 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
Sep 30, 2025As LLM-based agents are increasingly deployed in real-life scenarios, existing benchmarks fail to capture their inherent complexity of handling extensive information, leveraging diverse resources, and managing dynamic user interactions. To address this gap, we introduce VitaBench, a challenging benchmark that evaluates agents on versatile interactive tasks grounded in real-world settings. Drawing from daily applications in food delivery, in-store consumption, and online travel services, VitaBench presents agents with the most complex life-serving simulation environment to date, comprising 66 tools. Through a framework that eliminates domain-specific policies, we enable flexible composition of these scenarios and tools, yielding 100 cross-scenario tasks (main results) and 300 single-scenario tasks. Each task is derived from multiple real user requests and requires agents to reason across temporal and spatial dimensions, utilize complex tool sets, proactively clarify ambiguous instructions, and track shifting user intent throughout multi-turn conversations. Moreover, we propose a rubric-based sliding window evaluator, enabling robust assessment of diverse solution pathways in complex environments and stochastic interactions. Our comprehensive evaluation reveals that even the most advanced models achieve only 30% success rate on cross-scenario tasks, and less than 50% success rate on others. Overall, we believe VitaBench will serve as a valuable resource for advancing the development of AI agents in practical real-world applications. The code, dataset, and leaderboard are available at https://vitabench.github.io/
MaskPrune: Mask-based LLM Pruning for Layer-wise Uniform Structures
Feb 19, 2025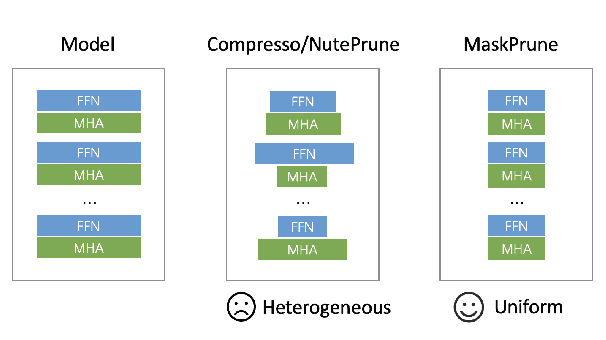
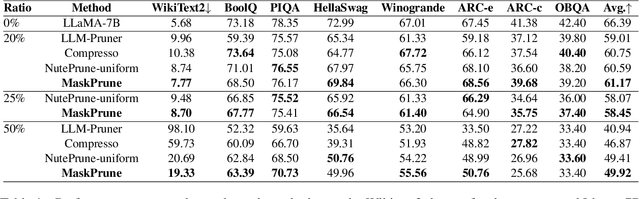
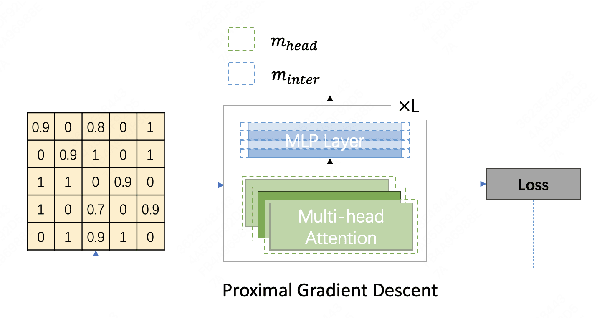

The remarkable performance of large language models (LLMs) in various language tasks has attracted considerable attention. However, the ever-increasing size of these models presents growing challenges for deployment and inference. Structured pruning, an effective model compression technique, is gaining increasing attention due to its ability to enhance inference efficiency. Nevertheless, most previous optimization-based structured pruning methods sacrifice the uniform structure across layers for greater flexibility to maintain performance. The heterogeneous structure hinders the effective utilization of off-the-shelf inference acceleration techniques and impedes efficient configuration for continued training. To address this issue, we propose a novel masking learning paradigm based on minimax optimization to obtain the uniform pruned structure by optimizing the masks under sparsity regularization. Extensive experimental results demonstrate that our method can maintain high performance while ensuring the uniformity of the pruned model structure, thereby outperforming existing SOTA methods.
