 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
FaST: Efficient and Effective Long-Horizon Forecasting for Large-Scale Spatial-Temporal Graphs via Mixture-of-Experts
Jan 08, 2026Spatial-Temporal Graph (STG) forecasting on large-scale networks has garnered significant attention. However, existing models predominantly focus on short-horizon predictions and suffer from notorious computational costs and memory consumption when scaling to long-horizon predictions and large graphs. Targeting the above challenges, we present FaST, an effective and efficient framework based on heterogeneity-aware Mixture-of-Experts (MoEs) for long-horizon and large-scale STG forecasting, which unlocks one-week-ahead (672 steps at a 15-minute granularity) prediction with thousands of nodes. FaST is underpinned by two key innovations. First, an adaptive graph agent attention mechanism is proposed to alleviate the computational burden inherent in conventional graph convolution and self-attention modules when applied to large-scale graphs. Second, we propose a new parallel MoE module that replaces traditional feed-forward networks with Gated Linear Units (GLUs), enabling an efficient and scalable parallel structure. Extensive experiments on real-world datasets demonstrate that FaST not only delivers superior long-horizon predictive accuracy but also achieves remarkable computational efficiency compared to state-of-the-art baselines. Our source code is available at: https://github.com/yijizhao/FaST.
DevPiolt: Operation Recommendation for IoT Devices at Xiaomi Home
Nov 18, 2025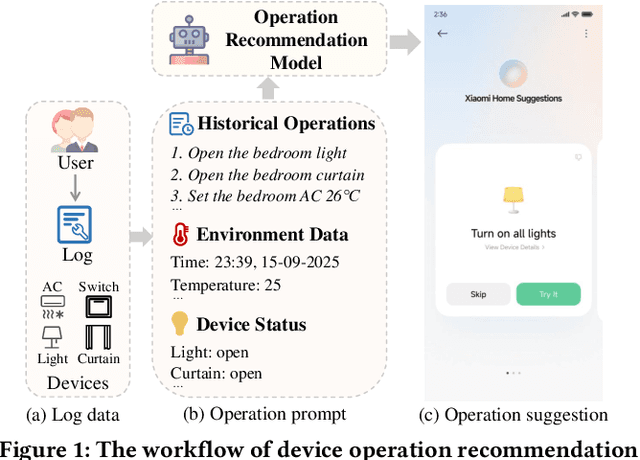
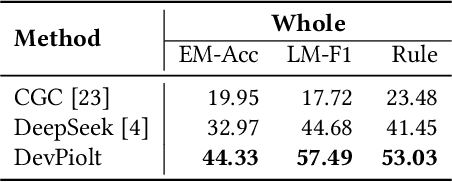
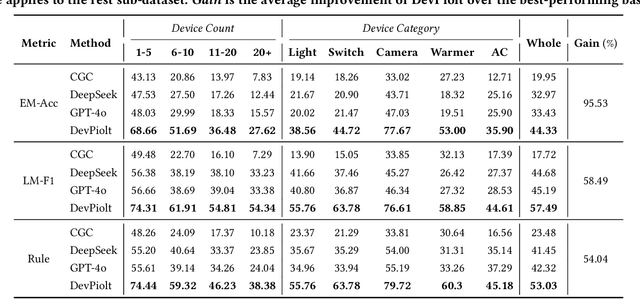
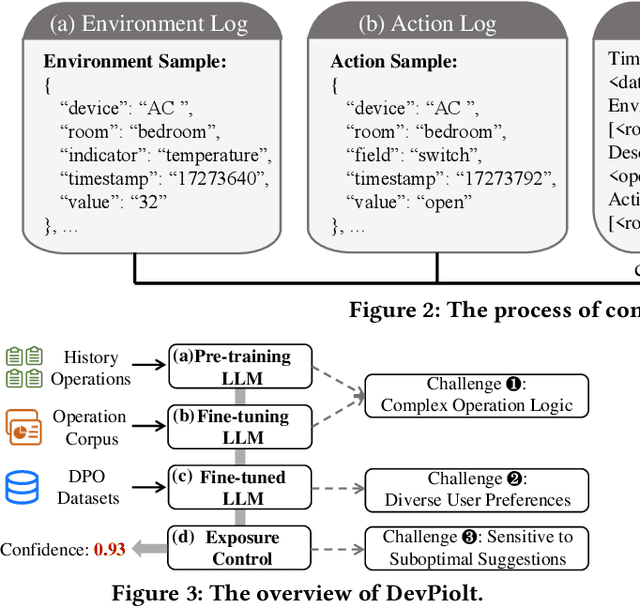
Operation recommendation for IoT devices refers to generating personalized device operations for users based on their context, such as historical operations, environment information, and device status. This task is crucial for enhancing user satisfaction and corporate profits. Existing recommendation models struggle with complex operation logic, diverse user preferences, and sensitive to suboptimal suggestions, limiting their applicability to IoT device operations. To address these issues, we propose DevPiolt, a LLM-based recommendation model for IoT device operations. Specifically, we first equip the LLM with fundamental domain knowledge of IoT operations via continual pre-training and multi-task fine-tuning. Then, we employ direct preference optimization to align the fine-tuned LLM with specific user preferences. Finally, we design a confidence-based exposure