 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Pooling Strategies for Training-Free Anomalous Sound Detection with Self-Supervised Audio Embeddings
Mar 04, 2026Training-free anomalous sound detection (ASD) based on pre-trained audio embedding models has recently garnered significant attention, as it enables the detection of anomalous sounds using only normal reference data while offering improved robustness under domain shifts. However, existing embedding-based approaches almost exclusively rely on temporal mean pooling, while alternative pooling strategies have so far only been explored for spectrogram-based representations. Consequently, the role of temporal pooling in training-free ASD with pre-trained embeddings remains insufficiently understood. In this paper, we present a systematic evaluation of temporal pooling strategies across multiple state-of-the-art audio embedding models. We propose relative deviation pooling (RDP), an adaptive pooling method that emphasizes informative temporal deviations, and introduce a hybrid pooling strategy that combines RDP with generalized mean pooling. Experiments on five benchmark datasets demonstrate that the proposed methods consistently outperform mean pooling and achieve state-of-the-art performance for training-free ASD, including results that surpass all previously reported trained systems and ensembles on the DCASE2025 ASD dataset.
How Much Does Machine Identity Matter in Anomalous Sound Detection at Test Time?
Feb 18, 2026Anomalous sound detection (ASD) benchmarks typically assume that the identity of the monitored machine is known at test time and that recordings are evaluated in a machine-wise manner. However, in realistic monitoring scenarios with multiple known machines operating concurrently, test recordings may not be reliably attributable to a specific machine, and requiring machine identity imposes deployment constraints such as dedicated sensors per machine. To reveal performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, we consider a minimal modification of the ASD evaluation protocol in which test recordings from multiple machines are merged and evaluated jointly without access to machine identity at inference time. Training data and evaluation metrics remain unchanged, and machine identity labels are used only for post hoc evaluation. Experiments with representative ASD methods show that relaxing this assumption reveals performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, and that these degradations are strongly related to implicit machine identification accuracy.
Population-Aligned Audio Reproduction With LLM-Based Equalizers
Jan 14, 2026Conventional audio equalization is a static process that requires manual and cumbersome adjustments to adapt to changing listening contexts (e.g., mood, location, or social setting). In this paper, we introduce a Large Language Model (LLM)-based alternative that maps natural language text prompts to equalization settings. This enables a conversational approach to sound system control. By utilizing data collected from a controlled listening experiment, our models exploit in-context learning and parameter-efficient fine-tuning techniques to reliably align with population-preferred equalization settings. Our evaluation methods, which leverage distributional metrics that capture users' varied preferences, show statistically significant improvements in distributional alignment over random sampling and static preset baselines. These results indicate that LLMs could function as "artificial equalizers," contributing to the development of more accessible, context-aware, and expert-level audio tuning methods.
LibriVAD: A Scalable Open Dataset with Deep Learning Benchmarks for Voice Activity Detection
Dec 19, 2025Robust Voice Activity Detection (VAD) remains a challenging task, especially under noisy, diverse, and unseen acoustic conditions. Beyond algorithmic development, a key limitation in advancing VAD research is the lack of large-scale, systematically controlled, and publicly available datasets. To address this, we introduce LibriVAD - a scalable open-source dataset derived from LibriSpeech and augmented with diverse real-world and synthetic noise sources. LibriVAD enables systematic control over speech-to-noise ratio, silence-to-speech ratio (SSR), and noise diversity, and is released in three sizes (15 GB, 150 GB, and 1.5 TB) with two variants (LibriVAD-NonConcat and LibriVAD-Concat) to support different experimental setups. We benchmark multiple feature-model combinations, including waveform, Mel-Frequency Cepstral Coefficients (MFCC), and Gammatone filter bank cepstral coefficients, and introduce the Vision Transformer (ViT) architecture for VAD. Our experiments show that ViT with MFCC features consistently outperforms established VAD models such as boosted deep neural network and convolutional long short-term memory deep neural network across seen, unseen, and out-of-distribution (OOD) conditions, including evaluation on the real-world VOiCES dataset. We further analyze the impact of dataset size and SSR on model generalization, experimentally showing that scaling up dataset size and balancing SSR noticeably and consistently enhance VAD performance under OOD conditions. All datasets, trained models, and code are publicly released to foster reproducibility and accelerate progress in VAD research.
