 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Layer-Wise Dynamic Test Time Adaptation for LLMs
Feb 10, 2026Test-time adaptation (TTA) for large language models (LLMs) updates model parameters at inference time using signals available at deployment. This paper focuses on a common yet under-explored regime: unsupervised, sample-specific TTA, where the model adapts independently for each prompt using only the prompt itself, without gold answers or external supervision. Although appealing, naive unsupervised TTA with a fixed, handcrafted learning rate can be unstable: updates may overfit to prompt-specific statistics, drift from the desired answer distribution, and ultimately degrade generation quality. This failure mode is not surprising, as in this case TTA must adapt to a single prompt within only a few gradient steps, unlike standard training that averages updates over large datasets and long optimization horizons. Therefore, we propose layer-wise dynamic test-time adaptation, a framework which explicitly modulates TTA strength as a function of prompt representation, LLM structure and adaptation step. In our setting, TTA updates only LoRA parameters, and a lightweight hypernetwork predicts per-layer, per-step learning-rate multipliers, enabling fine-grained control. Experiments across various datasets and LLMs consistently show that our method substantially strengthens TTA by learning effective scaling patterns over adaptation steps and transformer layer projections, improving stability while delivering better performance.
PEMNet: Towards Autonomous and Enhanced Environment-Aware Mobile Networks
Jan 16, 2026With 5G deployment and the evolution toward 6G, mobile networks must make decisions in highly dynamic environments under strict latency, energy, and spectrum constraints. Achieving this goal, however, depends on prior knowledge of spatial-temporal variations in wireless channels and traffic demands. This motivates a joint, site-specific representation of radio propagation and user demand that is queryable at low online overhead. In this work, we propose the perception embedding map (PEM), a localized framework that embeds fine-grained channel statistics together with grid-level spatial-temporal traffic patterns over a base station's coverage. PEM is built from standard-compliant measurements -- such as measurement report and scheduling/quality-of-service logs -- so it can be deployed and maintained at scale with low cost. Integrated into PEM, this joint knowledge supports enhanced environment-aware optimization across PHY, MAC, and network layers while substantially reducing training overhead and signaling. Compared with existing site-specific channel maps and digital-twin replicas, PEM distinctively emphasizes (i) joint channel-traffic embedding, which is essential for network optimization, and (ii) practical construction using standard measurements, enabling network autonomy while striking a favorable fidelity-cost balance.
When Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
AsyncDiff: Asynchronous Timestep Conditioning for Enhanced Text-to-Image Diffusion Inference
Dec 21, 2025Text-to-image diffusion inference typically follows synchronized schedules, where the numerical integrator advances the latent state to the same timestep at which the denoiser is conditioned. We propose an asynchronous inference mechanism that decouples these two, allowing the denoiser to be conditioned at a different, learned timestep while keeping image update schedule unchanged. A lightweight timestep prediction module (TPM), trained with Group Relative Policy Optimization (GRPO), selects a more feasible conditioning timestep based on the current state, effectively choosing a desired noise level to control image detail and textural richness. At deployment, a scaling hyper-parameter can be used to interpolate between the original and de-synchronized timesteps, enabling conservative or aggressive adjustments. To keep the study computationally affordable, we cap the inference at 15 steps for SD3.5 and 10 steps for Flux. Evaluated on Stable Diffusion 3.5 Medium and Flux.1-dev across MS-COCO 2014 and T2I-CompBench datasets, our method optimizes a composite reward that averages Image Reward, HPSv2, CLIP Score and Pick Score, and shows consistent improvement.
