 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Quality-Based Localization of Low-Quality Speech and Text-to-Speech Synthesis Artefacts
Jan 29, 2026A large number of works view the automatic assessment of speech from an utterance- or system-level perspective. While such approaches are good in judging overall quality, they cannot adequately explain why a certain score was assigned to an utterance. frame-level scores can provide better interpretability, but models predicting them are harder to tune and regularize since no strong targets are available during training. In this work, we show that utterance-level speech quality predictors can be regularized with a segment-based consistency constraint which notably reduces frame-level stochasticity. We then demonstrate two applications involving frame-level scores: The partial spoof scenario and the detection of synthesis artefacts in two state-of-the-art text-to-speech systems. For the latter, we perform listening tests and confirm that listeners rate segments to be of poor quality more often in the set defined by low frame-level scores than in a random control set.
Synthesizing speech with selected perceptual voice qualities - A case study with creaky voice
Nov 07, 2025The control of perceptual voice qualities in a text-to-speech (TTS) system is of interest for applications where unmanipu- lated and manipulated speech probes can serve to illustrate pho- netic concepts that are otherwise difficult to grasp. Here, we show that a TTS system, that is augmented with a global speaker attribute manipulation block based on normalizing flows1 , is capable of correctly manipulating the non-persistent, localized quality of creaky voice, thus avoiding the necessity of a, typi- cally unreliable, frame-wise creak predictor. Subjective listen- ing tests confirm successful creak manipulation at a slightly re- duced MOS score compared to the original recording.
Towards Frame-level Quality Predictions of Synthetic Speech
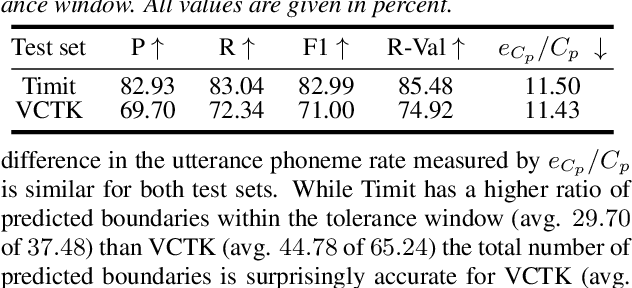
Aug 14, 2025While automatic subjective speech quality assessment has witnessed much progress, an open question is whether an automatic quality assessment at frame resolution is possible. This would be highly desirable, as it adds explainability to the assessment of speech synthesis systems. Here, we take first steps towards this goal by identifying issues of existing quality predictors that prevent sensible frame-level prediction. Further, we define criteria that a frame-level predictor should fulfill. We also suggest a chunk-based processing that avoids the impact of a localized distortion on the score of neighboring frames. Finally, we measure in experiments with localized artificial distortions the localization performance of a set of frame-level quality predictors and show that they can outperform detection performance of human annotations obtained from a crowd-sourced perception experiment.
