with two custom scaled-up BEATs models trained on the aforementioned pre-training data mixtures. We also propose a simple ensembling technique that retains the best capabilities of constituent models and surpasses both the baseline and Dasheng 1.2B. For open science, we publicly release our trained checkpoints via huggingface at https://huggingface.co/shikhar7ssu/OpenBEATs-ICME-SOUND and https://huggingface.co/shikhar7ssu/OpenBEATs-ICME.
AURA Score: A Metric For Holistic Audio Question Answering Evaluation
Oct 06, 2025Audio Question Answering (AQA) is a key task for evaluating Audio-Language Models (ALMs), yet assessing open-ended responses remains challenging. Existing metrics used for AQA such as BLEU, METEOR and BERTScore, mostly adapted from NLP and audio captioning, rely on surface similarity and fail to account for question context, reasoning, and partial correctness. To address the gap in literature, we make three contributions in this work. First, we introduce AQEval to enable systematic benchmarking of AQA metrics. It is the first benchmark of its kind, consisting of 10k model responses annotated by multiple humans for their correctness and relevance. Second, we conduct a comprehensive analysis of existing AQA metrics on AQEval, highlighting weak correlation with human judgment, especially for longer answers. Third, we propose a new metric - AURA score, to better evaluate open-ended model responses. On AQEval, AURA achieves state-of-the-art correlation with human ratings, significantly outperforming all baselines. Through this work, we aim to highlight the limitations of current AQA evaluation methods and motivate better metrics. We release both the AQEval benchmark and the AURA metric to support future research in holistic AQA evaluation.
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Jul 18, 2025



Masked token prediction has emerged as a powerful pre-training objective across language, vision, and speech, offering the potential to unify these diverse modalities through a single pre-training task. However, its application for general audio understanding remains underexplored, with BEATs being the only notable example. BEATs has seen limited modifications due to the absence of open-source pre-training code. Furthermore, BEATs was trained only on AudioSet, restricting its broader downstream applicability. To address these gaps, we present OpenBEATs, an open-source framework that extends BEATs via multi-domain audio pre-training. We conduct comprehensive evaluations across six types of tasks, twenty five datasets, and three audio domains, including audio reasoning tasks such as audio question answering, entailment, and captioning. OpenBEATs achieves state-of-the-art performance on six bioacoustics datasets, two environmental sound datasets and five reasoning datasets, performing better than models exceeding a billion parameters at one-fourth their parameter size. These results demonstrate the effectiveness of multi-domain datasets and masked token prediction task to learn general-purpose audio representations. To promote further research and reproducibility, we release all pre-training and evaluation code, pretrained and fine-tuned checkpoints, and training logs at https://shikhar-s.github.io/OpenBEATs
CoLMbo: Speaker Language Model for Descriptive Profiling
Jun 11, 2025Speaker recognition systems are often limited to classification tasks and struggle to generate detailed speaker characteristics or provide context-rich descriptions. These models primarily extract embeddings for speaker identification but fail to capture demographic attributes such as dialect, gender, and age in a structured manner. This paper introduces CoLMbo, a Speaker Language Model (SLM) that addresses these limitations by integrating a speaker encoder with prompt-based conditioning. This allows for the creation of detailed captions based on speaker embeddings. CoLMbo utilizes user-defined prompts to adapt dynamically to new speaker characteristics and provides customized descriptions, including regional dialect variations and age-related traits. This innovative approach not only enhances traditional speaker profiling but also excels in zero-shot scenarios across diverse datasets, marking a significant advancement in the field of speaker recognition.