control mechanism to avoid negative user experiences from low-quality recommendations. Extensive experiments show that DevPiolt significantly outperforms baselines on all datasets, with an average improvement of 69.5% across all metrics. DevPiolt has been practically deployed in Xiaomi Home app for one quarter, providing daily operation recommendations to 255,000 users. Online experiment results indicate a 21.6% increase in unique visitor device coverage and a 29.1% increase in page view acceptance rates.
Attentional Graph Meta-Learning for Indoor Localization Using Extremely Sparse Fingerprints
Apr 07, 2025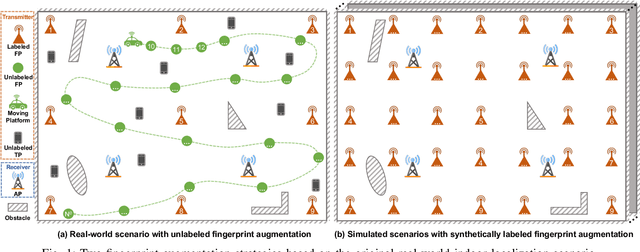
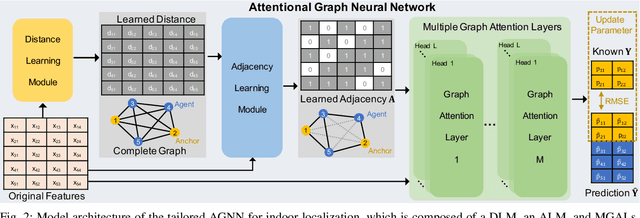
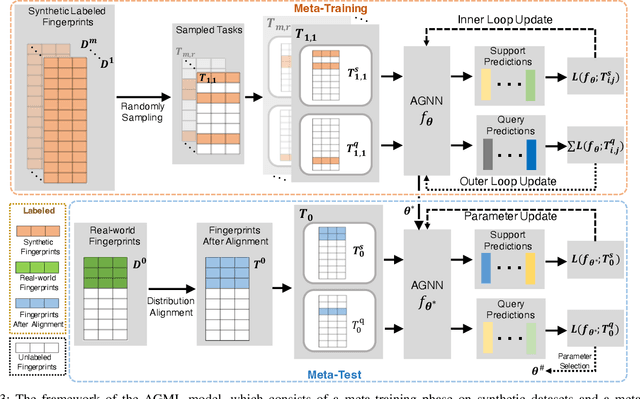

Fingerprint-based indoor localization is often labor-intensive due to the need for dense grids and repeated measurements across time and space. Maintaining high localization accuracy with extremely sparse fingerprints remains a persistent challenge. Existing benchmark methods primarily rely on the measured fingerprints, while neglecting valuable spatial and environmental characteristics. In this paper, we propose a systematic integration of an Attentional Graph Neural Network (AGNN) model, capable of learning spatial adjacency relationships and aggregating information from neighboring fingerprints, and a meta-learning framework that utilizes datasets with similar environmental characteristics to enhance model training. To minimize the labor required for fingerprint collection, we introduce two novel data augmentation strategies: 1) unlabeled fingerprint augmentation using moving platforms, which enables the semi-supervised AGNN model to incorporate information from unlabeled fingerprints, and 2) synthetic labeled fingerprint augmentation through environmental digital twins, which enhances the meta-learning framework through a practical distribution alignment, which can minimize the feature discrepancy between synthetic and real-world fingerprints effectively. By integrating these novel modules, we propose the Attentional Graph Meta-Learning (AGML) model. This novel model combines the strengths of the AGNN model and the meta-learning framework to address the challenges posed by extremely sparse fingerprints. To validate our approach, we collected multiple datasets from both consumer-grade WiFi devices and professional equipment across diverse environments. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that the AGML model-based localization method consistently outperforms all baseline methods using sparse fingerprints across all evaluated metrics.
