 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024



While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024

We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
Prompting Audios Using Acoustic Properties For Emotion Representation
Oct 05, 2023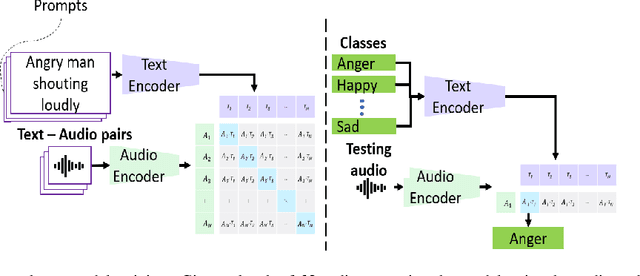
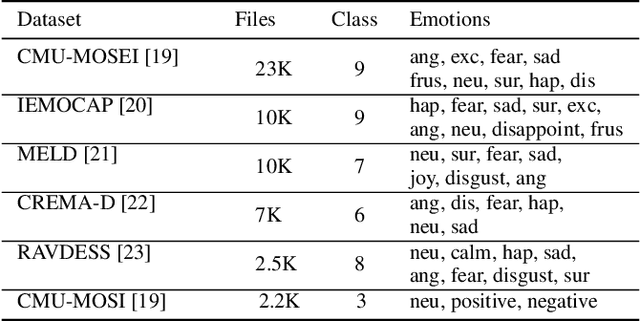
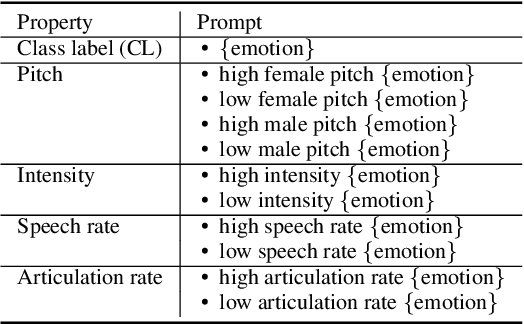
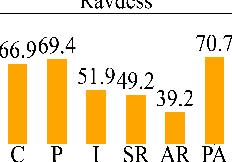
Emotions lie on a continuum, but current models treat emotions as a finite valued discrete variable. This representation does not capture the diversity in the expression of emotion. To better represent emotions we propose the use of natural language descriptions (or prompts). In this work, we address the challenge of automatically generating these prompts and training a model to better learn emotion representations from audio and prompt pairs. We use acoustic properties that are correlated to emotion like pitch, intensity, speech rate, and articulation rate to automatically generate prompts i.e. 'acoustic prompts'. We use a contrastive learning objective to map speech to their respective acoustic prompts. We evaluate our model on Emotion Audio Retrieval and Speech Emotion Recognition. Our results show that the acoustic prompts significantly improve the model's performance in EAR, in various Precision@K metrics. In SER, we observe a 3.8% relative accuracy improvement on the Ravdess dataset.
Training Audio Captioning Models without Audio
Sep 14, 2023Automated Audio Captioning (AAC) is the task of generating natural language descriptions given an audio stream. A typical AAC system requires manually curated training data of audio segments and corresponding text caption annotations. The creation of these audio-caption pairs is costly, resulting in general data scarcity for the task. In this work, we address this major limitation and propose an approach to train AAC systems using only text. Our approach leverages the multimodal space of contrastively trained audio-text models, such as CLAP. During training, a decoder generates captions conditioned on the pretrained