Mellow: a small audio language model for reasoning
Mar 11, 2025
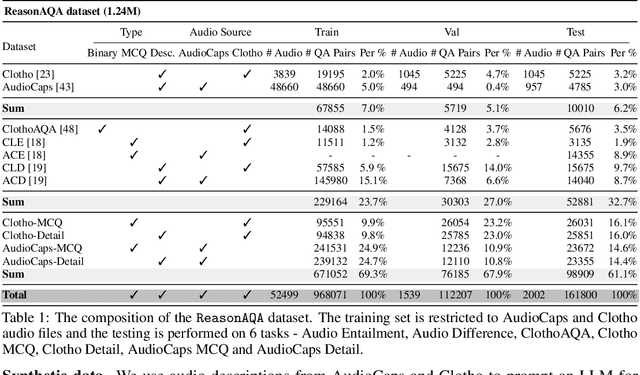
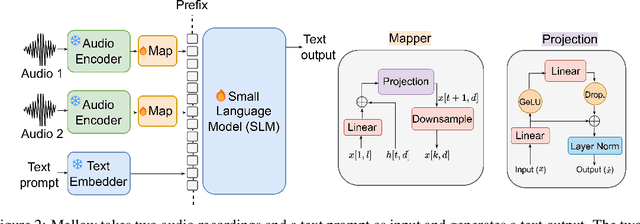
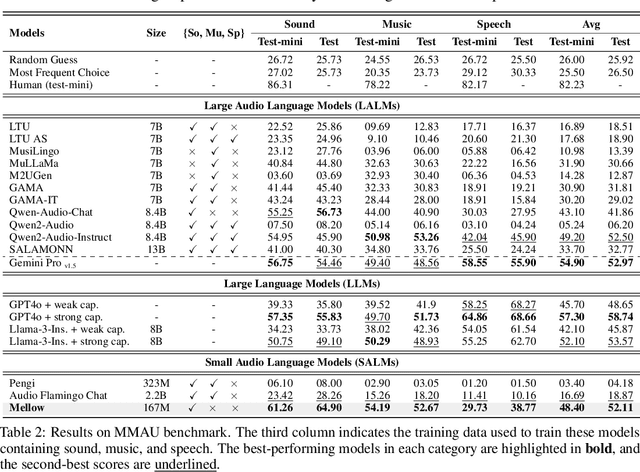
Multimodal Audio-Language Models (ALMs) can understand and reason over both audio and text. Typically, reasoning performance correlates with model size, with the best results achieved by models exceeding 8 billion parameters. However, no prior work has explored enabling small audio-language models to perform reasoning tasks, despite the potential applications for edge devices. To address this gap, we introduce Mellow, a small Audio-Language Model specifically designed for reasoning. Mellow achieves state-of-the-art performance among existing small audio-language models and surpasses several larger models in reasoning capabilities. For instance, Mellow scores 52.11 on MMAU, comparable to SoTA Qwen2 Audio (which scores 52.5) while using 50 times fewer parameters and being trained on 60 times less data (audio hrs). To train Mellow, we introduce ReasonAQA, a dataset designed to enhance audio-grounded reasoning in models. It consists of a mixture of existing datasets (30% of the data) and synthetically generated data (70%). The synthetic dataset is derived from audio captioning datasets, where Large Language Models (LLMs) generate detailed and multiple-choice questions focusing on audio events, objects, acoustic scenes, signal properties, semantics, and listener emotions. To evaluate Mellow's reasoning ability, we benchmark it on a diverse set of tasks, assessing on both in-distribution and out-of-distribution data, including audio understanding, deductive reasoning, and comparative reasoning. Finally, we conduct extensive ablation studies to explore the impact of projection layer choices, synthetic data generation methods, and language model pretraining on reasoning performance. Our training dataset, findings, and baseline pave the way for developing small ALMs capable of reasoning.
