 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Audio Entailment: Assessing Deductive Reasoning for Audio Understanding
Jul 25, 2024Recent literature uses language to build foundation models for audio. These Audio-Language Models (ALMs) are trained on a vast number of audio-text pairs and show remarkable performance in tasks including Text-to-Audio Retrieval, Captioning, and Question Answering. However, their ability to engage in more complex open-ended tasks, like Interactive Question-Answering, requires proficiency in logical reasoning -- a skill not yet benchmarked. We introduce the novel task of Audio Entailment to evaluate an ALM's deductive reasoning ability. This task assesses whether a text description (hypothesis) of audio content can be deduced from an audio recording (premise), with potential conclusions being entailment, neutral, or contradiction, depending on the sufficiency of the evidence. We create two datasets for this task with audio recordings sourced from two audio captioning datasets -- AudioCaps and Clotho -- and hypotheses generated using Large Language Models (LLMs). We benchmark state-of-the-art ALMs and find deficiencies in logical reasoning with both zero-shot and linear probe evaluations. Finally, we propose "caption-before-reason", an intermediate step of captioning that improves the zero-shot and linear-probe performance of ALMs by an absolute 6% and 3%, respectively.
PAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
Prompting Audios Using Acoustic Properties For Emotion Representation
Oct 05, 2023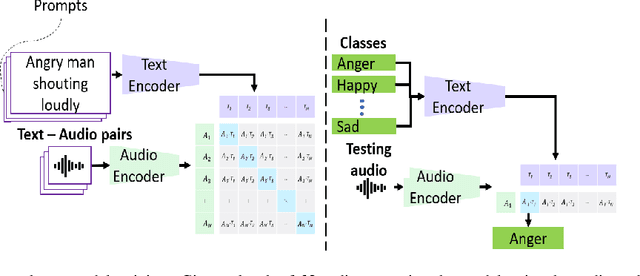
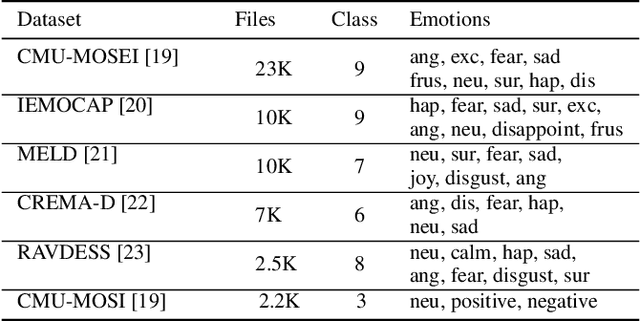
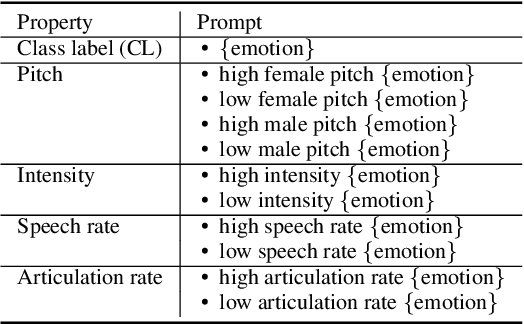
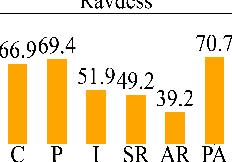
Emotions lie on a continuum, but current models treat emotions as a finite valued discrete variable. This representation does not capture the diversity in the expression of emotion. To better represent emotions we propose the use of natural language descriptions (or prompts). In this work, we address the challenge of automatically generating these prompts and training a model to better learn emotion representations from audio and prompt pairs. We use acoustic properties that are correlated to emotion like pitch, intensity, speech rate, and articulation rate to automatically generate prompts i.e. 'acoustic prompts'. We use a contrastive learning objective to map speech to their respective acoustic prompts. We evaluate our model on Emotion Audio Retrieval and Speech Emotion Recognition. Our results show that the acoustic prompts significantly improve the model's performance in EAR, in various Precision@K metrics. In SER, we observe a 3.8% relative accuracy improvement on the Ravdess dataset.
Training Audio Captioning Models without Audio
Sep 14, 2023Automated Audio Captioning (AAC) is the task of generating natural language descriptions given an audio stream. A typical AAC system requires manually curated training data of audio segments and corresponding text caption annotations. The creation of these audio-caption pairs is costly, resulting in general data scarcity for the task. In this work, we address this major limitation and propose an approach to train AAC systems using only text. Our approach leverages the multimodal space of contrastively trained audio-text models, such as CLAP. During training, a decoder generates captions conditioned on the pretrained CLAP text encoder. During inference, the text encoder is replaced with the pretrained CLAP audio encoder. To bridge the modality gap between text and audio embeddings, we propose the use of noise injection or a learnable adapter, during training. We find that the proposed text-only framework performs competitively with state-of-the-art models trained with paired audio, showing that efficient text-to-audio transfer is possible. Finally, we showcase both stylized audio captioning and caption enrichment while training without audio or human-created text captions.
