 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncTLS: Efficient Generative LLM Inference with Asynchronous Two-level Sparse Attention
Apr 09, 2026Long-context inference in LLMs faces the dual challenges of quadratic attention complexity and prohibitive KV cache memory. While token-level sparse attention offers superior accuracy, its indexing overhead is costly; block-level methods improve efficiency but sacrifice precision. We propose AsyncTLS, a hierarchical sparse attention system that combines coarse-grained block filtering with fine-grained token selection to balance accuracy and efficiency, coupled with an asynchronous offloading engine that overlaps KV cache transfers with computation via temporal locality exploitation. Evaluated on Qwen3 and GLM-4.7-Flash across GQA, and MLA architectures, AsyncTLS achieves accuracy comparable to full attention while delivering 1.2x - 10.0x operator speedups and 1.3x - 4.7x end-to-end throughput improvements on 48k - 96k contexts.
AFA-LoRA: Enabling Non-Linear Adaptations in LoRA with Activation Function Annealing
Dec 27, 2025Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient fine-tuning (PEFT) method. However, its linear adaptation process limits its expressive power. This means there is a gap between the expressive power of linear training and non-linear training. To bridge this gap, we propose AFA-LoRA, a novel training strategy that brings non-linear expressivity to LoRA while maintaining its seamless mergeability. Our key innovation is an annealed activation function that transitions from a non-linear to a linear transformation during training, allowing the adapter to initially adopt stronger representational capabilities before converging to a mergeable linear form. We implement our method on supervised fine-tuning, reinforcement learning, and speculative decoding. The results show that AFA-LoRA reduces the performance gap between LoRA and full-parameter training. This work enables a more powerful and practical paradigm of parameter-efficient adaptation.
Accelerate Speculative Decoding with Sparse Computation in Verification
Dec 26, 2025Speculative decoding accelerates autoregressive language model inference by verifying multiple draft tokens in parallel. However, the verification stage often becomes the dominant computational bottleneck, especially for long-context inputs and mixture-of-experts (MoE) models. Existing sparsification methods are designed primarily for standard token-by-token autoregressive decoding to remove substantial computational redundancy in LLMs. This work systematically adopts different sparse methods on the verification stage of the speculative decoding and identifies structured redundancy across multiple dimensions. Based on these observations, we propose a sparse verification framework that jointly sparsifies attention, FFN, and MoE components during the verification stage to reduce the dominant computation cost. The framework further incorporates an inter-draft token and inter-layer retrieval reuse strategy to further reduce redundant computation without introducing additional training. Extensive experiments across summarization, question answering, and mathematical reasoning datasets demonstrate that the proposed methods achieve favorable efficiency-accuracy trade-offs, while maintaining stable acceptance length.