LSNet: See Large, Focus Small
Mar 29, 2025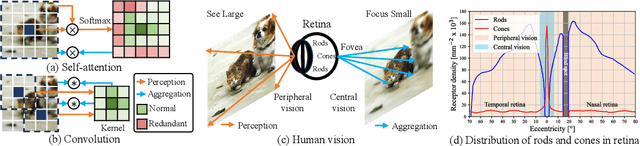
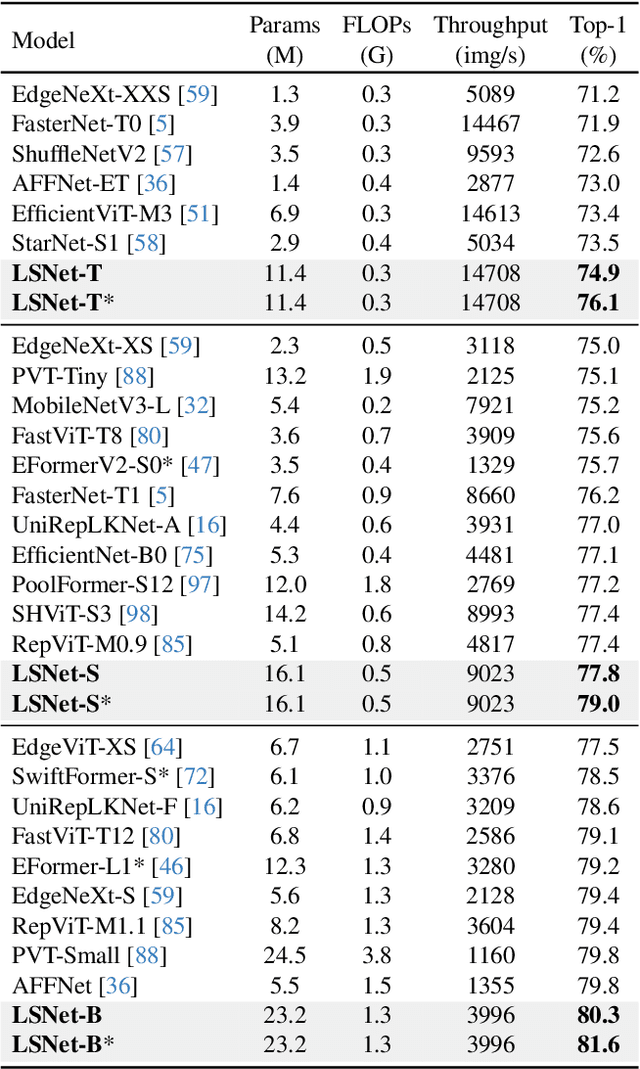
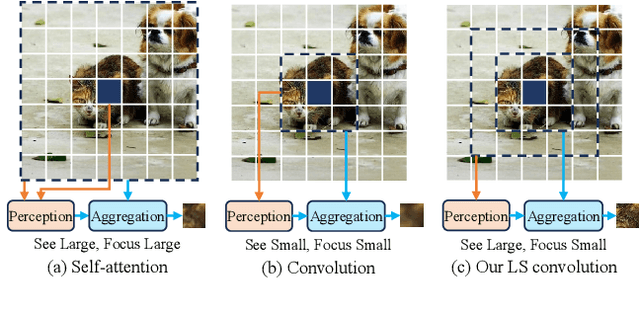
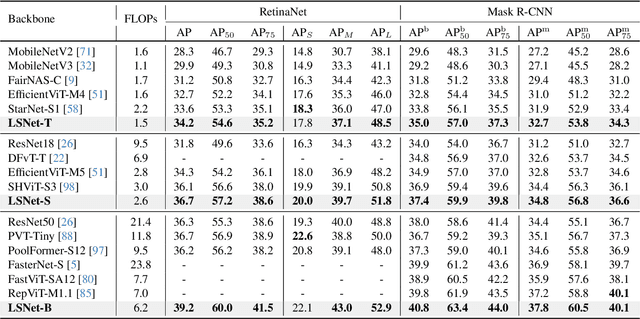
Vision network designs, including Convolutional Neural Networks and Vision Transformers, have significantly advanced the field of computer vision. Yet, their complex computations pose challenges for practical deployments, particularly in real-time applications. To tackle this issue, researchers have explored various lightweight and efficient network designs. However, existing lightweight models predominantly leverage self-attention mechanisms and convolutions for token mixing. This dependence brings limitations in effectiveness and efficiency in the perception and aggregation processes of lightweight networks, hindering the balance between performance and efficiency under limited computational budgets. In this paper, we draw inspiration from the dynamic heteroscale vision ability inherent in the efficient human vision system and propose a ``See Large, Focus Small'' strategy for lightweight vision network design. We introduce LS (\textbf{L}arge-\textbf{S}mall) convolution, which combines large-kernel perception and small-kernel aggregation. It can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information. Based on LS convolution, we present LSNet, a new family of lightweight models. Extensive experiments demonstrate that LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks. Codes and models are available at https://github.com/jameslahm/lsnet.
YOLOE: Real-Time Seeing Anything
Mar 10, 2025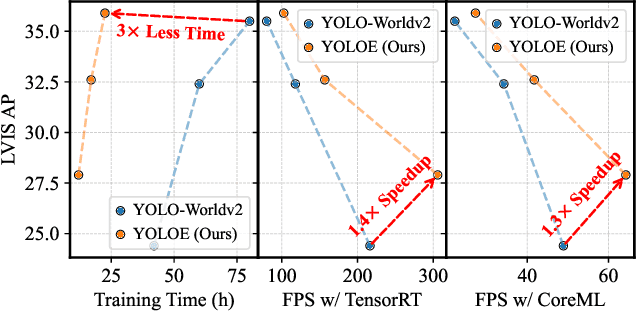
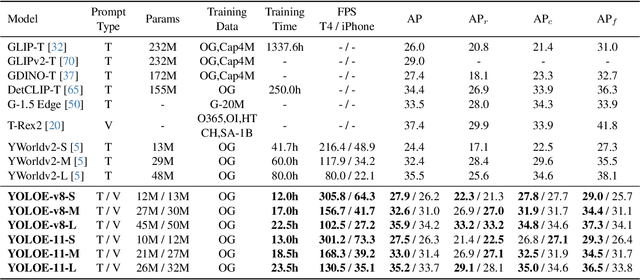
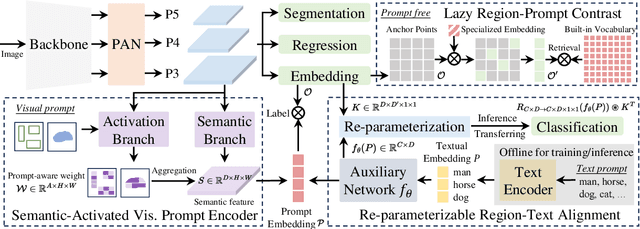
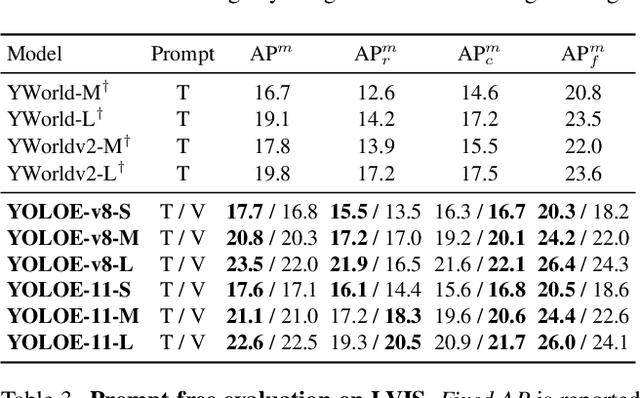