C2T: A Classifier-Based Tree Construction Method in Speculative Decoding
Feb 19, 2025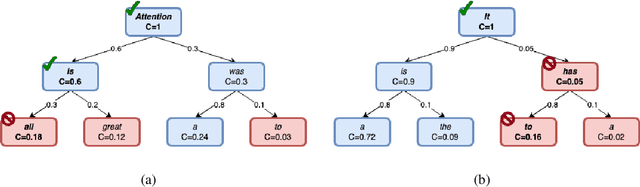
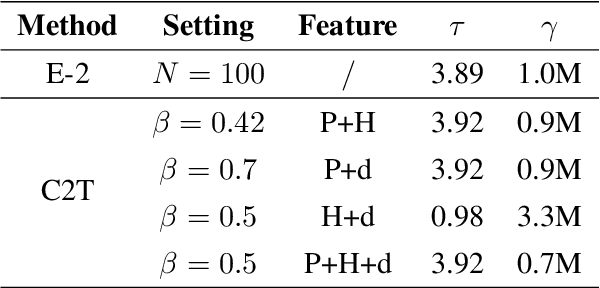

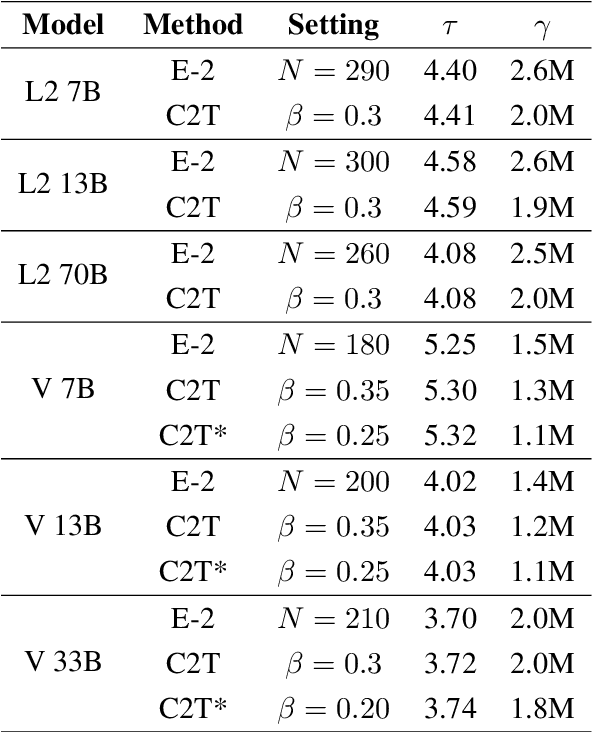
The growing scale of Large Language Models (LLMs) has exacerbated inference latency and computational costs. Speculative decoding methods, which aim to mitigate these issues, often face inefficiencies in the construction of token trees and the verification of candidate tokens. Existing strategies, including chain mode, static tree, and dynamic tree approaches, have limitations in accurately preparing candidate token trees for verification. We propose a novel method named C2T that adopts a lightweight classifier to generate and prune token trees dynamically. Our classifier considers additional feature variables beyond the commonly used joint probability to predict the confidence score for each draft token to determine whether it is the candidate token for verification. This method outperforms state-of-the-art (SOTA) methods such as EAGLE-2 on multiple benchmarks, by reducing the total number of candidate tokens by 25% while maintaining or even improving the acceptance length.
PrefixKV: Adaptive Prefix KV Cache is What Vision Instruction-Following Models Need for Efficient Generation
Dec 04, 2024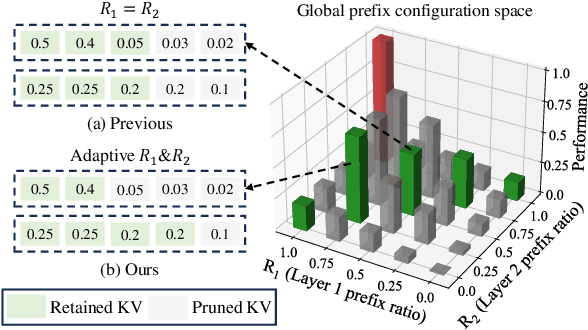

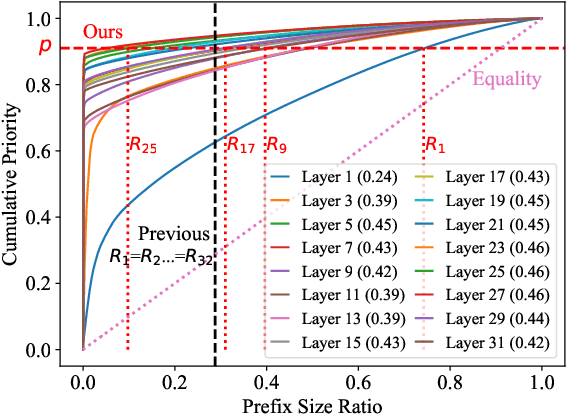

Recently, large vision-language models (LVLMs) have rapidly gained popularity for their strong generation and reasoning capabilities given diverse multimodal inputs. However, these models incur significant computational and memory overhead during inference, which greatly hinders the efficient deployment in practical scenarios. The extensive key-value (KV) cache, necessitated by the lengthy input and output sequences, notably contributes to the high inference cost. Based on this, recent works have investigated ways to reduce the KV cache size for higher efficiency. Although effective, they generally overlook the distinct importance distributions of KV vectors across layers and maintain the same cache size for each layer during the next token prediction. This results in the significant contextual