C2T: A Classifier-Based Tree Construction Method in Speculative Decoding
Feb 19, 2025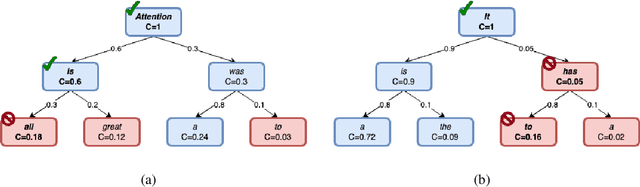
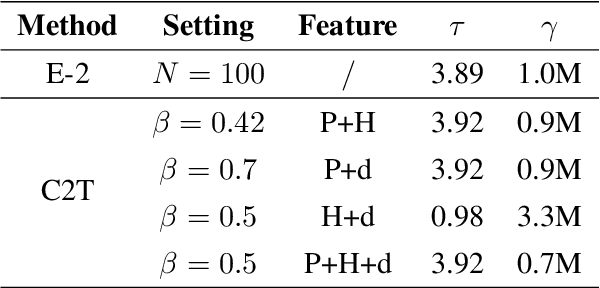

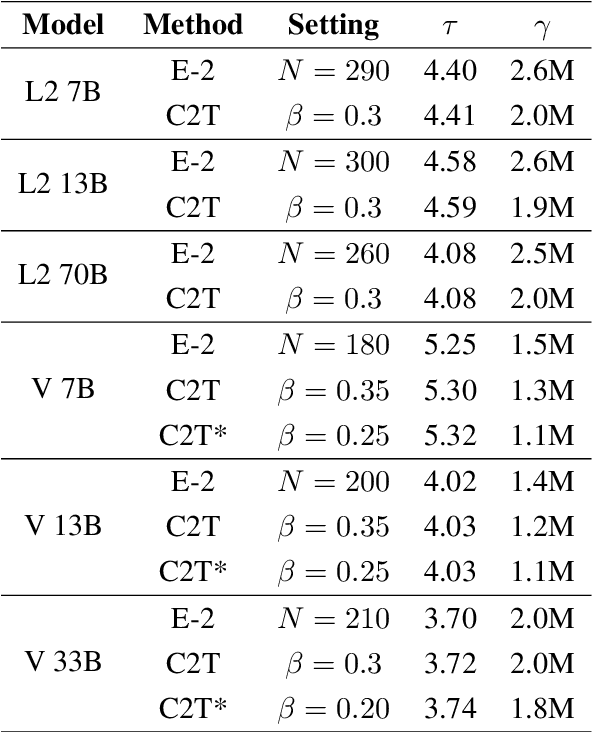
The growing scale of Large Language Models (LLMs) has exacerbated inference latency and computational costs. Speculative decoding methods, which aim to mitigate these issues, often face inefficiencies in the construction of token trees and the verification of candidate tokens. Existing strategies, including chain mode, static tree, and dynamic tree approaches, have limitations in accurately preparing candidate token trees for verification. We propose a novel method named C2T that adopts a lightweight classifier to generate and prune token trees dynamically. Our classifier considers additional feature variables beyond the commonly used joint probability to predict the confidence score for each draft token to determine whether it is the candidate token for verification. This method outperforms state-of-the-art (SOTA) methods such as EAGLE-2 on multiple benchmarks, by reducing the total number of candidate tokens by 25% while maintaining or even improving the acceptance length.
MaskPrune: Mask-based LLM Pruning for Layer-wise Uniform Structures
Feb 19, 2025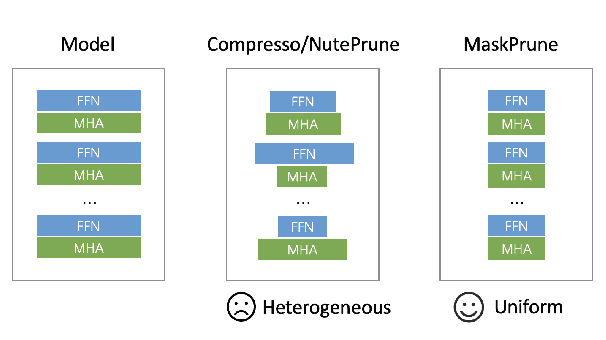
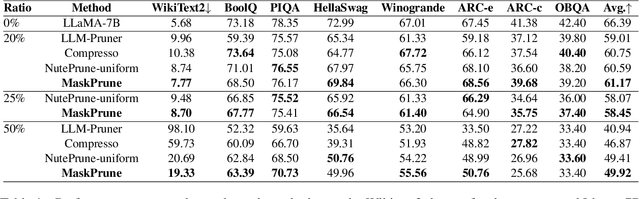
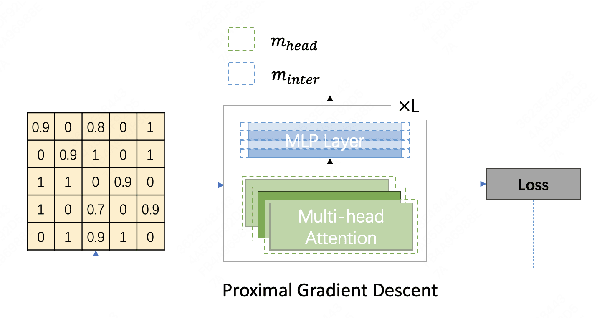

The remarkable performance of large language models (LLMs) in various language tasks has attracted considerable attention. However, the ever-increasing size of these models presents growing challenges for deployment and inference. Structured pruning, an effective model compression technique, is gaining increasing attention due to its ability to enhance inference efficiency. Nevertheless, most previous optimization-based structured pruning methods sacrifice the uniform structure across layers for greater flexibility to maintain performance. The heterogeneous structure hinders the effective utilization of off-the-shelf inference acceleration techniques and impedes efficient configuration for continued training. To address this issue, we propose a novel masking learning paradigm based on minimax optimization to obtain the uniform pruned structure by optimizing the masks under sparsity regularization. Extensive experimental results demonstrate that our method can maintain high performance while ensuring the uniformity of the pruned model structure, thereby outperforming existing SOTA methods.