Exploring Resolution-Wise Shared Attention in Hybrid Mamba-U-Nets for Improved Cross-Corpus Speech Enhancement
Oct 02, 2025Recent advances in speech enhancement have shown that models combining Mamba and attention mechanisms yield superior cross-corpus generalization performance. At the same time, integrating Mamba in a U-Net structure has yielded state-of-the-art enhancement performance, while reducing both model size and computational complexity. Inspired by these insights, we propose RWSA-MambaUNet, a novel and efficient hybrid model combining Mamba and multi-head attention in a U-Net structure for improved cross-corpus performance. Resolution-wise shared attention (RWSA) refers to layerwise attention-sharing across corresponding time- and frequency resolutions. Our best-performing RWSA-MambaUNet model achieves state-of-the-art generalization performance on two out-of-domain test sets. Notably, our smallest model surpasses all baselines on the out-of-domain DNS 2020 test set in terms of PESQ, SSNR, and ESTOI, and on the out-of-domain EARS-WHAM_v2 test set in terms of SSNR, ESTOI, and SI-SDR, while using less than half the model parameters and a fraction of the FLOPs.
DSpAST: Disentangled Representations for Spatial Audio Reasoning with Large Language Models
Sep 17, 2025Reasoning about spatial audio with large language models requires a spatial audio encoder as an acoustic front-end to obtain audio embeddings for further processing. Such an encoder needs to capture all information required to detect the type of sound events, as well as the direction and distance of their corresponding sources. Accomplishing this with a single audio encoder is demanding as the information required for each of these tasks is mostly independent of each other. As a result, the performance obtained with a single encoder is often worse than when using task-specific audio encoders. In this work, we present DSpAST, a novel audio encoder based on SpatialAST that learns disentangled representations of spatial audio while having only 0.2% additional parameters. Experiments on SpatialSoundQA with the spatial audio reasoning system BAT demonstrate that DSpAST significantly outperforms SpatialAST.
Learning Robust Spatial Representations from Binaural Audio through Feature Distillation
Aug 28, 2025Recently, deep representation learning has shown strong performance in multiple audio tasks. However, its use for learning spatial representations from multichannel audio is underexplored. We investigate the use of a pretraining stage based on feature distillation to learn a robust spatial representation of binaural speech without the need for data labels. In this framework, spatial features are computed from clean binaural speech samples to form prediction labels. These clean features are then predicted from corresponding augmented speech using a neural network. After pretraining, we throw away the spatial feature predictor and use the learned encoder weights to initialize a DoA estimation model which we fine-tune for DoA estimation. Our experiments demonstrate that the pretrained models show improved performance in noisy and reverberant environments after fine-tuning for direction-of-arrival estimation, when compared to fully supervised models and classic signal processing methods.