information loss for certain layers, leading to notable performance decline. To address this, we present PrefixKV. It reframes the challenge of determining KV cache sizes for all layers into the task of searching for the optimal global prefix configuration. With an adaptive layer-wise KV retention recipe based on binary search, the maximum contextual information can thus be preserved in each layer, facilitating the generation. Extensive experiments demonstrate that our method achieves the state-of-the-art performance compared with others. It exhibits superior inference efficiency and generation quality trade-offs, showing promising potential for practical applications. Code is available at \url{https://github.com/THU-MIG/PrefixKV}.
EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Oct 16, 2024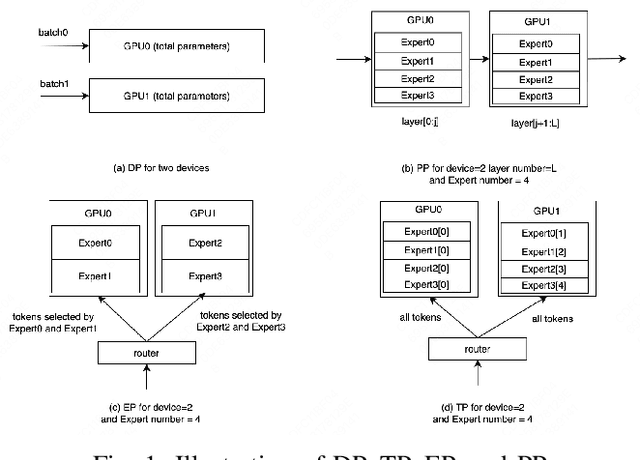
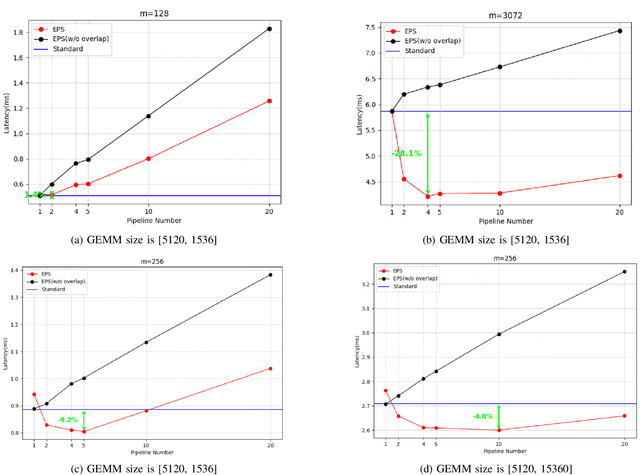
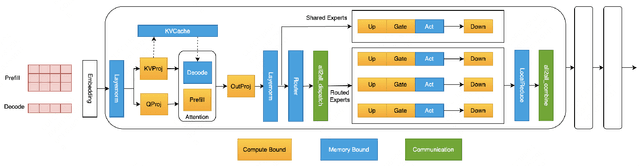
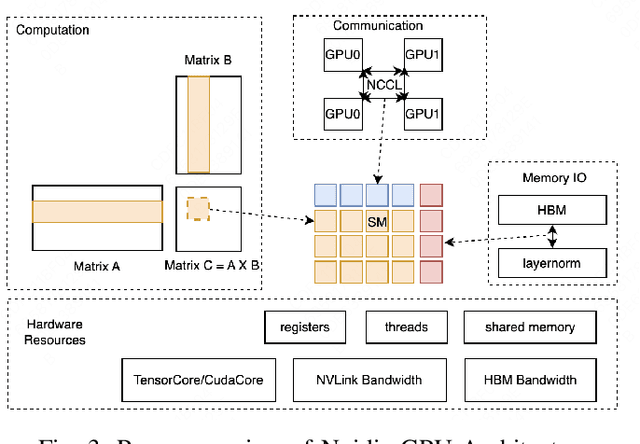
Large Language Model (LLM) has revolutionized the field of artificial intelligence, with their capabilities expanding rapidly due to advances in deep learning and increased computational resources. The mixture-of-experts (MoE) model has emerged as a prominent architecture in the field of LLM, better balancing the model performance and computational efficiency. MoE architecture allows for effective scaling and efficient parallel processing, but the GEMM (General Matrix Multiply) of MoE and the large parameters introduce challenges in terms of computation efficiency and communication overhead, which becomes the throughput bottleneck during inference. Applying a single parallelism strategy like EP, DP, PP, etc. to MoE architecture usually achieves sub-optimal inference throughput, the straightforward combinations of existing different parallelisms on MoE can not obtain optimal inference throughput yet. This paper introduces EPS-MoE, a novel expert pipeline scheduler for MoE that goes beyond the existing inference parallelism schemes. Our approach focuses on optimizing the computation of MoE FFN (FeedForward Network) modules by dynamically selecting the best kernel implementation of GroupGemm and DenseGemm for different loads