 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
FieldFormer: Self-supervised Reconstruction of Physical Fields via Tensor Attention Prior
Jun 13, 2025Reconstructing physical field tensors from \textit{in situ} observations, such as radio maps and ocean sound speed fields, is crucial for enabling environment-aware decision making in various applications, e.g., wireless communications and underwater acoustics. Field data reconstruction is often challenging, due to the limited and noisy nature of the observations, necessitating the incorporation of prior information to aid the reconstruction process. Deep neural network-based data-driven structural constraints (e.g., ``deeply learned priors'') have showed promising performance. However, this family of techniques faces challenges such as model mismatches between training and testing phases. This work introduces FieldFormer, a self-supervised neural prior learned solely from the limited {\it in situ} observations without the need of offline training. Specifically, the proposed framework starts with modeling the fields of interest using the tensor Tucker model of a high multilinear rank, which ensures a universal approximation property for all fields. In the sequel, an attention mechanism is incorporated to learn the sparsity pattern that underlies the core tensor in order to reduce the solution space. In this way, a ``complexity-adaptive'' neural representation, grounded in the Tucker decomposition, is obtained that can flexibly represent various types of fields. A theoretical analysis is provided to support the recoverability of the proposed design. Moreover, extensive experiments, using various physical field tensors, demonstrate the superiority of the proposed approach compared to state-of-the-art baselines.
Audio xLSTMs: Learning Self-Supervised Audio Representations with xLSTMs
Sep 02, 2024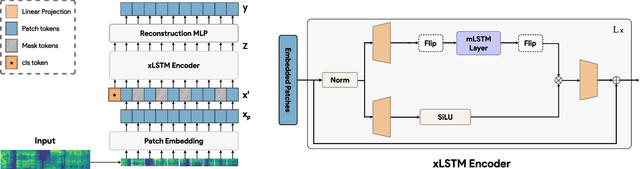
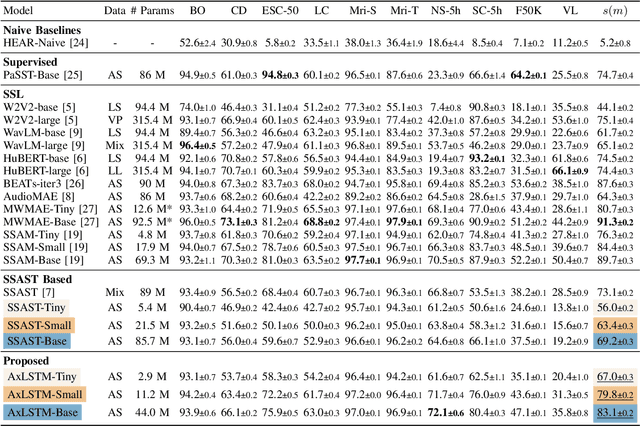
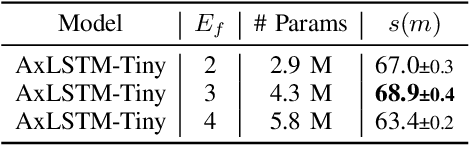
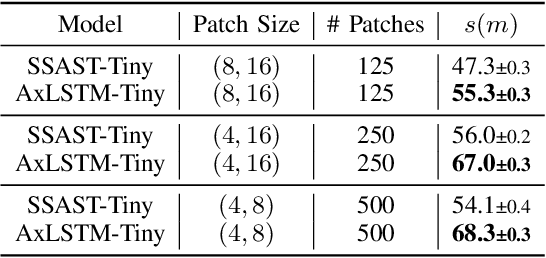
While the transformer has emerged as the eminent neural architecture, several independent lines of research have emerged to address its limitations. Recurrent neural approaches have also observed a lot of renewed interest, including the extended long short-term memory (xLSTM) architecture, which reinvigorates the original LSTM architecture. However, while xLSTMs have shown competitive performance compared to the transformer, their viability for learning self-supervised general-purpose audio representations has not yet been evaluated. This work proposes Audio xLSTM (AxLSTM), an approach to learn audio representations from masked spectrogram patches in a self-supervised setting. Pretrained on the AudioSet dataset, the proposed AxLSTM models outperform comparable self-supervised audio spectrogram transformer (SSAST) baselines by up to 20% in relative performance across a set of ten diverse downstream tasks while having up to 45% fewer parameters.