Natural Language Supervision for General-Purpose Audio Representations
Sep 11, 2023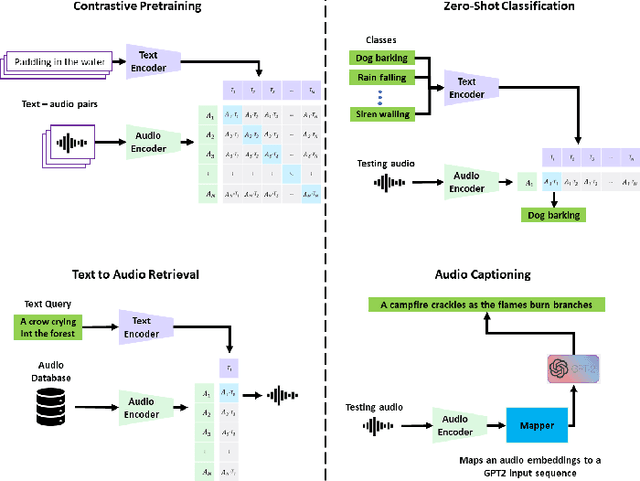
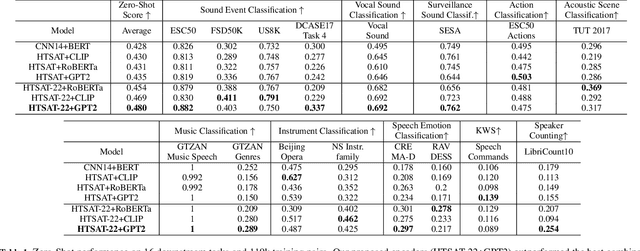
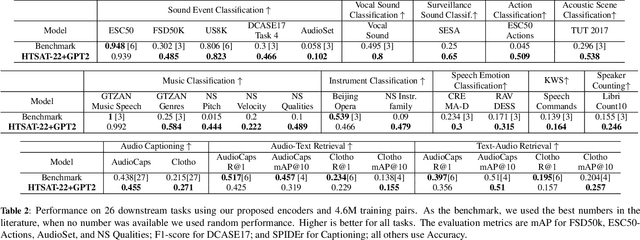
Audio-Language models jointly learn multimodal text and audio representations that enable Zero-Shot inference. Models rely on the encoders to create powerful representations of the input and generalize to multiple tasks ranging from sounds, music, and speech. Although models have achieved remarkable performance, there is still a performance gap with task-specific models. In this paper, we propose a Contrastive Language-Audio Pretraining model that is pretrained with a diverse collection of 4.6M audio-text pairs employing two innovative encoders for Zero-Shot inference. To learn audio representations, we trained an audio encoder on 22 audio tasks, instead of the standard training of sound event classification. To learn language representations, we trained an autoregressive decoder-only model instead of the standard encoder-only models. Then, the audio and language representations are brought into a joint multimodal space using Contrastive Learning. We used our encoders to improve the downstream performance by a margin. We extensively evaluated the generalization of our representations on 26 downstream tasks, the largest in the literature. Our model achieves state of the art results in several tasks leading the way towards general-purpose audio representations.
Pengi: An Audio Language Model for Audio Tasks
May 19, 2023



In the domain of audio processing, Transfer Learning has facilitated the rise of Self-Supervised Learning and Zero-Shot Learning techniques. These approaches have led to the development of versatile models capable of tackling a wide array of tasks, while delivering state-of-the-art performance. However, current models inherently lack the capacity to produce the requisite language for open-ended tasks, such as Audio Captioning or Audio Question & Answering. We introduce Pengi, a novel Audio Language Model that leverages Transfer Learning by framing all audio tasks as text-generation tasks. It takes as input, an audio recording, and text, and generates free-form text as output. The input audio is represented as a sequence of continuous embeddings by an audio encoder. A text encoder does the same for the corresponding text input. Both sequences are combined as a prefix to prompt a pre-trained frozen language model. The unified architecture of Pengi enables open-ended tasks and close-ended tasks without any additional fine-tuning or task-specific extensions. When evaluated on 22 downstream tasks, our approach yields state-of-the-art performance in several of them. Our results show that connecting language models with audio models is a major step towards general-purpose audio understanding
Synergy between human and machine approaches to sound/scene recognition and processing: An overview of ICASSP special session
Feb 24, 2023Machine Listening, as usually formalized, attempts to perform a task that is, from our perspective, fundamentally human-performable, and performed by humans. Current automated models of Machine Listening vary from purely data-driven approaches to approaches imitating human systems. In recent years, the most promising approaches have been hybrid in that they have used data-driven approaches informed by models of the perceptual, cognitive, and semantic processes of the human system. Not only does the guidance provided by models of human perception and domain knowledge enable better, and more generalizable Machine Listening, in the converse, the lessons learned from these models may be used to verify or improve our models of human perception themselves. This paper summarizes advances in the development of such hybrid approaches, ranging from Machine Listening models that are informed by models of peripheral (human) auditory processes, to those that employ or derive semantic information encoded in relations between sounds. The research described herein was presented in a special session on "Synergy between human and machine approaches to sound/scene recognition and processing" at the 2023 ICASSP meeting.