Object detection and segmentation are widely employed in computer vision applications, yet conventional models like YOLO series, while efficient and accurate, are limited by predefined categories, hindering adaptability in open scenarios. Recent open-set methods leverage text prompts, visual cues, or prompt-free paradigm to overcome this, but often compromise between performance and efficiency due to high computational demands or deployment complexity. In this work, we introduce YOLOE, which integrates detection and segmentation across diverse open prompt mechanisms within a single highly efficient model, achieving real-time seeing anything. For text prompts, we propose Re-parameterizable Region-Text Alignment (RepRTA) strategy. It refines pretrained textual embeddings via a re-parameterizable lightweight auxiliary network and enhances visual-textual alignment with zero inference and transferring overhead. For visual prompts, we present Semantic-Activated Visual Prompt Encoder (SAVPE). It employs decoupled semantic and activation branches to bring improved visual embedding and accuracy with minimal complexity. For prompt-free scenario, we introduce Lazy Region-Prompt Contrast (LRPC) strategy. It utilizes a built-in large vocabulary and specialized embedding to identify all objects, avoiding costly language model dependency. Extensive experiments show YOLOE's exceptional zero-shot performance and transferability with high inference efficiency and low training cost. Notably, on LVIS, with 3$\times$ less training cost and 1.4$\times$ inference speedup, YOLOE-v8-S surpasses YOLO-Worldv2-S by 3.5 AP. When transferring to COCO, YOLOE-v8-L achieves 0.6 AP$^b$ and 0.4 AP$^m$ gains over closed-set YOLOv8-L with nearly 4$\times$ less training time. Code and models are available at https://github.com/THU-MIG/yoloe.
YOLO-UniOW: Efficient Universal Open-World Object Detection