Speech Synthesis along Perceptual Voice Quality Dimensions
Jan 15, 2025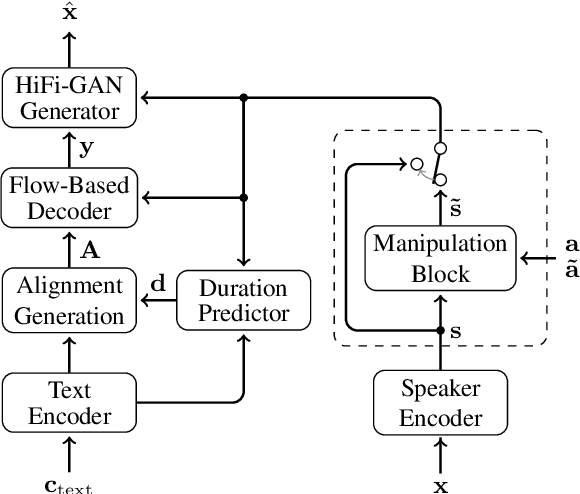
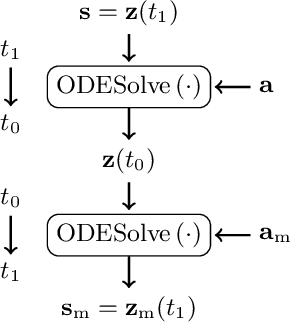
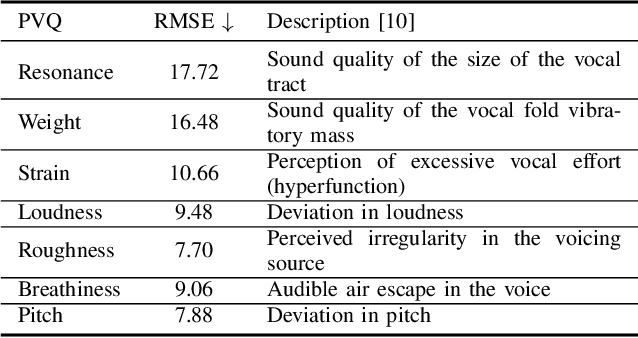

While expressive speech synthesis or voice conversion systems mainly focus on controlling or manipulating abstract prosodic characteristics of speech, such as emotion or accent, we here address the control of perceptual voice qualities (PVQs) recognized by phonetic experts, which are speech properties at a lower level of abstraction. The ability to manipulate PVQs can be a valuable tool for teaching speech pathologists in training or voice actors. In this paper, we integrate a Conditional Continuous-Normalizing-Flow-based method into a Text-to-Speech system to modify perceptual voice attributes on a continuous scale. Unlike previous approaches, our system avoids direct manipulation of acoustic correlates and instead learns from examples. We demonstrate the system's capability by manipulating four voice qualities: Roughness, breathiness, resonance and weight. Phonetic experts evaluated these modifications, both for seen and unseen speaker conditions. The results highlight both the system's strengths and areas for improvement.
Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder
Sep 05, 2024Speech signals encompass various information across multiple levels including content, speaker, and style. Disentanglement of these information, although challenging, is important for applications such as voice conversion. The contrastive predictive coding supported factorized variational autoencoder achieves unsupervised disentanglement of a speech signal into speaker and content embeddings by assuming speaker info to be temporally more stable than content-induced variations. However, this assumption may introduce other temporal stable information into the speaker embeddings, like environment or emotion, which we call style. In this work, we propose a method to further disentangle non-content features into distinct speaker and style features, notably by leveraging readily accessible and well-defined speaker labels without the necessity for style labels. Experimental results validate the proposed method's effectiveness on extracting disentangled features, thereby facilitating speaker, style, or combined speaker-style conversion.
