 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Measurements of Voice Quality
Oct 12, 2024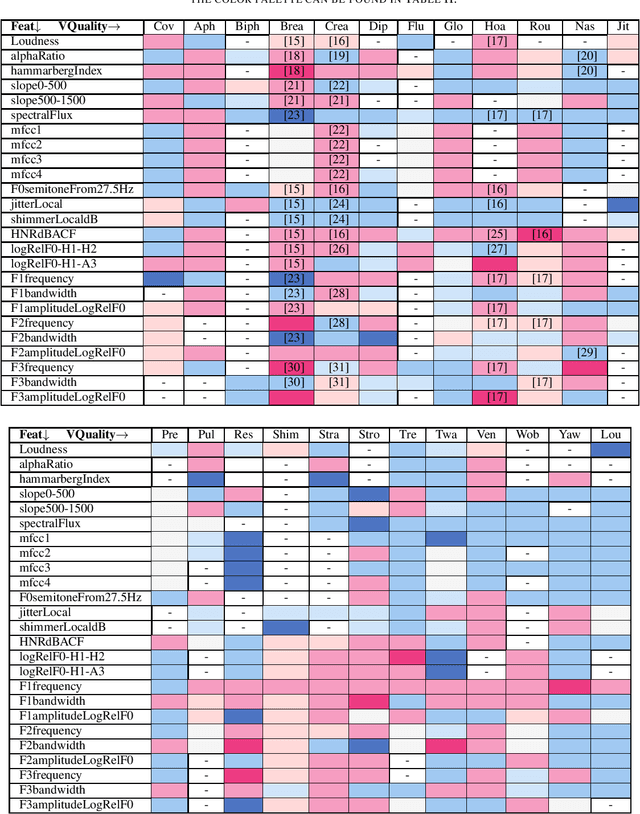
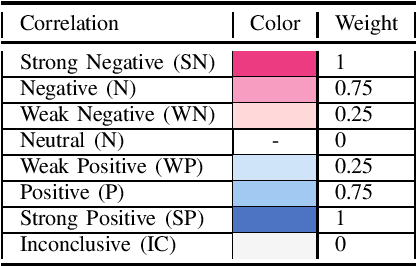
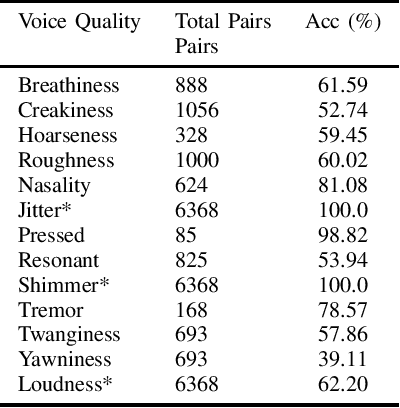
The quality of human voice plays an important role across various fields like music, speech therapy, and communication, yet it lacks a universally accepted, objective definition. Instead, voice quality is referred to using subjective descriptors like "rough", "breathy" etc. Despite this subjectivity, extensive research across disciplines has linked these voice qualities to specific information about the speaker, such as health, physiological traits, and others. Current machine learning approaches for voice profiling rely on data-driven analysis without fully incorporating these established correlations, due to their qualitative nature. This paper aims to objectively quantify voice quality by synthesizing formulaic representations from past findings that correlate voice qualities to signal-processing metrics. We introduce formulae for 24 voice sub-qualities based on 25 signal properties, grounded in scientific literature. These formulae are tested against datasets with subjectively labeled voice qualities, demonstrating their validity.