Dec 30, 2024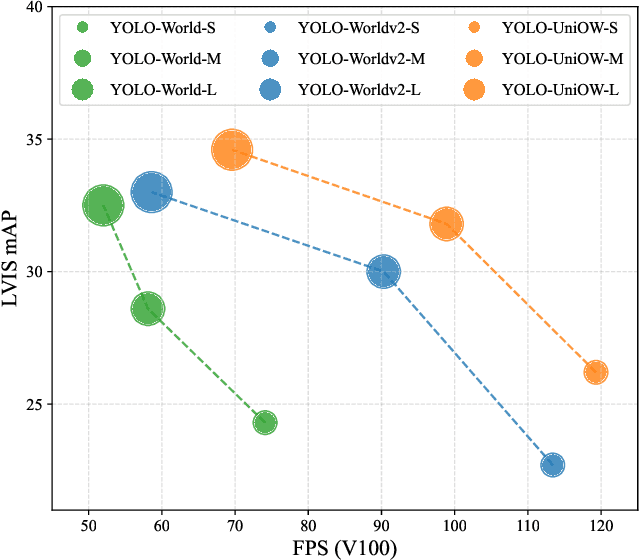
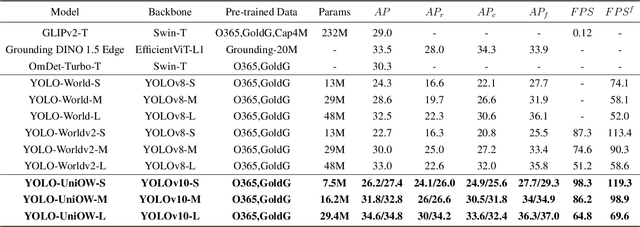
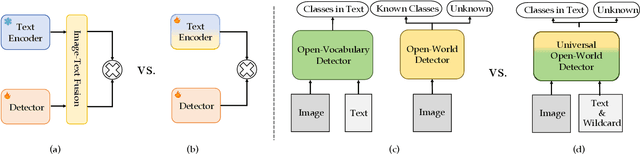
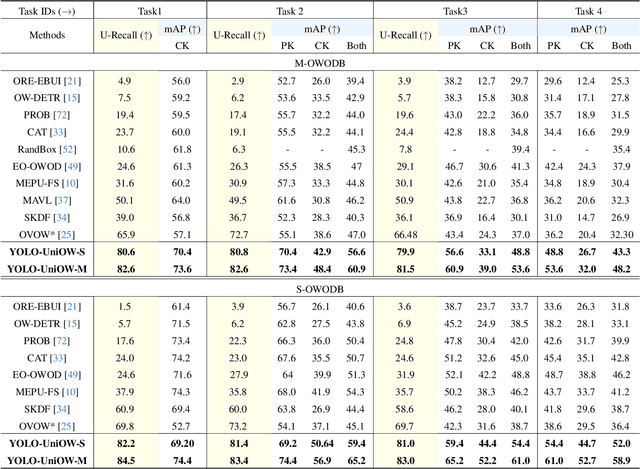
Traditional object detection models are constrained by the limitations of closed-set datasets, detecting only categories encountered during training. While multimodal models have extended category recognition by aligning text and image modalities, they introduce significant inference overhead due to cross-modality fusion and still remain restricted by predefined vocabulary, leaving them ineffective at handling unknown objects in open-world scenarios. In this work, we introduce Universal Open-World Object Detection (Uni-OWD), a new paradigm that unifies open-vocabulary and open-world object detection tasks. To address the challenges of this setting, we propose YOLO-UniOW, a novel model that advances the boundaries of efficiency, versatility, and performance. YOLO-UniOW incorporates Adaptive Decision Learning to replace computationally expensive cross-modality fusion with lightweight alignment in the CLIP latent space, achieving efficient detection without compromising generalization. Additionally, we design a Wildcard Learning strategy that detects out-of-distribution objects as "unknown" while enabling dynamic vocabulary expansion without the need for incremental learning. This design empowers YOLO-UniOW to seamlessly adapt to new categories in open-world environments. Extensive experiments validate the superiority of YOLO-UniOW, achieving achieving 34.6 AP and 30.0 APr on LVIS with an inference speed of 69.6 FPS. The model also sets benchmarks on M-OWODB, S-OWODB, and nuScenes datasets, showcasing its unmatched performance in open-world object detection. Code and models are available at https://github.com/THU-MIG/YOLO-UniOW.