CLAP text encoder. During inference, the text encoder is replaced with the pretrained CLAP audio encoder. To bridge the modality gap between text and audio embeddings, we propose the use of noise injection or a learnable adapter, during training. We find that the proposed text-only framework performs competitively with state-of-the-art models trained with paired audio, showing that efficient text-to-audio transfer is possible. Finally, we showcase both stylized audio captioning and caption enrichment while training without audio or human-created text captions.
Natural Language Supervision for General-Purpose Audio Representations
Sep 11, 2023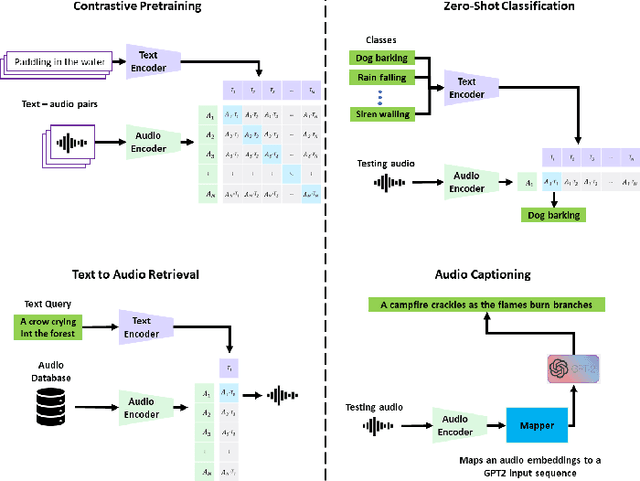
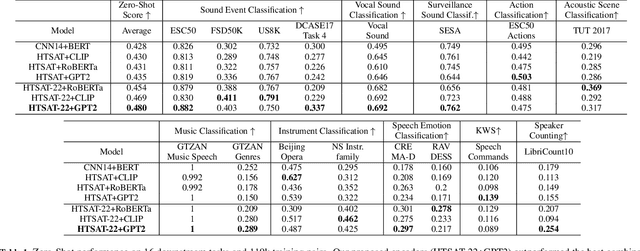
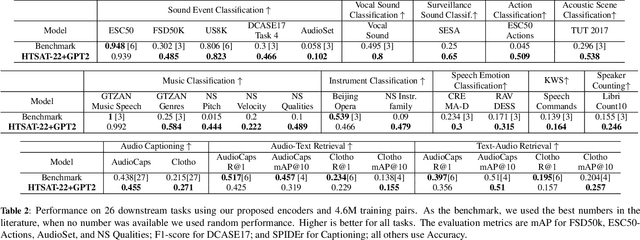
Audio-Language models jointly learn multimodal text and audio representations that enable Zero-Shot inference. Models rely on the encoders to create powerful representations of the input and generalize to multiple tasks ranging from sounds, music, and speech. Although models have achieved remarkable performance, there is still a performance gap with task-specific models. In this paper, we propose a Contrastive Language-Audio Pretraining model that is pretrained with a diverse collection of 4.6M audio-text pairs employing two innovative encoders for Zero-Shot inference. To learn audio representations, we trained an audio encoder on 22 audio tasks, instead of the standard training of sound event classification. To learn language representations, we trained an autoregressive decoder-only model instead of the standard encoder-only models. Then, the audio and language representations are brought into a joint multimodal space using Contrastive Learning. We used our encoders to improve the downstream performance by a margin. We extensively evaluated the generalization of our representations on 26 downstream tasks, the largest in the literature. Our model achieves state of the art results in several tasks leading the way towards general-purpose audio representations.
Pengi: An Audio Language Model for Audio Tasks
May 19, 2023