Towards Efficient Modeling and Inference in Multi-Dimensional Gaussian Process State-Space Models
Sep 03, 2023
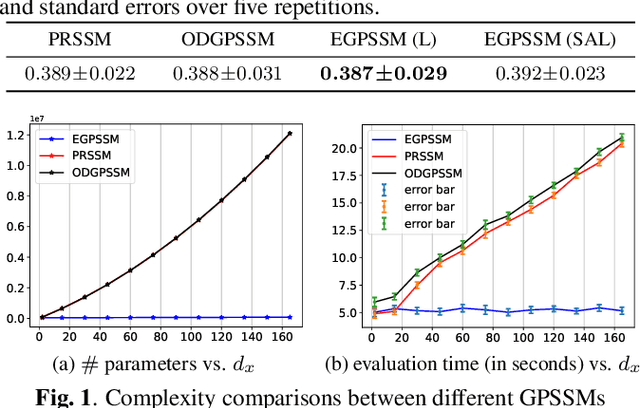

The Gaussian process state-space model (GPSSM) has attracted extensive attention for modeling complex nonlinear dynamical systems. However, the existing GPSSM employs separate Gaussian processes (GPs) for each latent state dimension, leading to escalating computational complexity and parameter proliferation, thus posing challenges for modeling dynamical systems with high-dimensional latent states. To surmount this obstacle, we propose to integrate the efficient transformed Gaussian process (ETGP) into the GPSSM, which involves pushing a shared GP through multiple normalizing flows to efficiently model the transition function in high-dimensional latent state space. Additionally, we develop a corresponding variational inference algorithm that surpasses existing methods in terms of parameter count and computational complexity. Experimental results on diverse synthetic and real-world datasets corroborate the efficiency of the proposed method, while also demonstrating its ability to achieve similar inference performance compared to existing methods. Code is available at \url{https://github.com/zhidilin/gpssmProj}.
Masked Autoencoders with Multi-Window Attention Are Better Audio Learners
Jun 01, 2023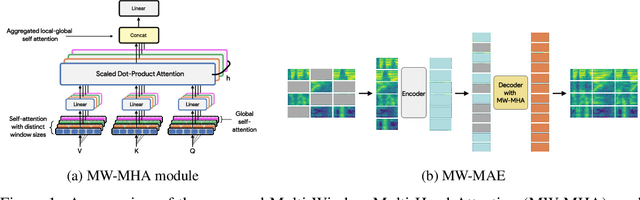
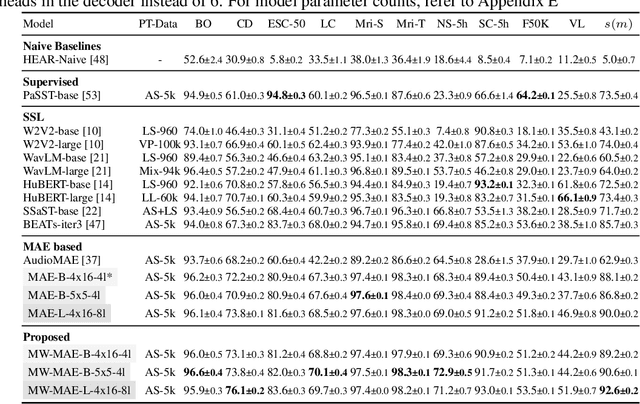
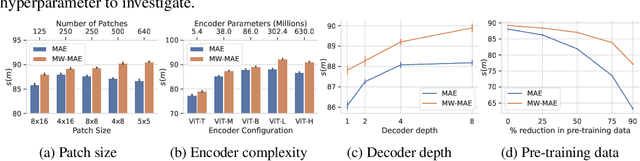
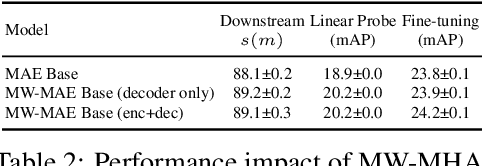
Several recent works have adapted Masked Autoencoders (MAEs) for learning general-purpose audio representations. However, they do not address two key aspects of modelling multi-domain audio data: (i) real-world audio tasks consist of a combination of local+global contexts, and (ii) real-world audio signals are complex compositions of several acoustic elements with different time-frequency characteristics. To address these concerns, this work proposes a Multi-Window Masked Autoencoder (MW-MAE) fitted with a novel Multi-Window Multi-Head Attention module that can capture information at multiple local and global contexts in every decoder transformer block through attention heads of several distinct local and global windows. Empirical results on ten downstream audio tasks show that MW-MAEs consistently outperform standard MAEs in overall performance and learn better general-purpose audio representations, as well as demonstrate considerably better scaling characteristics. Exploratory analyses of the learned representations reveals that MW-MAE encoders learn attention heads with more distinct entropies compared to those learned by MAEs, while attention heads across the different transformer blocks in MW-MAE decoders learn correlated feature representations, enabling each block to independently capture local and global information, leading to a decoupled feature hierarchy. Code for feature extraction and downstream experiments along with pre-trained weights can be found at https://github.com/10997NeurIPS23/10997_mwmae.