Attentional Graph Meta-Learning for Indoor Localization Using Extremely Sparse Fingerprints
Apr 07, 2025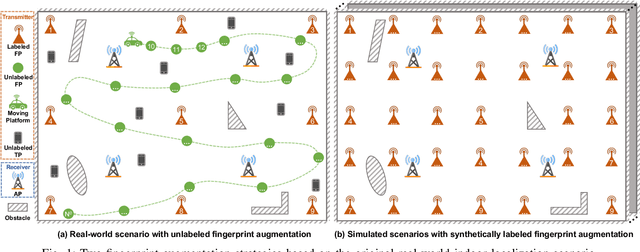
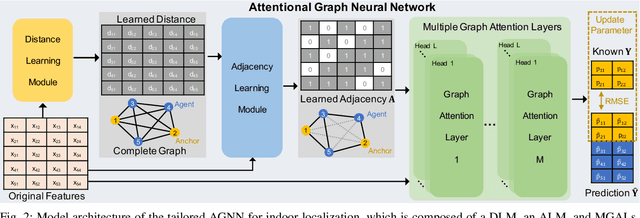
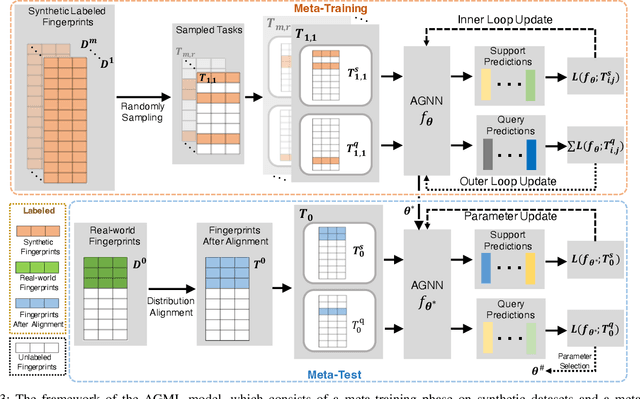

Fingerprint-based indoor localization is often labor-intensive due to the need for dense grids and repeated measurements across time and space. Maintaining high localization accuracy with extremely sparse fingerprints remains a persistent challenge. Existing benchmark methods primarily rely on the measured fingerprints, while neglecting valuable spatial and environmental characteristics. In this paper, we propose a systematic integration of an Attentional Graph Neural Network (AGNN) model, capable of learning spatial adjacency relationships and aggregating information from neighboring fingerprints, and a meta-learning framework that utilizes datasets with similar environmental characteristics to enhance model training. To minimize the labor required for fingerprint collection, we introduce two novel data augmentation strategies: 1) unlabeled fingerprint augmentation using moving platforms, which enables the semi-supervised AGNN model to incorporate information from unlabeled fingerprints, and 2) synthetic labeled fingerprint augmentation through environmental digital twins, which enhances the meta-learning framework through a practical distribution alignment, which can minimize the feature discrepancy between synthetic and real-world fingerprints effectively. By integrating these novel modules, we propose the Attentional Graph Meta-Learning (AGML) model. This novel model combines the strengths of the AGNN model and the meta-learning framework to address the challenges posed by extremely sparse fingerprints. To validate our approach, we collected multiple datasets from both consumer-grade WiFi devices and professional equipment across diverse environments. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that the AGML model-based localization method consistently outperforms all baseline methods using sparse fingerprints across all evaluated metrics.
Hybrid Data-Driven SSM for Interpretable and Label-Free mmWave Channel Prediction
Nov 18, 2024



Accurate prediction of mmWave time-varying channels is essential for mitigating the issue of channel aging in complex scenarios owing to high user mobility. Existing channel prediction methods have limitations: classical model-based methods often struggle to track highly nonlinear channel dynamics due to limited expert knowledge, while emerging data-driven methods typically require substantial labeled data for effective training and often lack interpretability. To address these issues, this paper proposes a novel hybrid method that integrates a data-driven neural network into a conventional model-based workflow based on a state-space model (SSM), implicitly tracking complex channel dynamics from data without requiring precise expert knowledge. Additionally, a novel unsupervised learning strategy is developed to train the embedded neural network solely with unlabeled data. Theoretical analyses and ablation studies are conducted to interpret the enhanced benefits gained from the hybrid integration. Numerical simulations based on the 3GPP mmWave channel model corroborate the superior prediction accuracy of the proposed method, compared to state-of-the-art methods that are either purely model-based or data-driven. Furthermore, extensive experiments validate its robustness against various challenging factors, including among others severe channel variations and high noise levels.