In the domain of audio processing, Transfer Learning has facilitated the rise of Self-Supervised Learning and Zero-Shot Learning techniques. These approaches have led to the development of versatile models capable of tackling a wide array of tasks, while delivering state-of-the-art performance. However, current models inherently lack the capacity to produce the requisite language for open-ended tasks, such as Audio Captioning or Audio Question & Answering. We introduce Pengi, a novel Audio Language Model that leverages Transfer Learning by framing all audio tasks as text-generation tasks. It takes as input, an audio recording, and text, and generates free-form text as output. The input audio is represented as a sequence of continuous embeddings by an audio encoder. A text encoder does the same for the corresponding text input. Both sequences are combined as a prefix to prompt a pre-trained frozen language model. The unified architecture of Pengi enables open-ended tasks and close-ended tasks without any additional fine-tuning or task-specific extensions. When evaluated on 22 downstream tasks, our approach yields state-of-the-art performance in several of them. Our results show that connecting language models with audio models is a major step towards general-purpose audio understanding
Real-Time Audio-Visual End-to-End Speech Enhancement
Mar 13, 2023


Audio-visual speech enhancement (AV-SE) methods utilize auxiliary visual cues to enhance speakers' voices. Therefore, technically they should be able to outperform the audio-only speech enhancement (SE) methods. However, there are few works in the literature on an AV-SE system that can work in real time on a CPU. In this paper, we propose a low-latency real-time audio-visual end-to-end enhancement (AV-E3Net) model based on the recently proposed end-to-end enhancement network (E3Net). Our main contribution includes two aspects: 1) We employ a dense connection module to solve the performance degradation caused by the deep model structure. This module significantly improves the model's performance on the AV-SE task. 2) We propose a multi-stage gating-and-summation (GS) fusion module to merge audio and visual cues. Our results show that the proposed model provides better perceptual quality and intelligibility than the baseline E3net model with a negligible computational cost increase.
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
Mar 07, 2023We propose a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis. Specifically, we extend VALL-E and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker's voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates the foreign accent problems, which can be controlled by a language ID. Audio samples are available at \url{https://aka.ms/vallex}.
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Jan 05, 2023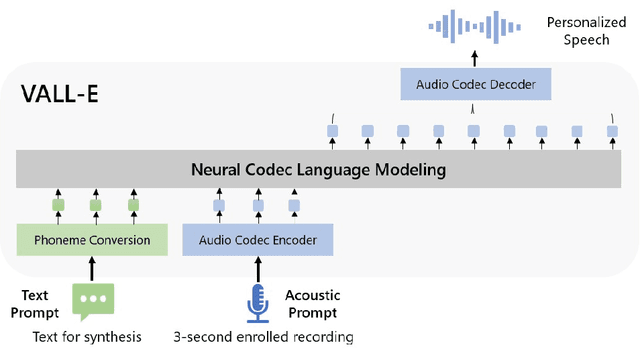

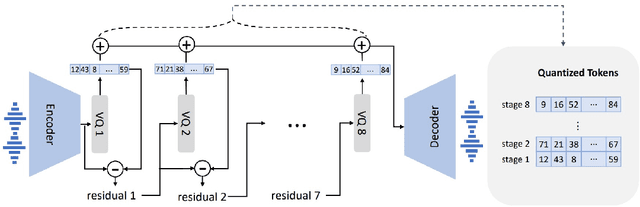
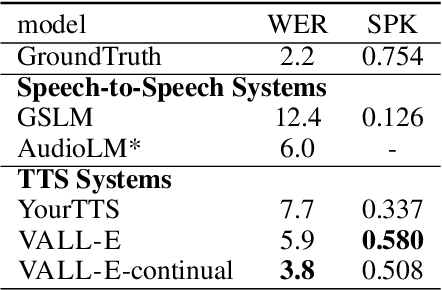
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
Learning to mask: Towards generalized face forgery detection
Dec 29, 2022Generalizability to unseen forgery types is crucial for face forgery detectors. Recent works have made significant progress in terms of generalization by synthetic forgery data augmentation. In this work, we explore another path for improving the generalization. Our goal is to reduce the features that are easy to learn in the training phase, so as to reduce the risk of overfitting on specific forgery types. Specifically, in our method, a teacher network takes as input the face images and generates an attention map of the deep features by a diverse multihead attention ViT. The attention map is used to guide a student network to focus on the low-attended features by reducing the highly-attended deep features. A deep feature mixup strategy is also proposed to synthesize forgeries in the feature domain. Experiments demonstrate that, without data augmentation, our method is able to achieve promising performances on unseen forgeries and highly compressed data.