On Feature Importance and Interpretability of Speaker Representations
Oct 19, 2023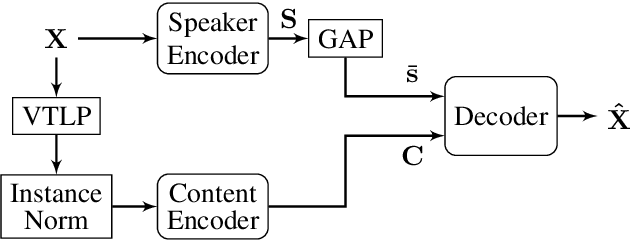
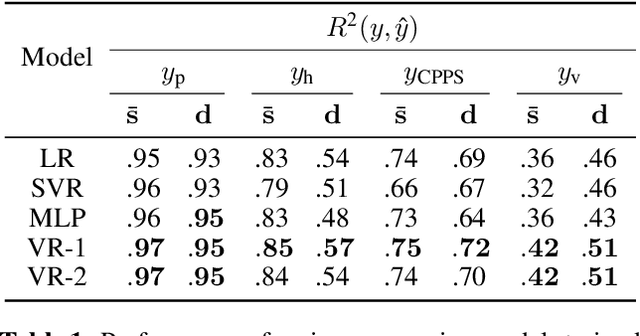
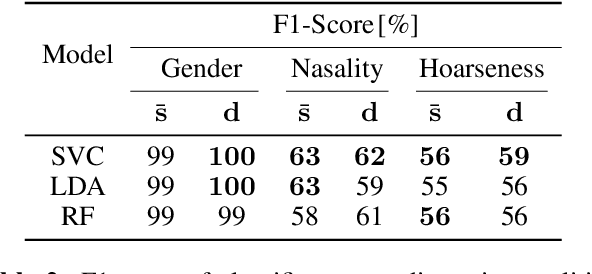

Unsupervised speech disentanglement aims at separating fast varying from slowly varying components of a speech signal. In this contribution, we take a closer look at the embedding vector representing the slowly varying signal components, commonly named the speaker embedding vector. We ask, which properties of a speaker's voice are captured and investigate to which extent do individual embedding vector components sign responsible for them, using the concept of Shapley values. Our findings show that certain speaker-specific acoustic-phonetic properties can be fairly well predicted from the speaker embedding, while the investigated more abstract voice quality features cannot.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023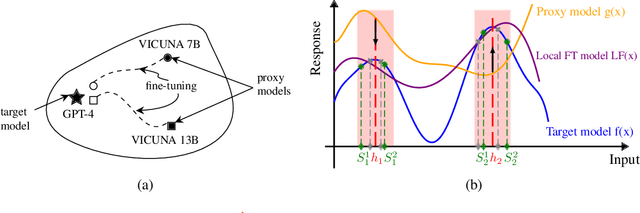

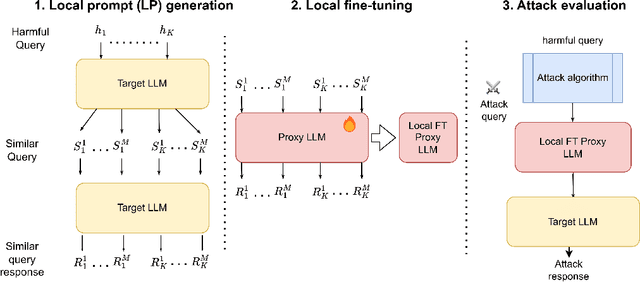

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
Investigating Speaker Embedding Disentanglement on Natural Read Speech
Aug 08, 2023
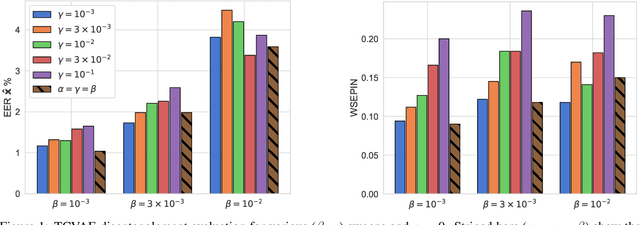
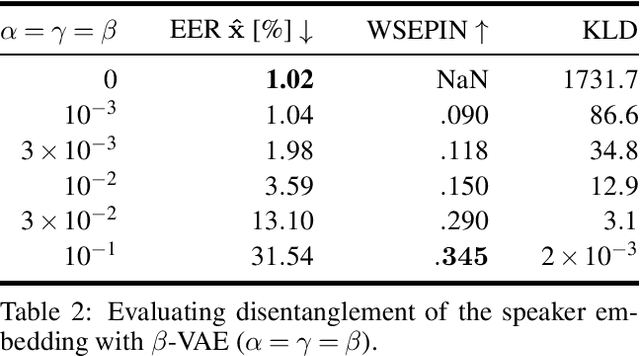
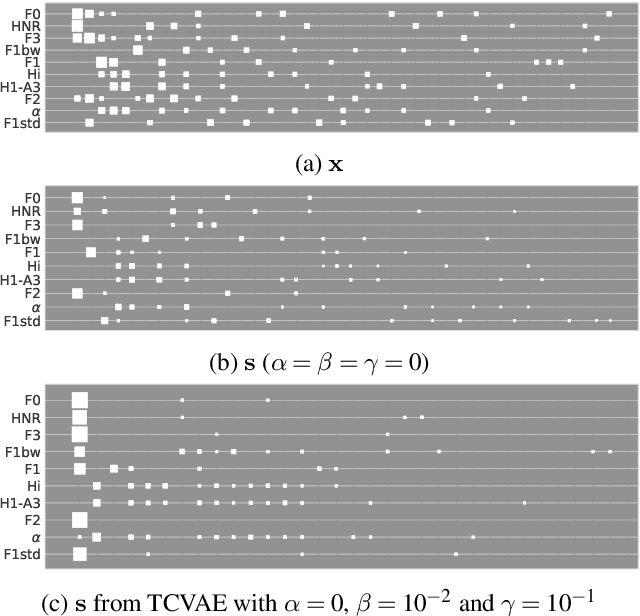
Disentanglement is the task of learning representations that identify and separate factors that explain the variation observed in data. Disentangled representations are useful to increase the generalizability, explainability, and fairness of data-driven models. Only little is known about how well such disentanglement works for speech representations. A major challenge when tackling disentanglement for speech representations are the unknown generative factors underlying the speech signal. In this work, we investigate to what degree speech