and adaptively overlapping these computations with \textit{all2all} communication, leading to a substantial increase in throughput. Our experimental results demonstrate an average 21% improvement in prefill throughput over existing parallel inference methods. Specifically, we validated our method on DeepSeekV2, a highly optimized model claimed to achieve a prefill throughput of 100K tokens per second. By applying EPS-MoE, we further accelerated it to at least 120K tokens per second.
Optimizing AD Pruning of Sponsored Search with Reinforcement Learning
Aug 05, 2020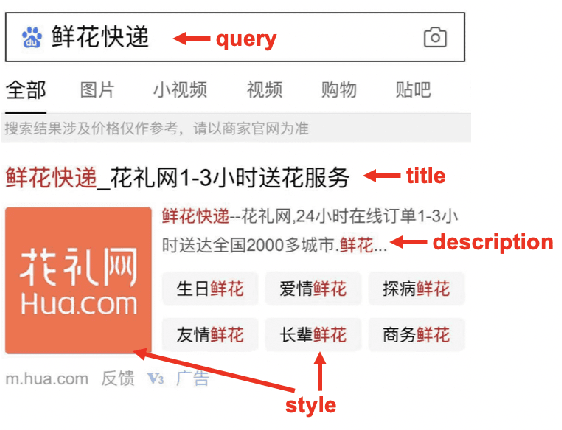

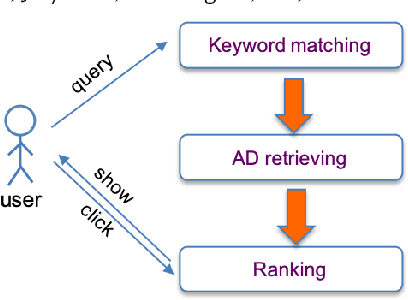
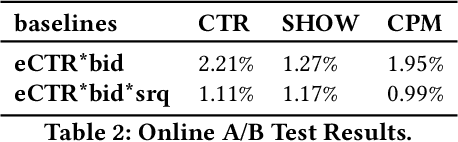
Industrial sponsored search system (SSS) can be logically divided into three modules: keywords matching, ad retrieving, and ranking. During ad retrieving, the ad candidates grow exponentially. A query with high commercial value might retrieve a great deal of ad candidates such that the ranking module could not afford. Due to limited latency and computing resources, the candidates have to be pruned earlier. Suppose we set a pruning line to cut SSS into two parts: upstream and downstream. The problem we are going to address is: how to pick out the best $K$ items from $N$ candidates provided by the upstream to maximize the total system's revenue. Since the industrial downstream is very complicated and updated quickly, a crucial restriction in this problem is that the selection scheme should get adapted to the downstream. In this paper, we propose a novel model-free reinforcement learning approach to fixing this problem. Our approach considers downstream as a black-box environment, and the agent sequentially selects items and finally feeds into the downstream, where revenue would be estimated and used as a reward to improve the selection policy. To the best of our knowledge, this is first time to consider the system optimization from a downstream adaption view. It is also the first time to use reinforcement learning techniques to tackle this problem. The idea has been successfully realized in Baidu's sponsored search system, and online long time A/B test shows remarkable improvements on revenue.