PrefixKV: Adaptive Prefix KV Cache is What Vision Instruction-Following Models Need for Efficient Generation
Dec 04, 2024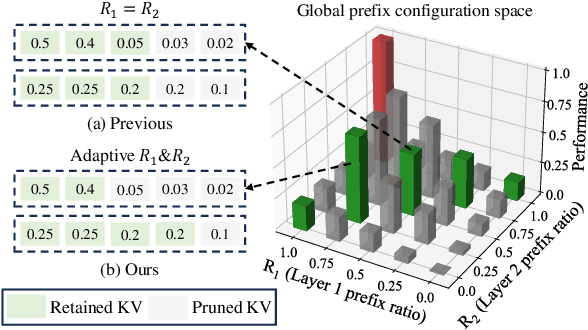

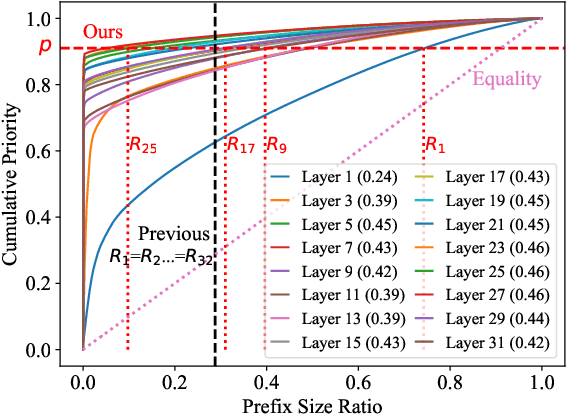

Recently, large vision-language models (LVLMs) have rapidly gained popularity for their strong generation and reasoning capabilities given diverse multimodal inputs. However, these models incur significant computational and memory overhead during inference, which greatly hinders the efficient deployment in practical scenarios. The extensive key-value (KV) cache, necessitated by the lengthy input and output sequences, notably contributes to the high inference cost. Based on this, recent works have investigated ways to reduce the KV cache size for higher efficiency. Although effective, they generally overlook the distinct importance distributions of KV vectors across layers and maintain the same cache size for each layer during the next token prediction. This results in the significant contextual information loss for certain layers, leading to notable performance decline. To address this, we present PrefixKV. It reframes the challenge of determining KV cache sizes for all layers into the task of searching for the optimal global prefix configuration. With an adaptive layer-wise KV retention recipe based on binary search, the maximum contextual information can thus be preserved in each layer, facilitating the generation. Extensive experiments demonstrate that our method achieves the state-of-the-art performance compared with others. It exhibits superior inference efficiency and generation quality trade-offs, showing promising potential for practical applications. Code is available at \url{https://github.com/THU-MIG/PrefixKV}.
EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Oct 16, 2024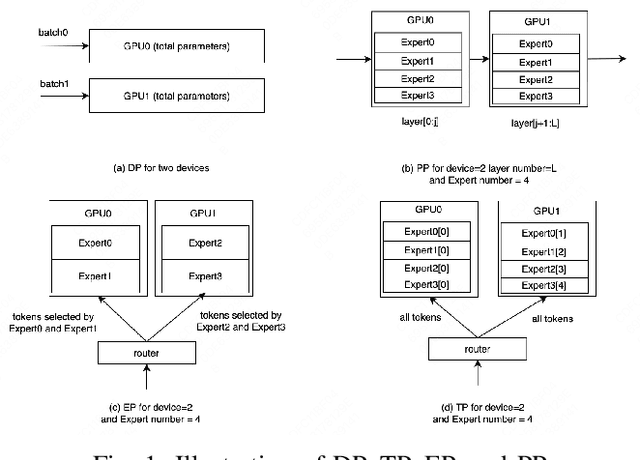
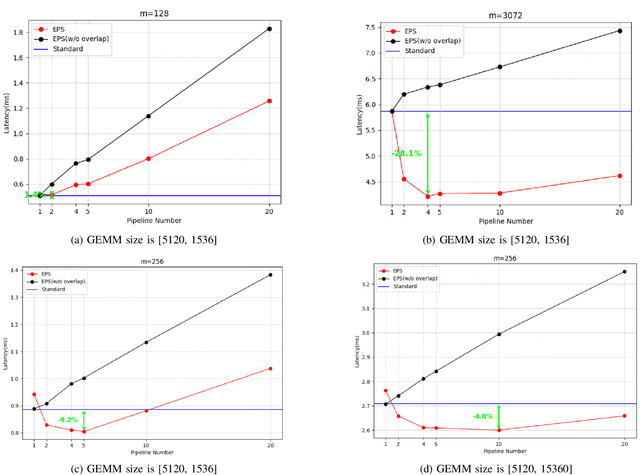
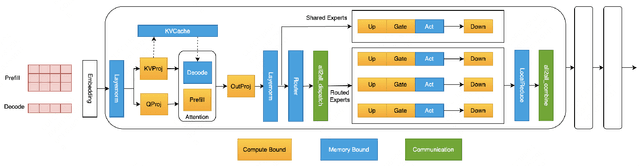
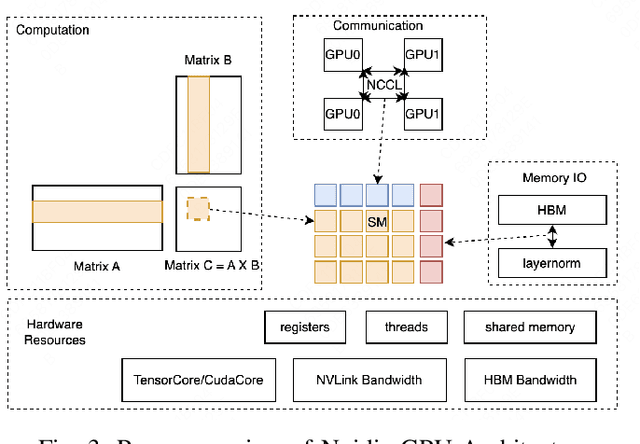
Large Language Model (LLM) has revolutionized the field of artificial intelligence, with their capabilities expanding rapidly due to advances in deep learning and increased computational resources. The mixture-of-experts (MoE) model has emerged as a prominent architecture in the field of LLM, better balancing the model performance and computational efficiency. MoE architecture allows for effective scaling and efficient parallel processing, but the GEMM (General Matrix Multiply) of MoE and the large parameters introduce challenges in terms of computation efficiency and communication overhead, which becomes the throughput bottleneck during inference. Applying a single parallelism strategy like EP, DP, PP, etc. to MoE architecture usually achieves sub-optimal inference throughput, the straightforward combinations of existing different parallelisms on MoE can not obtain optimal inference throughput yet. This paper introduces EPS-MoE, a novel expert pipeline scheduler for MoE that goes beyond the existing inference parallelism schemes. Our approach focuses on optimizing the computation of MoE FFN (FeedForward Network) modules by dynamically selecting the best kernel implementation of GroupGemm and DenseGemm for different loads and adaptively overlapping these computations with \textit{all2all} communication, leading to a substantial increase in throughput. Our experimental results demonstrate an average 21% improvement in prefill throughput over existing parallel inference methods. Specifically, we validated our method on DeepSeekV2, a highly optimized model claimed to achieve a prefill throughput of 100K tokens per second. By applying EPS-MoE, we further accelerated it to at least 120K tokens per second.
