 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskPrune: Mask-based LLM Pruning for Layer-wise Uniform Structures
Paper and Code
Feb 19, 2025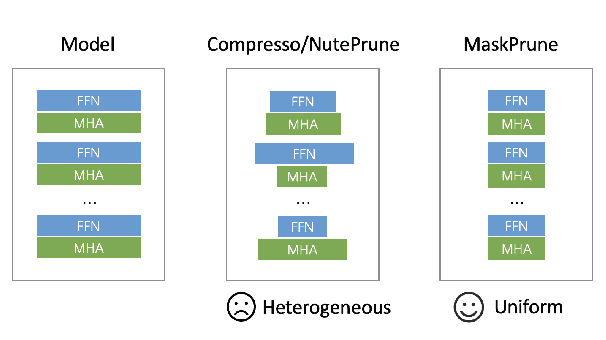
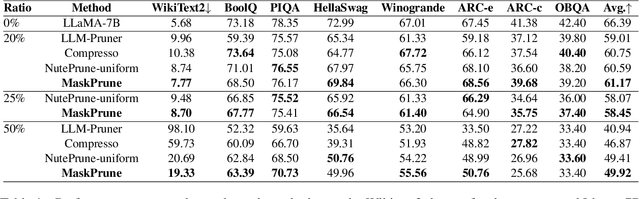
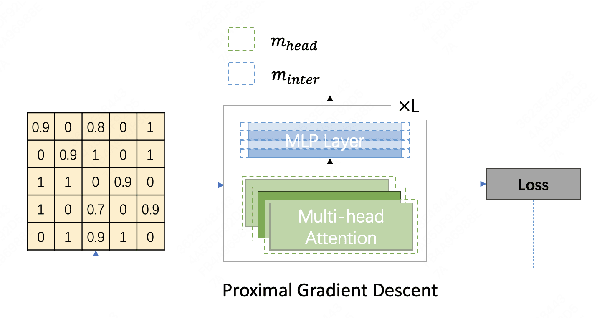

The remarkable performance of large language models (LLMs) in various language tasks has attracted considerable attention. However, the ever-increasing size of these models presents growing challenges for deployment and inference. Structured pruning, an effective model compression technique, is gaining increasing attention due to its ability to enhance inference efficiency. Nevertheless, most previous optimization-based structured pruning methods sacrifice the uniform structure across layers for greater flexibility to maintain performance. The heterogeneous structure hinders the effective utilization of off-the-shelf inference acceleration techniques and impedes efficient configuration for continued training. To address this issue, we propose a novel masking learning paradigm based on minimax optimization to obtain the uniform pruned structure by optimizing the masks under sparsity regularization. Extensive experimental results demonstrate that our method can maintain high performance while ensuring the uniformity of the pruned model structure, thereby outperforming existing SOTA methods.