Preventing Model Collapse in Gaussian Process Latent Variable Models
Apr 02, 2024Gaussian process latent variable models (GPLVMs) are a versatile family of unsupervised learning models, commonly used for dimensionality reduction. However, common challenges in modeling data with GPLVMs include inadequate kernel flexibility and improper selection of the projection noise, which leads to a type of model collapse characterized primarily by vague latent representations that do not reflect the underlying structure of the data. This paper addresses these issues by, first, theoretically examining the impact of the projection variance on model collapse through the lens of a linear GPLVM. Second, we address the problem of model collapse due to inadequate kernel flexibility by integrating the spectral mixture (SM) kernel and a differentiable random Fourier feature (RFF) kernel approximation, which ensures computational scalability and efficiency through off-the-shelf automatic differentiation tools for learning the kernel hyperparameters, projection variance, and latent representations within the variational inference framework. The proposed GPLVM, named advisedRFLVM, is evaluated across diverse datasets and consistently outperforms various salient competing models, including state-of-the-art variational autoencoders (VAEs) and GPLVM variants, in terms of informative latent representations and missing data imputation.
Regularization-Based Efficient Continual Learning in Deep State-Space Models
Mar 15, 2024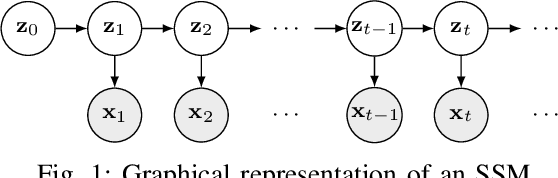
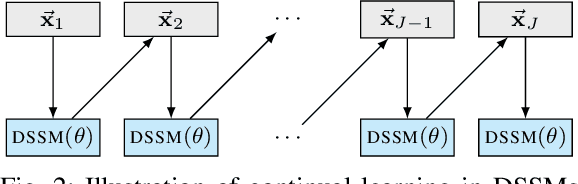
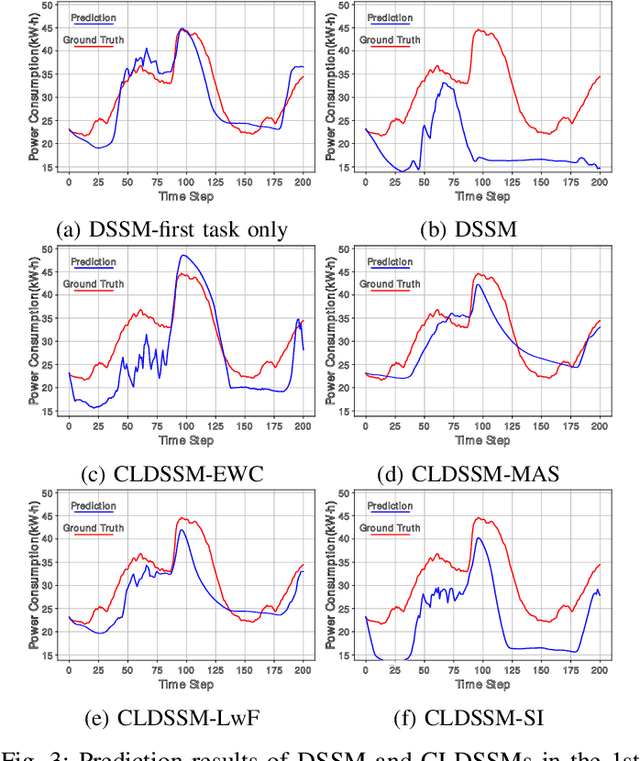
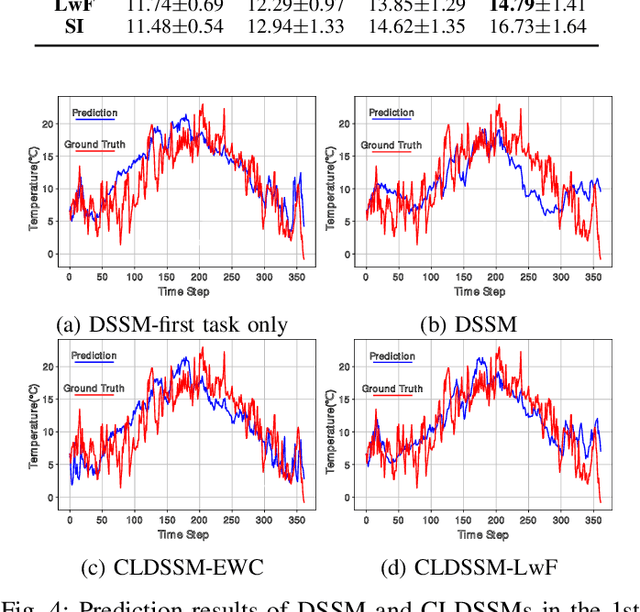
Deep state-space models (DSSMs) have gained popularity in recent years due to their potent modeling capacity for dynamic systems. However, existing DSSM works are limited to single-task modeling, which requires retraining with historical task data upon revisiting a forepassed task. To address this limitation, we propose continual learning DSSMs (CLDSSMs), which are capable of adapting to evolving tasks without catastrophic forgetting. Our proposed CLDSSMs integrate mainstream regularization-based continual learning (CL) methods, ensuring efficient updates with constant computational and memory costs for modeling multiple dynamic systems. We also conduct a comprehensive cost analysis of each CL method applied to the respective CLDSSMs, and demonstrate the efficacy of CLDSSMs through experiments on real-world datasets. The results corroborate that while various competing CL methods exhibit different merits, the proposed CLDSSMs consistently outperform traditional DSSMs in terms of effectively addressing catastrophic forgetting, enabling swift and accurate parameter transfer to new tasks.
Inverse Design of Photonic Crystal Surface Emitting Lasers is a Sequence Modeling Problem