Rethinking Bayesian Learning for Data Analysis: The Art of Prior and Inference in Sparsity-Aware Modeling
May 28, 2022
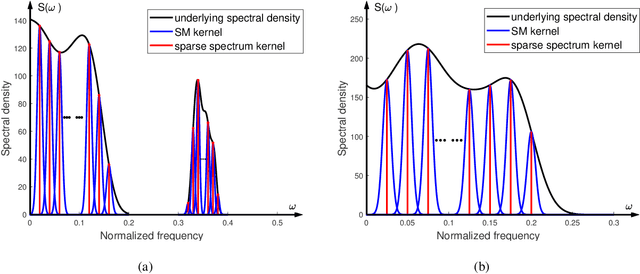
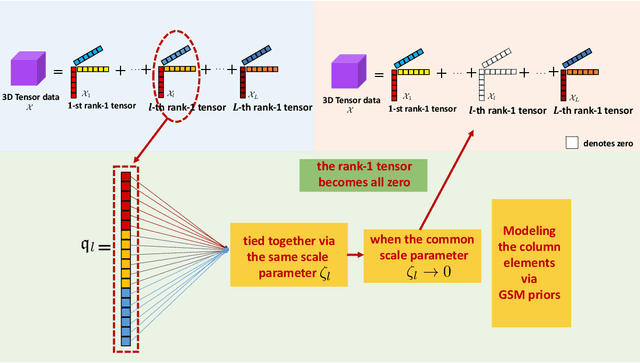
Sparse modeling for signal processing and machine learning has been at the focus of scientific research for over two decades. Among others, supervised sparsity-aware learning comprises two major paths paved by: a) discriminative methods and b) generative methods. The latter, more widely known as Bayesian methods, enable uncertainty evaluation w.r.t. the performed predictions. Furthermore, they can better exploit related prior information and naturally introduce robustness into the model, due to their unique capacity to marginalize out uncertainties related to the parameter estimates. Moreover, hyper-parameters associated with the adopted priors can be learnt via the training data. To implement sparsity-aware learning, the crucial point lies in the choice of the function regularizer for discriminative methods and the choice of the prior distribution for Bayesian learning. Over the last decade or so, due to the intense research on deep learning, emphasis has been put on discriminative techniques. However, a come back of Bayesian methods is taking place that sheds new light on the design of deep neural networks, which also establish firm links with Bayesian models and inspire new paths for unsupervised learning, such as Bayesian tensor decomposition. The goal of this article is two-fold. First, to review, in a unified way, some recent advances in incorporating sparsity-promoting priors into three highly popular data modeling tools, namely deep neural networks, Gaussian processes, and tensor decomposition. Second, to review their associated inference techniques from different aspects, including: evidence maximization via optimization and variational inference methods. Challenges such as small data dilemma, automatic model structure search, and natural prediction uncertainty evaluation are also discussed. Typical signal processing and machine learning tasks are demonstrated.