MambAttention: Mamba with Multi-Head Attention for Generalizable Single-Channel Speech Enhancement
Jul 01, 2025



With the advent of new sequence models like Mamba and xLSTM, several studies have shown that these models match or outperform state-of-the-art models in single-channel speech enhancement, automatic speech recognition, and self-supervised audio representation learning. However, prior research has demonstrated that sequence models like LSTM and Mamba tend to overfit to the training set. To address this issue, previous works have shown that adding self-attention to LSTMs substantially improves generalization performance for single-channel speech enhancement. Nevertheless, neither the concept of hybrid Mamba and time-frequency attention models nor their generalization performance have been explored for speech enhancement. In this paper, we propose a novel hybrid architecture, MambAttention, which combines Mamba and shared time- and frequency-multi-head attention modules for generalizable single-channel speech enhancement. To train our model, we introduce VoiceBank+Demand Extended (VB-DemandEx), a dataset inspired by VoiceBank+Demand but with more challenging noise types and lower signal-to-noise ratios. Trained on VB-DemandEx, our proposed MambAttention model significantly outperforms existing state-of-the-art LSTM-, xLSTM-, Mamba-, and Conformer-based systems of similar complexity across all reported metrics on two out-of-domain datasets: DNS 2020 and EARS-WHAM_v2, while matching their performance on the in-domain dataset VB-DemandEx. Ablation studies highlight the role of weight sharing between the time- and frequency-multi-head attention modules for generalization performance. Finally, we explore integrating the shared time- and frequency-multi-head attention modules with LSTM and xLSTM, which yields a notable performance improvement on the out-of-domain datasets. However, our MambAttention model remains superior on both out-of-domain datasets across all reported evaluation metrics.
A Survey of Deep Learning for Complex Speech Spectrograms
May 13, 2025Recent advancements in deep learning have significantly impacted the field of speech signal processing, particularly in the analysis and manipulation of complex spectrograms. This survey provides a comprehensive overview of the state-of-the-art techniques leveraging deep neural networks for processing complex spectrograms, which encapsulate both magnitude and phase information. We begin by introducing complex spectrograms and their associated features for various speech processing tasks. Next, we explore the key components and architectures of complex-valued neural networks, which are specifically designed to handle complex-valued data and have been applied for complex spectrogram processing. We then discuss various training strategies and loss functions tailored for training neural networks to process and model complex spectrograms. The survey further examines key applications, including phase retrieval, speech enhancement, and speech separation, where deep learning has achieved significant progress by leveraging complex spectrograms or their derived feature representations. Additionally, we examine the intersection of complex spectrograms with generative models. This survey aims to serve as a valuable resource for researchers and practitioners in the field of speech signal processing and complex-valued neural networks.
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025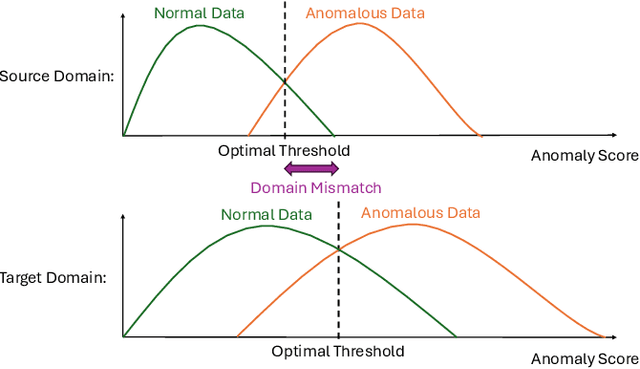
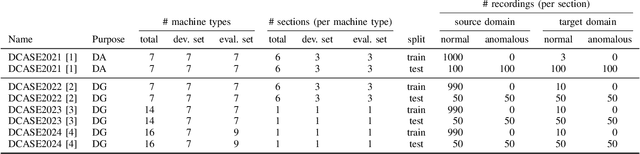
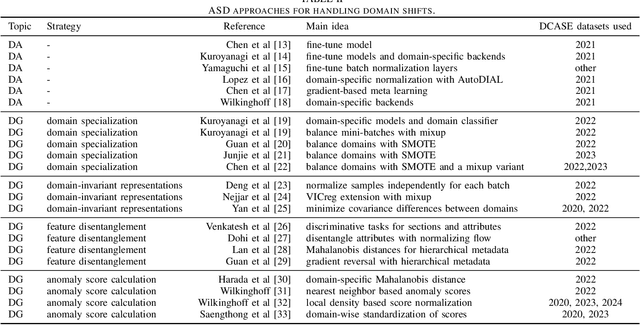
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.