PDAF: A Phonetic Debiasing Attention Framework For Speaker Verification
Sep 09, 2024

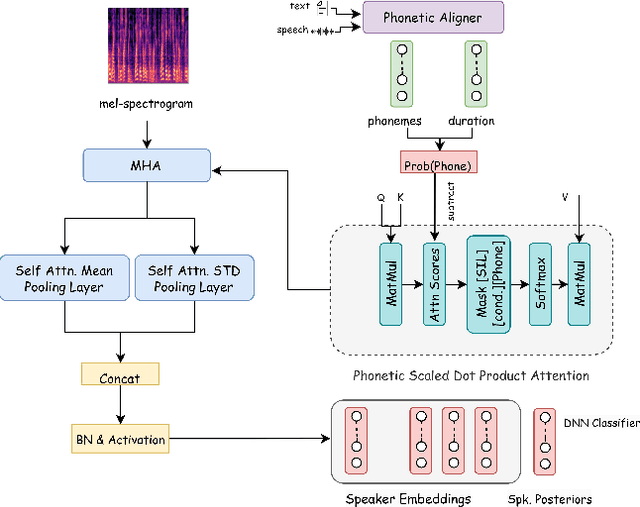

Speaker verification systems are crucial for authenticating identity through voice. Traditionally, these systems focus on comparing feature vectors, overlooking the speech's content. However, this paper challenges this by highlighting the importance of phonetic dominance, a measure of the frequency or duration of phonemes, as a crucial cue in speaker verification. A novel Phoneme Debiasing Attention Framework (PDAF) is introduced, integrating with existing attention frameworks to mitigate biases caused by phonetic dominance. PDAF adjusts the weighting for each phoneme and influences feature extraction, allowing for a more nuanced analysis of speech. This approach paves the way for more accurate and reliable identity authentication through voice. Furthermore, by employing various weighting strategies, we evaluate the influence of phonetic features on the efficacy of the speaker verification system.
Speech vs. Transcript: Does It Matter for Human Annotators in Speech Summarization?
Aug 12, 2024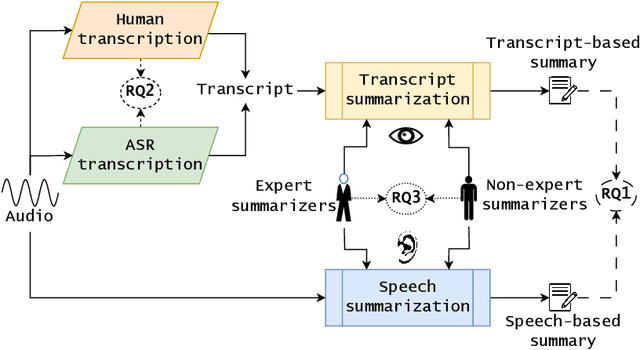
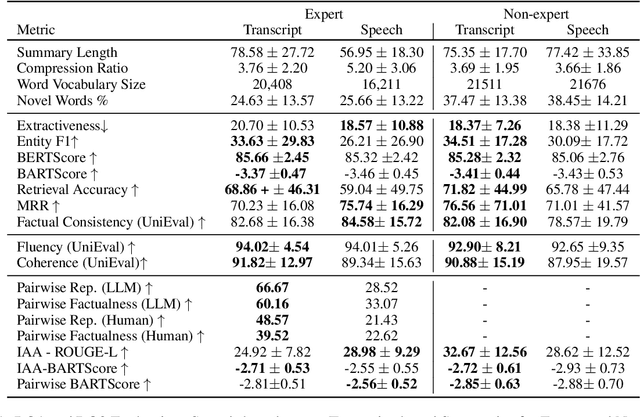

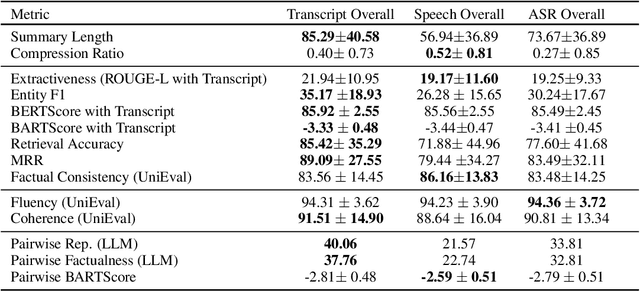
Reference summaries for abstractive speech summarization require human annotation, which can be performed by listening to an audio recording or by reading textual transcripts of the recording. In this paper, we examine whether summaries based on annotators listening to the recordings differ from those based on annotators reading transcripts. Using existing intrinsic evaluation based on human evaluation, automatic metrics, LLM-based evaluation, and a retrieval-based reference-free method. We find that summaries are indeed different based on the source modality, and that speech-based summaries are more factually consistent and information-selective than transcript-based summaries. Meanwhile, transcript-based summaries are impacted by recognition errors in the source, and expert-written summaries are more informative and reliable. We make all the collected data and analysis code public(https://github.com/cmu-mlsp/interview_humanssum) to facilitate the reproduction of our work and advance research in this area.