CountFormer: Multi-View Crowd Counting Transformer
Jul 02, 2024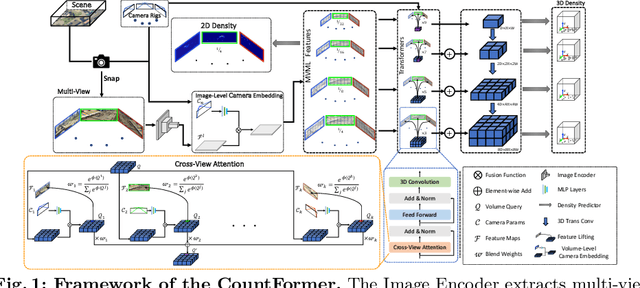


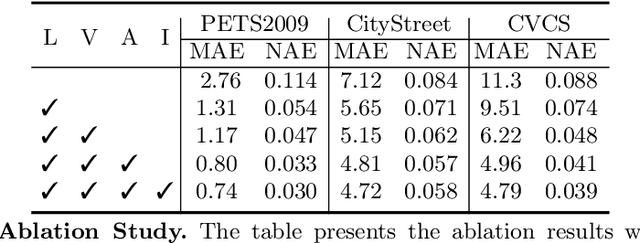
Multi-view counting (MVC) methods have shown their superiority over single-view counterparts, particularly in situations characterized by heavy occlusion and severe perspective distortions. However, hand-crafted heuristic features and identical camera layout requirements in conventional MVC methods limit their applicability and scalability in real-world scenarios.In this work, we propose a concise 3D MVC framework called \textbf{CountFormer}to elevate multi-view image-level features to a scene-level volume representation and estimate the 3D density map based on the volume features. By incorporating a camera encoding strategy, CountFormer successfully embeds camera parameters into the volume query and image-level features, enabling it to handle various camera layouts with significant differences.Furthermore, we introduce a feature lifting module capitalized on the attention mechanism to transform image-level features into a 3D volume representation for each camera view. Subsequently, the multi-view volume aggregation module attentively aggregates various multi-view volumes to create a comprehensive scene-level volume representation, allowing CountFormer to handle images captured by arbitrary dynamic camera layouts. The proposed method performs favorably against the state-of-the-art approaches across various widely used datasets, demonstrating its greater suitability for real-world deployment compared to conventional MVC frameworks.
ASP: Automatic Selection of Proxy dataset for efficient AutoML