[CLS] Token Tells Everything Needed for Training-free Efficient MLLMs
Dec 08, 2024![Figure 1 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F7-Table2-1.png&w=640&q=75)
Multimodal Large Language Models (MLLMs) have recently demonstrated strong performance across a wide range of vision-language tasks, garnering significant attention in the computer vision. However, their efficient deployment remains a substantial challenge due to high computational costs and memory requirements. Recognizing the redundancy of information within the vision modality, recent studies have explored methods for compressing visual tokens in MLLMs to enhance efficiency in a training-free manner. Despite their effectiveness, existing methods like Fast rely on the attention between visual tokens and prompt text tokens as the importance indicator, overlooking the relevance to response text and thus introducing perception bias. In this paper, we demonstrate that in MLLMs, the [CLS] token in the visual encoder inherently knows which visual tokens are important for MLLMs. Building on this prior, we introduce a simple yet effective method for train-free visual token compression, called VTC-CLS. Firstly, it leverages the attention score of the [CLS] token on visual tokens as an importance indicator for pruning visual tokens. Besides, we also explore ensembling the importance scores derived by the [CLS] token from different layers to capture the key visual information more comprehensively. Extensive experiments demonstrate that our VTC-CLS achieves the state-of-the-art performance across various tasks compared with baseline methods. It also brings notably less computational costs in a training-free manner, highlighting its effectiveness and superiority. Code and models are available at \url{https://github.com/THU-MIG/VTC-CLS}.