Mar 08, 2024



Photonic Crystal Surface Emitting Lasers (PCSEL)'s inverse design demands expert knowledge in physics, materials science, and quantum mechanics which is prohibitively labor-intensive. Advanced AI technologies, especially reinforcement learning (RL), have emerged as a powerful tool to augment and accelerate this inverse design process. By modeling the inverse design of PCSEL as a sequential decision-making problem, RL approaches can construct a satisfactory PCSEL structure from scratch. However, the data inefficiency resulting from online interactions with precise and expensive simulation environments impedes the broader applicability of RL approaches. Recently, sequential models, especially the Transformer architecture, have exhibited compelling performance in sequential decision-making problems due to their simplicity and scalability to large language models. In this paper, we introduce a novel framework named PCSEL Inverse Design Transformer (PiT) that abstracts the inverse design of PCSEL as a sequence modeling problem. The central part of our PiT is a Transformer-based structure that leverages the past trajectories and current states to predict the current actions. Compared with the traditional RL approaches, PiT can output the optimal actions and achieve target PCSEL designs by leveraging offline data and conditioning on the desired return. Results demonstrate that PiT achieves superior performance and data efficiency compared to baselines.
Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
Jan 07, 2024Intelligent agents stand out as a potential path toward artificial general intelligence (AGI). Thus, researchers have dedicated significant effort to diverse implementations for them. Benefiting from recent progress in large language models (LLMs), LLM-based agents that use universal natural language as an interface exhibit robust generalization capabilities across various applications -- from serving as autonomous general-purpose task assistants to applications in coding, social, and economic domains, LLM-based agents offer extensive exploration opportunities. This paper surveys current research to provide an in-depth overview of LLM-based intelligent agents within single-agent and multi-agent systems. It covers their definitions, research frameworks, and foundational components such as their composition, cognitive and planning methods, tool utilization, and responses to environmental feedback. We also delve into the mechanisms of deploying LLM-based agents in multi-agent systems, including multi-role collaboration, message passing, and strategies to alleviate communication issues between agents. The discussions also shed light on popular datasets and application scenarios. We conclude by envisioning prospects for LLM-based agents, considering the evolving landscape of AI and natural language processing.