ADIFF: Explaining audio difference using natural language
Feb 06, 2025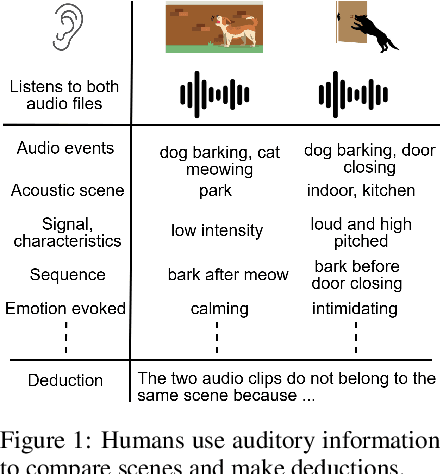
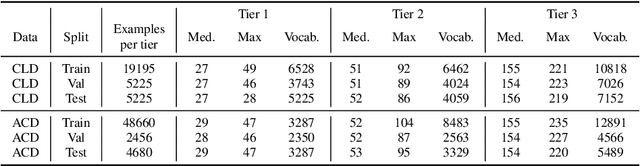

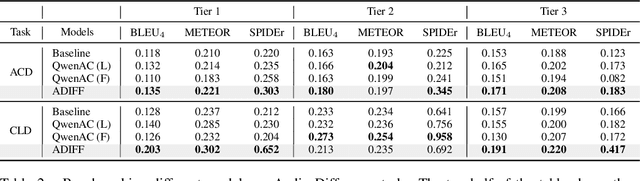
Understanding and explaining differences between audio recordings is crucial for fields like audio forensics, quality assessment, and audio generation. This involves identifying and describing audio events, acoustic scenes, signal characteristics, and their emotional impact on listeners. This paper stands out as the first work to comprehensively study the task of explaining audio differences and then propose benchmark, baselines for the task. First, we present two new datasets for audio difference explanation derived from the AudioCaps and Clotho audio captioning datasets. Using Large Language Models (LLMs), we generate three levels of difference explanations: (1) concise descriptions of audio events and objects, (2) brief sentences about audio events, acoustic scenes, and signal properties, and (3) comprehensive explanations that include semantics and listener emotions. For the baseline, we use prefix tuning where audio embeddings from two audio files are used to prompt a frozen language model. Our empirical analysis and ablation studies reveal that the naive baseline struggles to distinguish perceptually similar sounds and generate detailed tier 3 explanations. To address these limitations, we propose ADIFF, which introduces a cross-projection module, position captioning, and a three-step training process to enhance the model's ability to produce detailed explanations. We evaluate our model using objective metrics and human evaluation and show our model enhancements lead to significant improvements in performance over naive baseline and SoTA Audio-Language Model (ALM) Qwen Audio. Lastly, we conduct multiple ablation studies to study the effects of cross-projection, language model parameters, position captioning, third stage fine-tuning, and present our findings. Our benchmarks, findings, and strong baseline pave the way for nuanced and human-like explanations of audio differences.
MACE: Leveraging Audio for Evaluating Audio Captioning Systems
Nov 05, 2024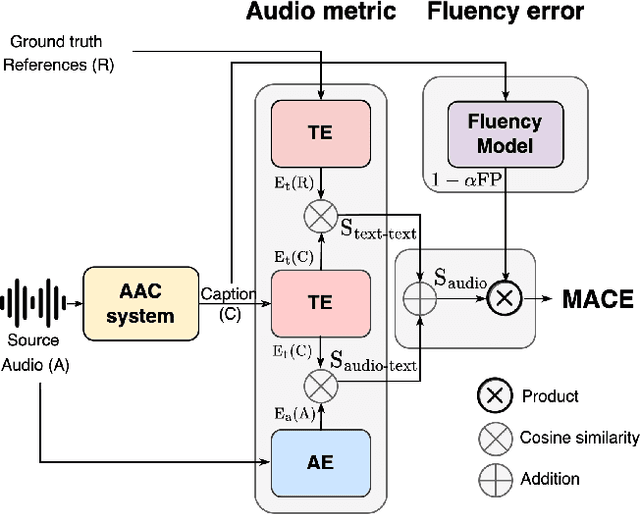
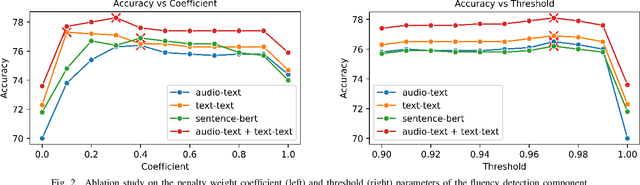
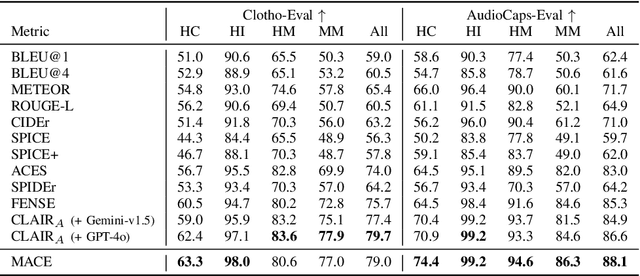
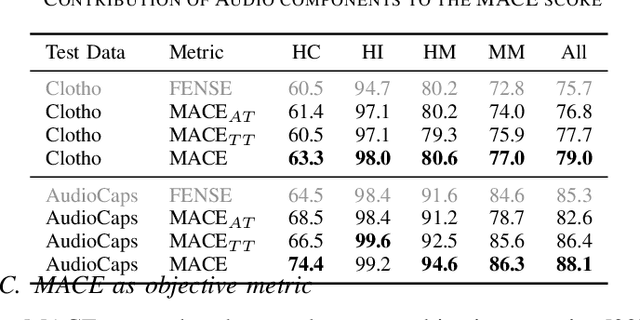