Stochastic Local Winner-Takes-All Networks Enable Profound Adversarial Robustness
Dec 05, 2021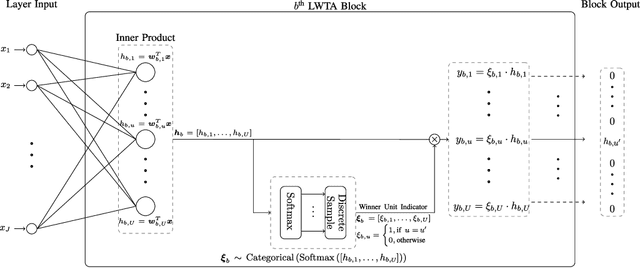
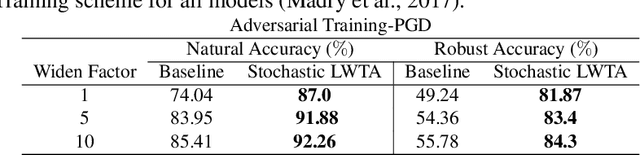
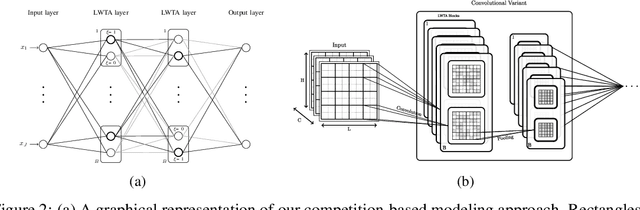
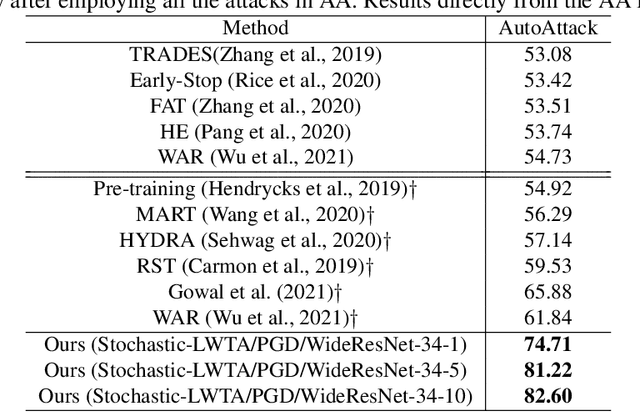
This work explores the potency of stochastic competition-based activations, namely Stochastic Local Winner-Takes-All (LWTA), against powerful (gradient-based) white-box and black-box adversarial attacks; we especially focus on Adversarial Training settings. In our work, we replace the conventional ReLU-based nonlinearities with blocks comprising locally and stochastically competing linear units. The output of each network layer now yields a sparse output, depending on the outcome of winner sampling in each block. We rely on the Variational Bayesian framework for training and inference; we incorporate conventional PGD-based adversarial training arguments to increase the overall adversarial robustness. As we experimentally show, the arising networks yield state-of-the-art robustness against powerful adversarial attacks while retaining very high classification rate in the benign case.
Dialog speech sentiment classification for imbalanced datasets
Sep 15, 2021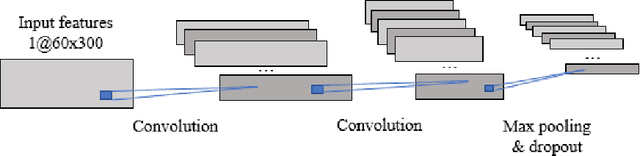
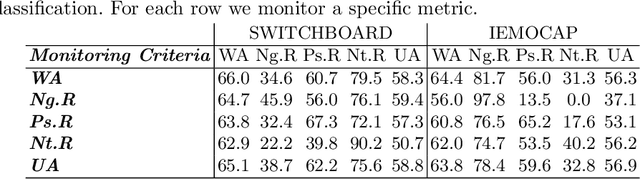
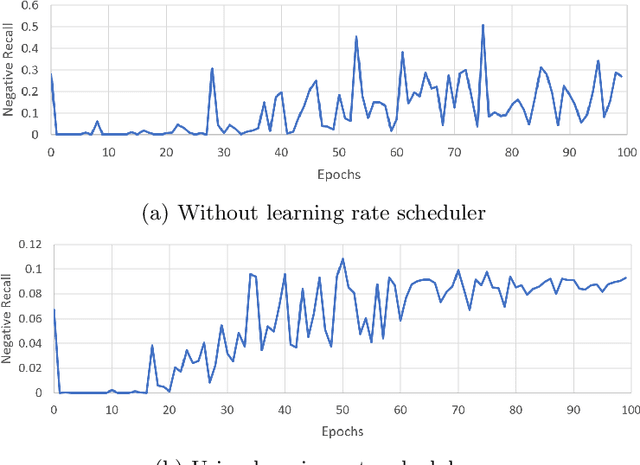
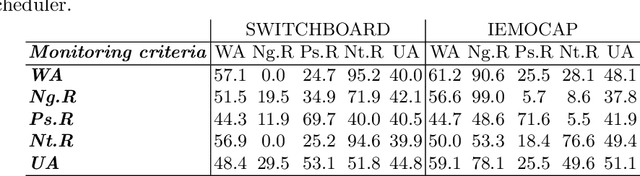
Speech is the most common way humans express their feelings, and sentiment analysis is the use of tools such as natural language processing and computational algorithms to identify the polarity of these feelings. Even though this field has seen tremendous advancements in the last two decades, the task of effectively detecting under represented sentiments in different kinds of datasets is still a challenging task. In this paper, we use single and bi-modal analysis of short dialog utterances and gain insights on the main factors that aid in sentiment detection, particularly in the underrepresented classes, in datasets with and without inherent sentiment component. Furthermore, we propose an architecture which uses a learning rate scheduler and different monitoring criteria and provides state-of-the-art results for the SWITCHBOARD imbalanced sentiment dataset.