PrefixKV: Adaptive Prefix KV Cache is What Vision Instruction-Following Models Need for Efficient Generation
Dec 04, 2024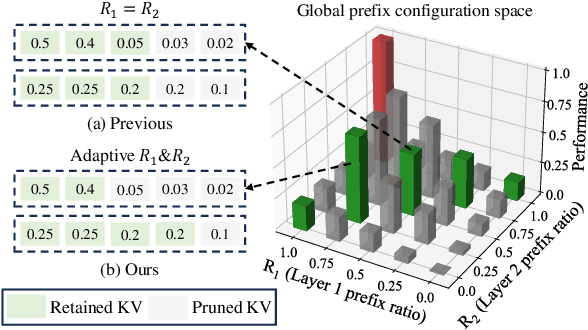

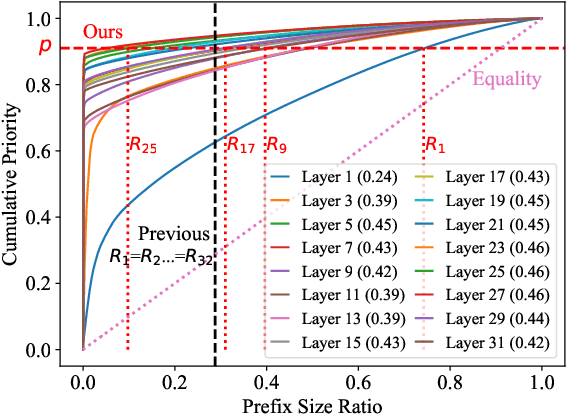

Recently, large vision-language models (LVLMs) have rapidly gained popularity for their strong generation and reasoning capabilities given diverse multimodal inputs. However, these models incur significant computational and memory overhead during inference, which greatly hinders the efficient deployment in practical scenarios. The extensive key-value (KV) cache, necessitated by the lengthy input and output sequences, notably contributes to the high inference cost. Based on this, recent works have investigated ways to reduce the KV cache size for higher efficiency. Although effective, they generally overlook the distinct importance distributions of KV vectors across layers and maintain the same cache size for each layer during the next token prediction. This results in the significant contextual information loss for certain layers, leading to notable performance decline. To address this, we present PrefixKV. It reframes the challenge of determining KV cache sizes for all layers into the task of searching for the optimal global prefix configuration. With an adaptive layer-wise KV retention recipe based on binary search, the maximum contextual information can thus be preserved in each layer, facilitating the generation. Extensive experiments demonstrate that our method achieves the state-of-the-art performance compared with others. It exhibits superior inference efficiency and generation quality trade-offs, showing promising potential for practical applications. Code is available at \url{https://github.com/THU-MIG/PrefixKV}.
Promptable Anomaly Segmentation with SAM Through Self-Perception Tuning
Nov 26, 2024



Segment Anything Model (SAM) has made great progress in anomaly segmentation tasks due to its impressive generalization ability. However, existing methods that directly apply SAM through prompting often overlook the domain shift issue, where SAM performs well on natural images but struggles in industrial scenarios. Parameter-Efficient Fine-Tuning (PEFT) offers a promising solution, but it may yield suboptimal performance by not adequately addressing the perception challenges during adaptation to anomaly images. In this paper, we propose a novel Self-Perceptinon Tuning (SPT) method, aiming to enhance SAM's perception capability for anomaly segmentation. The SPT method incorporates a self-drafting tuning strategy, which generates an initial coarse draft of the anomaly mask, followed by a refinement process. Additionally, a visual-relation-aware adapter is introduced to improve the perception of discriminative relational information for mask generation. Extensive experimental results on several benchmark datasets demonstrate that our SPT method can significantly outperform baseline methods, validating its effectiveness. Models and codes will be available online.