SELM: Enhancing Speech Emotion Recognition for Out-of-Domain Scenarios
Jul 22, 2024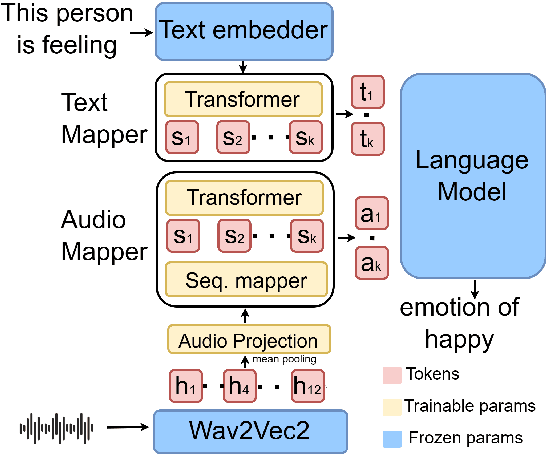
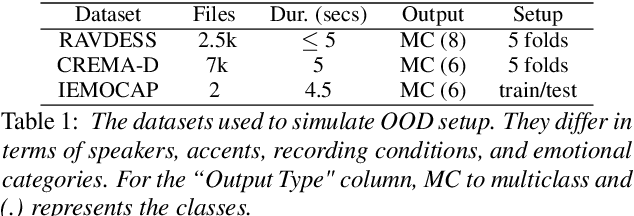

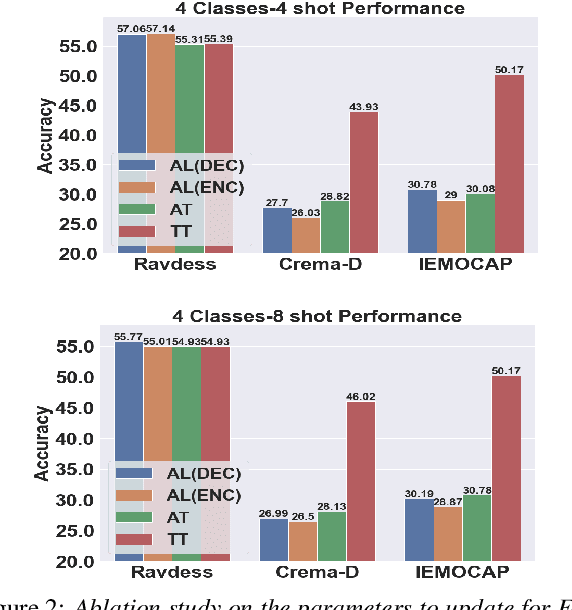
Speech Emotion Recognition (SER) has been traditionally formulated as a classification task. However, emotions are generally a spectrum whose distribution varies from situation to situation leading to poor Out-of-Domain (OOD) performance. We take inspiration from statistical formulation of Automatic Speech Recognition (ASR) and formulate the SER task as generating the most likely sequence of text tokens to infer emotion. The formulation breaks SER into predicting acoustic model features weighted by language model prediction. As an instance of this approach, we present SELM, an audio-conditioned language model for SER that predicts different emotion views. We train SELM on curated speech emotion corpus and test it on three OOD datasets (RAVDESS, CREMAD, IEMOCAP) not used in training. SELM achieves significant improvements over the state-of-the-art baselines, with 17% and 7% relative accuracy gains for RAVDESS and CREMA-D, respectively. Moreover, SELM can further boost its performance by Few-Shot Learning using a few annotated examples. The results highlight the effectiveness of our SER formulation, especially to improve performance in OOD scenarios.