Local Competition and Stochasticity for Adversarial Robustness in Deep Learning
Jan 04, 2021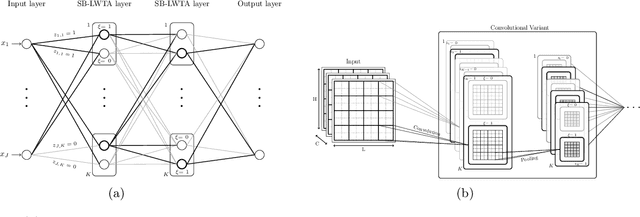
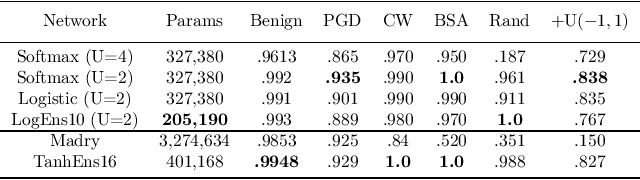

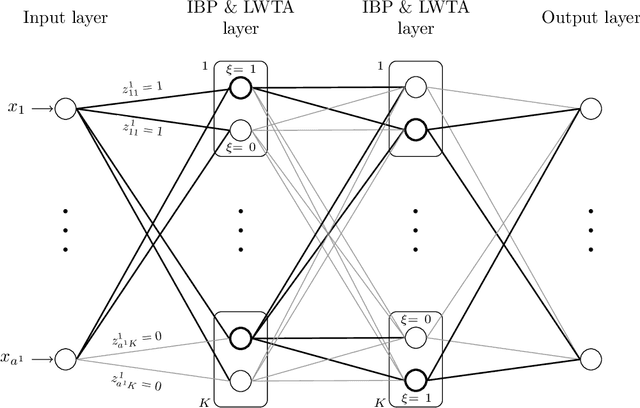
This work addresses adversarial robustness in deep learning by considering deep networks with stochastic local winner-takes-all (LWTA) nonlinearities. This type of network units result in sparse representations from each model layer, as the units are organized in blocks where only one unit generates non-zero output. The main operating principle of the introduced units lies on stochastic arguments, as the network performs posterior sampling over competing units to select the winner. We combine these LWTA arguments with tools from the field of Bayesian non-parametrics, specifically the stick-breaking construction of the Indian Buffet Process, to allow for inferring the sub-part of each layer that is essential for modeling the data at hand. Inference for the proposed network is performed by means of stochastic variational Bayes. We perform a thorough experimental evaluation of our model using benchmark datasets, assuming gradient-based adversarial attacks. As we show, our method achieves high robustness to adversarial perturbations, with state-of-the-art performance in powerful white-box attacks.