Oct 17, 2023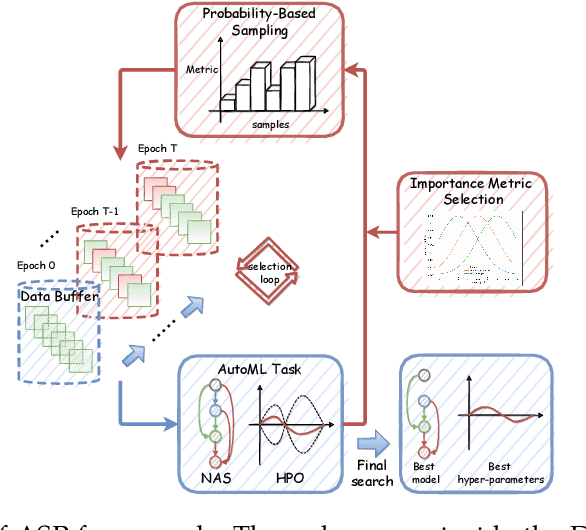
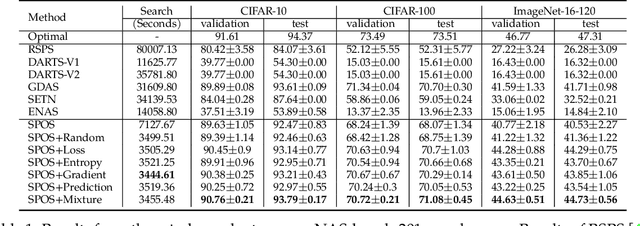
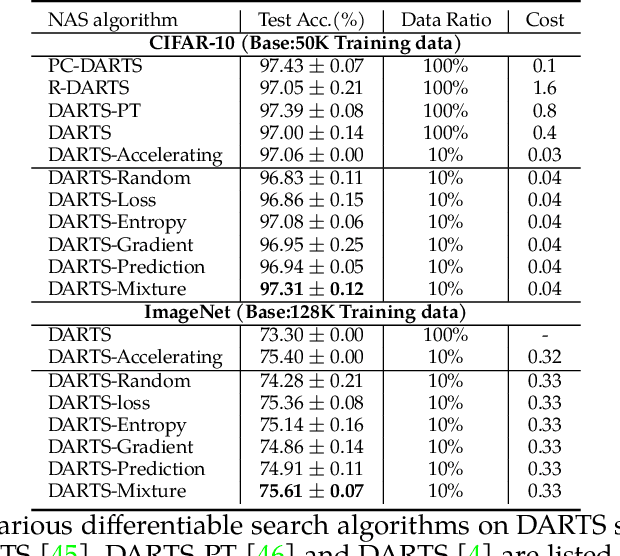
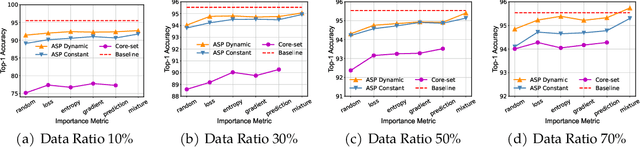
Deep neural networks have gained great success due to the increasing amounts of data, and diverse effective neural network designs. However, it also brings a heavy computing burden as the amount of training data is proportional to the training time. In addition, a well-behaved model requires repeated trials of different structure designs and hyper-parameters, which may take a large amount of time even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms and neural architecture search (NAS) algorithms. In this paper, we propose an Automatic Selection of Proxy dataset framework (ASP) aimed to dynamically find the informative proxy subsets of training data at each epoch, reducing the training data size as well as saving the AutoML processing time. We verify the effectiveness and generalization of ASP on CIFAR10, CIFAR100, ImageNet16-120, and ImageNet-1k, across various public model benchmarks. The experiment results show that ASP can obtain better results than other data selection methods at all selection ratios. ASP can also enable much more efficient AutoML processing with a speedup of 2x-20x while obtaining better architectures and better hyper-parameters compared to utilizing the entire dataset.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023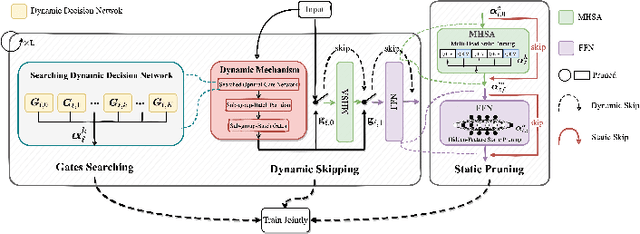
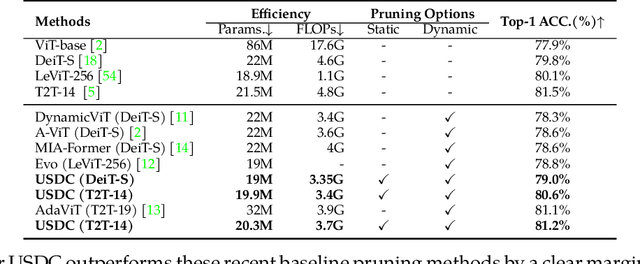
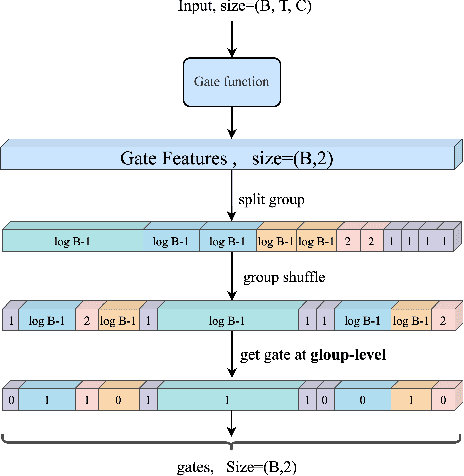
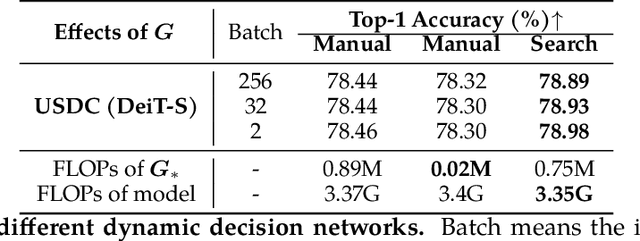
Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.