On the Evaluation of Speech Foundation Models for Spoken Language Understanding
Jun 14, 2024The Spoken Language Understanding Evaluation (SLUE) suite of benchmark tasks was recently introduced to address the need for open resources and benchmarking of complex spoken language understanding (SLU) tasks, including both classification and sequence generation tasks, on natural speech. The benchmark has demonstrated preliminary success in using pre-trained speech foundation models (SFM) for these SLU tasks. However, the community still lacks a fine-grained understanding of the comparative utility of different SFMs. Inspired by this, we ask: which SFMs offer the most benefits for these complex SLU tasks, and what is the most effective approach for incorporating these SFMs? To answer this, we perform an extensive evaluation of multiple supervised and self-supervised SFMs using several evaluation protocols: (i) frozen SFMs with a lightweight prediction head, (ii) frozen SFMs with a complex prediction head, and (iii) fine-tuned SFMs with a lightweight prediction head. Although the supervised SFMs are pre-trained on much more speech recognition data (with labels), they do not always outperform self-supervised SFMs; the latter tend to perform at least as well as, and sometimes better than, supervised SFMs, especially on the sequence generation tasks in SLUE. While there is no universally optimal way of incorporating SFMs, the complex prediction head gives the best performance for most tasks, although it increases the inference time. We also introduce an open-source toolkit and performance leaderboard, SLUE-PERB, for these tasks and modeling strategies.
Prompting Audios Using Acoustic Properties For Emotion Representation
Oct 05, 2023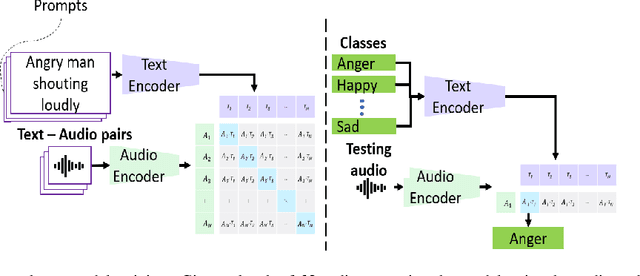
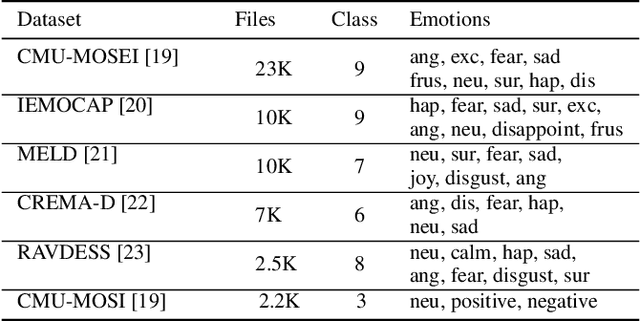
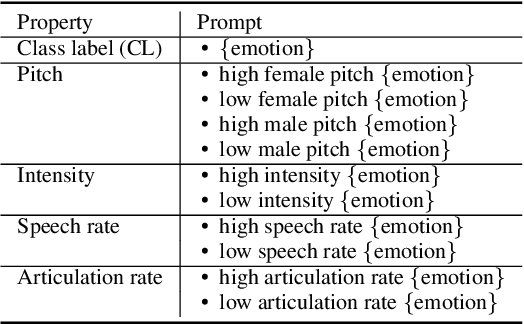
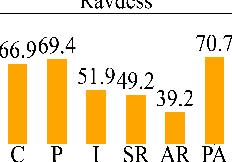
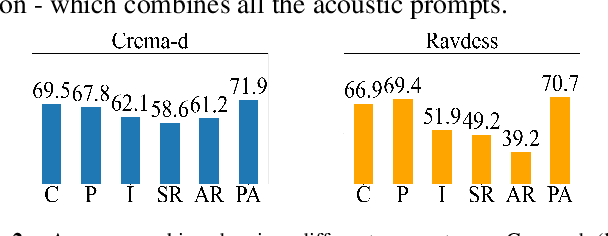