Towards Probabilistic Tensor Canonical Polyadic Decomposition 2.0: Automatic Tensor Rank Learning Using Generalized Hyperbolic Prior
Sep 05, 2020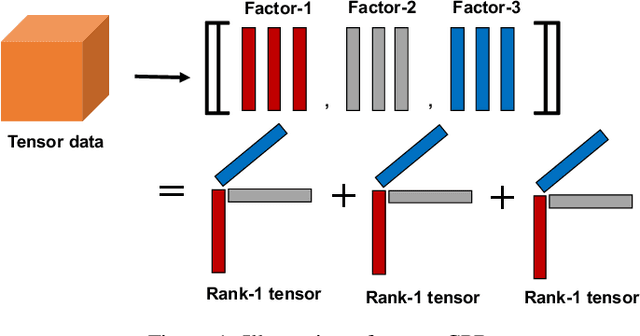
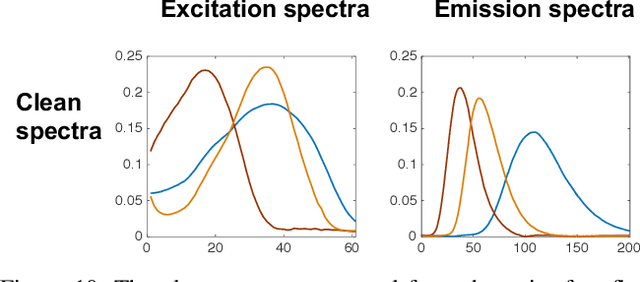
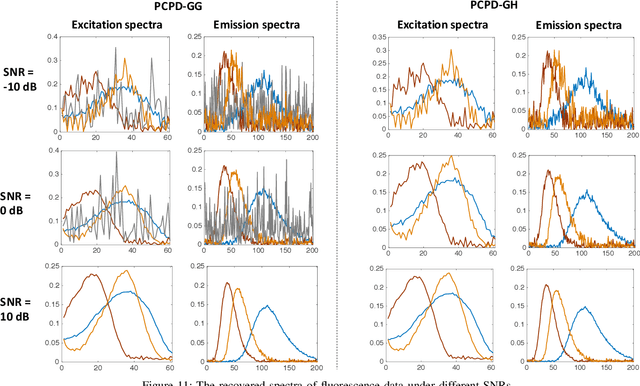
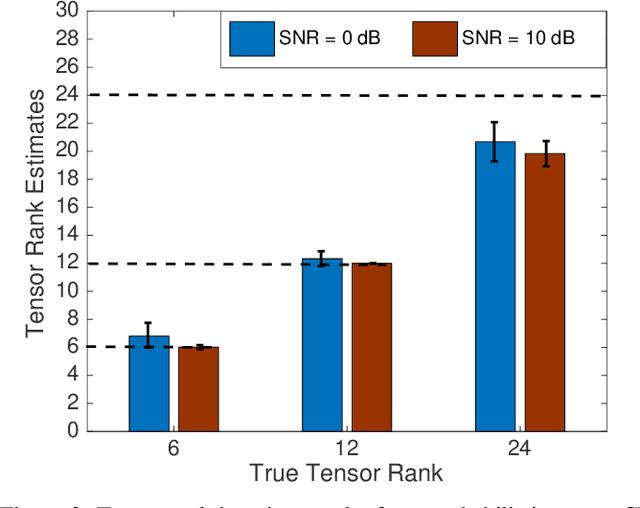
Tensor rank learning for canonical polyadic decomposition (CPD) has long been deemed as an essential but challenging problem. In particular, since the tensor rank controls the complexity of the CPD model, its inaccurate learning would cause overfitting to noise or underfitting to the signal sources, and even destroy the interpretability of model parameters. However, the optimal determination of a tensor rank is known to be a non-deterministic polynomial-time hard (NP-hard) task. Rather than exhaustively searching for the best tensor rank via trial-and-error experiments, Bayesian inference under the Gaussian-gamma prior was introduced in the context of probabilistic CPD modeling and it was shown to be an effective strategy for automatic tensor rank determination. This triggered flourishing research on other structured tensor CPDs with automatic tensor rank learning. As the other side of the coin, these research works also reveal that the Gaussian-gamma model does not perform well for high-rank tensors or/and low signal-to-noise ratios (SNRs). To overcome these drawbacks, in this paper, we introduce a more advanced generalized hyperbolic (GH) prior to the probabilistic CPD model, which not only includes the Gaussian-gamma model as a special case, but also provides more flexibilities to adapt to different levels of sparsity. Based on this novel probabilistic model, an algorithm is developed under the framework of variational inference, where each update is obtained in a closed-form. Extensive numerical results, using synthetic data and real-world datasets, demonstrate the excellent performance of the proposed method in learning both low as well as high tensor ranks even for low SNR cases.