representations encoding speaker identity can be disentangled. To quantify disentanglement, we identify acoustic features that are highly speaker-variant and can serve as proxies for the factors of variation underlying speech. We find that disentanglement of the speaker embedding is limited when trained with standard objectives promoting disentanglement but can be improved over vanilla representation learning to some extent.
Investigation into Target Speaking Rate Adaptation for Voice Conversion
Sep 05, 2022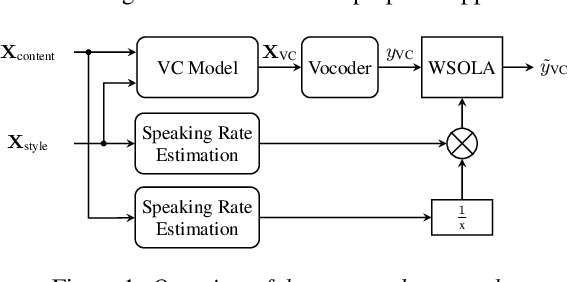

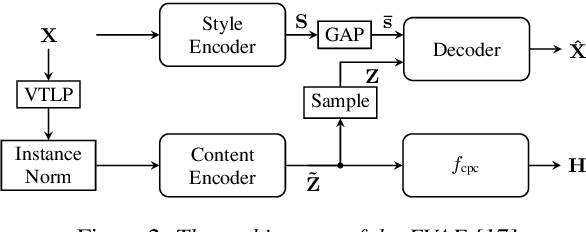
Disentangling speaker and content attributes of a speech signal into separate latent representations followed by decoding the content with an exchanged speaker representation is a popular approach for voice conversion, which can be trained with non-parallel and unlabeled speech data. However, previous approaches perform disentanglement only implicitly via some sort of information bottleneck or normalization, where it is usually hard to find a good trade-off between voice conversion and content reconstruction. Further, previous works usually do not consider an adaptation of the speaking rate to the target speaker or they put some major restrictions to the data or use case. Therefore, the contribution of this work is two-fold. First, we employ an explicit and fully unsupervised disentanglement approach, which has previously only been used for representation learning, and show that it allows to obtain both superior voice conversion and content reconstruction. Second, we investigate simple and generic approaches to linearly adapt the length of a speech signal, and hence the speaking rate, to a target speaker and show that the proposed adaptation allows to increase the speaking rate similarity with respect to the target speaker.