Emotions lie on a continuum, but current models treat emotions as a finite valued discrete variable. This representation does not capture the diversity in the expression of emotion. To better represent emotions we propose the use of natural language descriptions (or prompts). In this work, we address the challenge of automatically generating these prompts and training a model to better learn emotion representations from audio and prompt pairs. We use acoustic properties that are correlated to emotion like pitch, intensity, speech rate, and articulation rate to automatically generate prompts i.e. 'acoustic prompts'. We use a contrastive learning objective to map speech to their respective acoustic prompts. We evaluate our model on Emotion Audio Retrieval and Speech Emotion Recognition. Our results show that the acoustic prompts significantly improve the model's performance in EAR, in various Precision@K metrics. In SER, we observe a 3.8% relative accuracy improvement on the Ravdess dataset.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023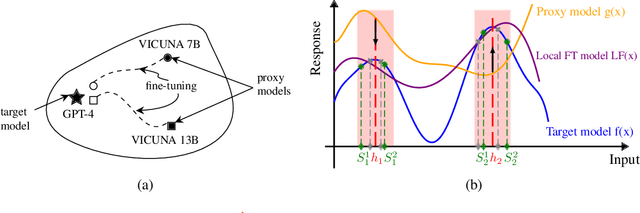

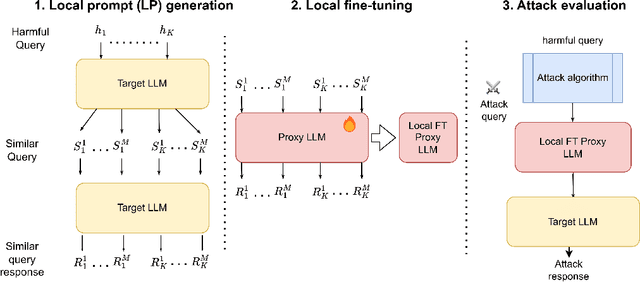

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.
Describing emotions with acoustic property prompts for speech emotion recognition
Nov 14, 2022
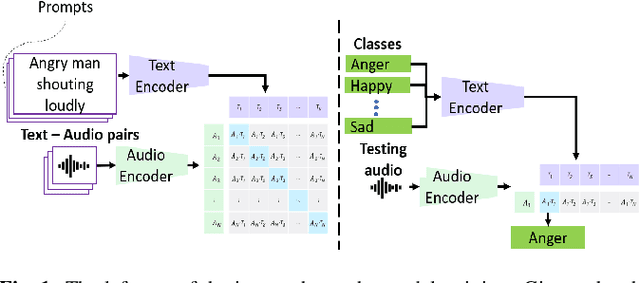
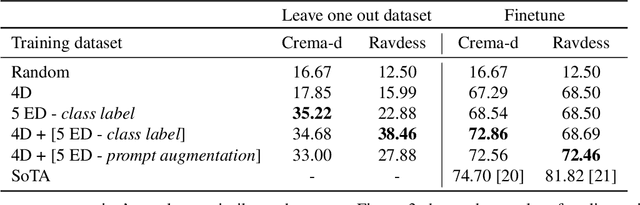
Emotions lie on a broad continuum and treating emotions as a discrete number of classes limits the ability of a model to capture the nuances in the continuum. The challenge is how to describe the nuances of emotions and how to enable a model to learn the descriptions. In this work, we devise a method to automatically create a description (or prompt) for a given audio by computing acoustic properties, such as pitch, loudness, speech rate, and articulation rate. We pair a prompt with its corresponding audio using 5 different emotion datasets. We trained a neural network model using these audio-text pairs. Then, we evaluate the model using one more dataset. We investigate how the model can learn to associate the audio with the descriptions, resulting in performance improvement of Speech Emotion Recognition and Speech Audio Retrieval. We expect our findings to motivate research describing the broad continuum of emotion