The Automated Audio Captioning (AAC) task aims to describe an audio signal using natural language. To evaluate machine-generated captions, the metrics should take into account audio events, acoustic scenes, paralinguistics, signal characteristics, and other audio information. Traditional AAC evaluation relies on natural language generation metrics like ROUGE and BLEU, image captioning metrics such as SPICE and CIDEr, or Sentence-BERT embedding similarity. However, these metrics only compare generated captions to human references, overlooking the audio signal itself. In this work, we propose MACE (Multimodal Audio-Caption Evaluation), a novel metric that integrates both audio and reference captions for comprehensive audio caption evaluation. MACE incorporates audio information from audio as well as predicted and reference captions and weights it with a fluency penalty. Our experiments demonstrate MACE's superior performance in predicting human quality judgments compared to traditional metrics. Specifically, MACE achieves a 3.28% and 4.36% relative accuracy improvement over the FENSE metric on the AudioCaps-Eval and Clotho-Eval datasets respectively. Moreover, it significantly outperforms all the previous metrics on the audio captioning evaluation task. The metric is opensourced at https://github.com/satvik-dixit/mace
Audio Entailment: Assessing Deductive Reasoning for Audio Understanding
Jul 25, 2024Recent literature uses language to build foundation models for audio. These Audio-Language Models (ALMs) are trained on a vast number of audio-text pairs and show remarkable performance in tasks including Text-to-Audio Retrieval, Captioning, and Question Answering. However, their ability to engage in more complex open-ended tasks, like Interactive Question-Answering, requires proficiency in logical reasoning -- a skill not yet benchmarked. We introduce the novel task of Audio Entailment to evaluate an ALM's deductive reasoning ability. This task assesses whether a text description (hypothesis) of audio content can be deduced from an audio recording (premise), with potential conclusions being entailment, neutral, or contradiction, depending on the sufficiency of the evidence. We create two datasets for this task with audio recordings sourced from two audio captioning datasets -- AudioCaps and Clotho -- and hypotheses generated using Large Language Models (LLMs). We benchmark state-of-the-art ALMs and find deficiencies in logical reasoning with both zero-shot and linear probe evaluations. Finally, we propose "caption-before-reason", an intermediate step of captioning that improves the zero-shot and linear-probe performance of ALMs by an absolute 6% and 3%, respectively.