Describing emotions with acoustic property prompts for speech emotion recognition
Nov 14, 2022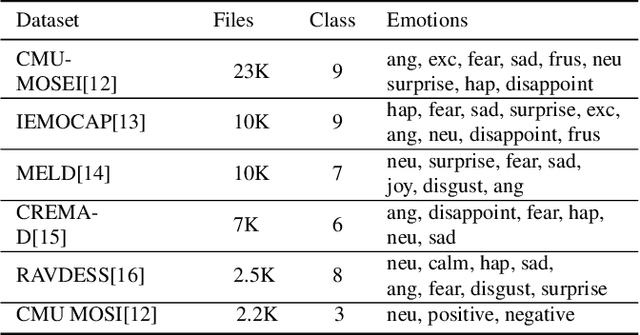
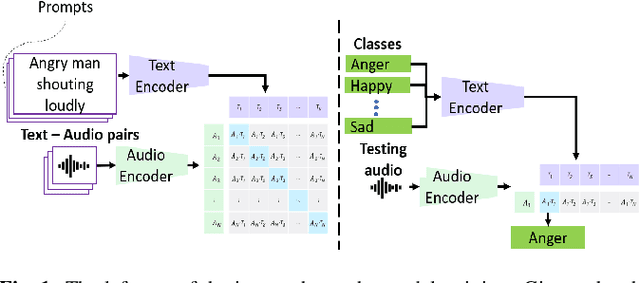
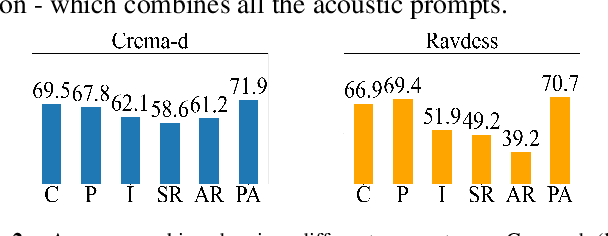
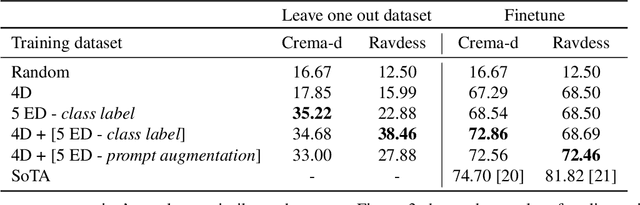
Emotions lie on a broad continuum and treating emotions as a discrete number of classes limits the ability of a model to capture the nuances in the continuum. The challenge is how to describe the nuances of emotions and how to enable a model to learn the descriptions. In this work, we devise a method to automatically create a description (or prompt) for a given audio by computing acoustic properties, such as pitch, loudness, speech rate, and articulation rate. We pair a prompt with its corresponding audio using 5 different emotion datasets. We trained a neural network model using these audio-text pairs. Then, we evaluate the model using one more dataset. We investigate how the model can learn to associate the audio with the descriptions, resulting in performance improvement of Speech Emotion Recognition and Speech Audio Retrieval. We expect our findings to motivate research describing the broad continuum of emotion
Audio Retrieval with WavText5K and CLAP Training
Sep 28, 2022


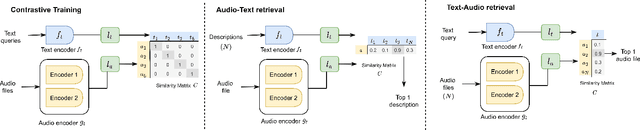
Audio-Text retrieval takes a natural language query to retrieve relevant audio files in a database. Conversely, Text-Audio retrieval takes an audio file as a query to retrieve relevant natural language descriptions. Most of the literature train retrieval systems with one audio captioning dataset, but evaluating the benefit of training with multiple datasets is underexplored. Moreover, retrieval systems have to learn the alignment between elaborated sentences describing audio content of variable length ranging from a few seconds to several minutes. In this work, we propose a new collection of web audio-text pairs and a new framework for retrieval. First, we provide a new collection of about five thousand web audio-text pairs that we refer to as WavText5K. When used to train our retrieval system, WavText5K improved performance more than other audio captioning datasets. Second, our framework learns to connect language and audio content by using a text encoder, two audio encoders, and a contrastive learning objective. Combining both audio encoders helps to process variable length audio. The two contributions beat state of the art performance for AudioCaps and Clotho on Text-Audio retrieval by a relative 2% and 16%, and Audio-Text retrieval by 6% and 23%.