Unifying the Discrete and Continuous Emotion labels for Speech Emotion Recognition
Oct 29, 2022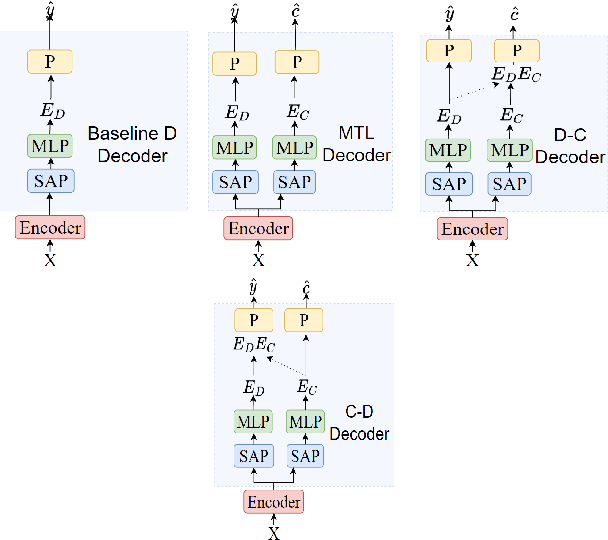
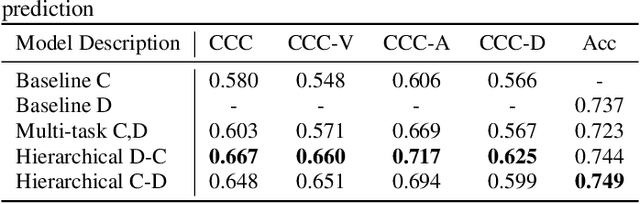
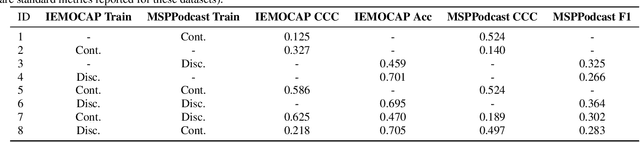
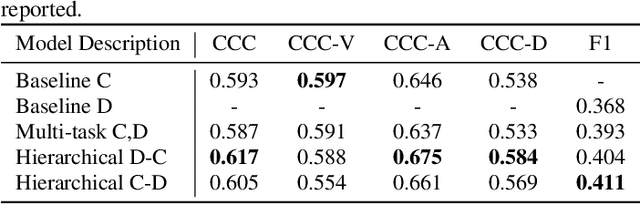
Traditionally, in paralinguistic analysis for emotion detection from speech, emotions have been identified with discrete or dimensional (continuous-valued) labels. Accordingly, models that have been proposed for emotion detection use one or the other of these label types. However, psychologists like Russell and Plutchik have proposed theories and models that unite these views, maintaining that these representations have shared and complementary information. This paper is an attempt to validate these viewpoints computationally. To this end, we propose a model to jointly predict continuous and discrete emotional attributes and show how the relationship between these can be utilized to improve the robustness and performance of emotion recognition tasks. Our approach comprises multi-task and hierarchical multi-task learning frameworks that jointly model the relationships between continuous-valued and discrete emotion labels. Experimental results on two widely used datasets (IEMOCAP and MSPPodcast) for speech-based emotion recognition show that our model results in statistically significant improvements in performance over strong baselines with non-unified approaches. We also demonstrate that using one type of label (discrete or continuous-valued) for training improves recognition performance in tasks that use the other type of label. Experimental results and reasoning for this approach (called the mismatched training approach) are also presented.