SELM: Enhancing Speech Emotion Recognition for Out-of-Domain Scenarios
Jul 22, 2024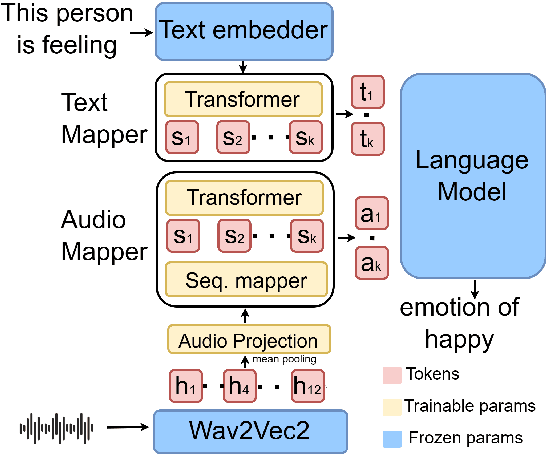
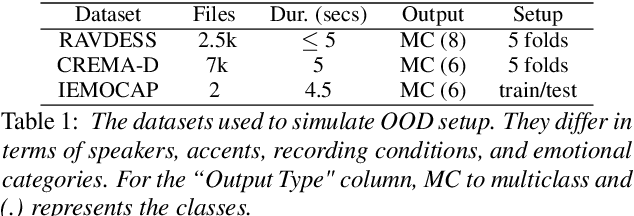

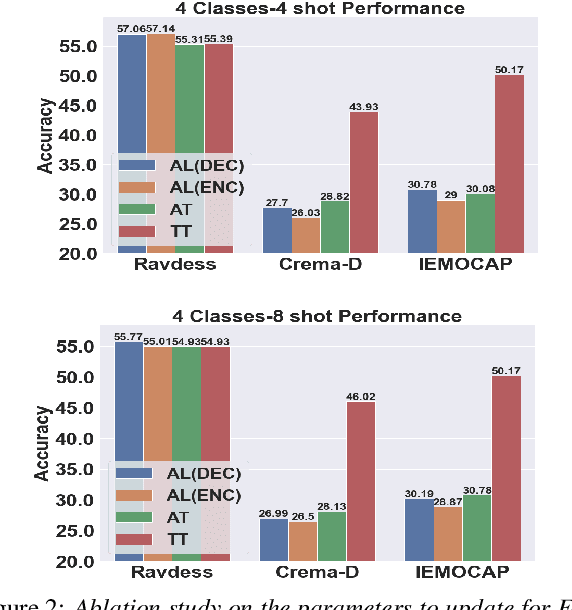
Speech Emotion Recognition (SER) has been traditionally formulated as a classification task. However, emotions are generally a spectrum whose distribution varies from situation to situation leading to poor Out-of-Domain (OOD) performance. We take inspiration from statistical formulation of Automatic Speech Recognition (ASR) and formulate the SER task as generating the most likely sequence of text tokens to infer emotion. The formulation breaks SER into predicting acoustic model features weighted by language model prediction. As an instance of this approach, we present SELM, an audio-conditioned language model for SER that predicts different emotion views. We train SELM on curated speech emotion corpus and test it on three OOD datasets (RAVDESS, CREMAD, IEMOCAP) not used in training. SELM achieves significant improvements over the state-of-the-art baselines, with 17% and 7% relative accuracy gains for RAVDESS and CREMA-D, respectively. Moreover, SELM can further boost its performance by Few-Shot Learning using a few annotated examples. The results highlight the effectiveness of our SER formulation, especially to improve performance in OOD scenarios.
Domain Adaptation for Contrastive Audio-Language Models
Feb 14, 2024Audio-Language Models (ALM) aim to be general-purpose audio models by providing zero-shot capabilities at test time. The zero-shot performance of ALM improves by using suitable text prompts for each domain. The text prompts are usually hand-crafted through an ad-hoc process and lead to a drop in ALM generalization and out-of-distribution performance. Existing approaches to improve domain performance, like few-shot learning or fine-tuning, require access to annotated data and iterations of training. Therefore, we propose a test-time domain adaptation method for ALMs that does not require access to annotations. Our method learns a domain vector by enforcing consistency across augmented views of the testing audio. We extensively evaluate our approach on 12 downstream tasks across domains. With just one example, our domain adaptation method leads to 3.2% (max 8.4%) average zero-shot performance improvement. After adaptation, the model still retains the generalization property of ALMs.