 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Paper and Code
Oct 16, 2024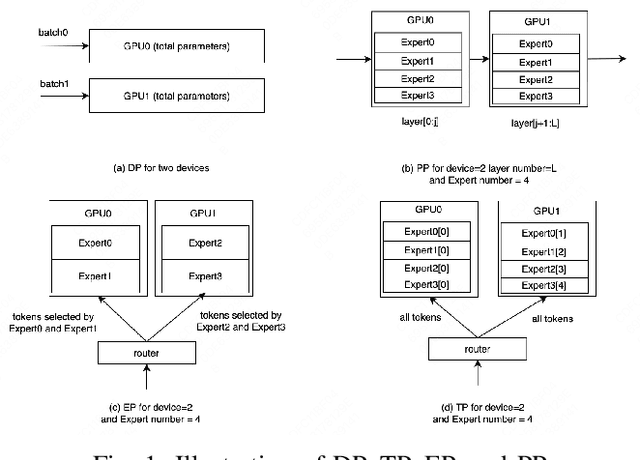
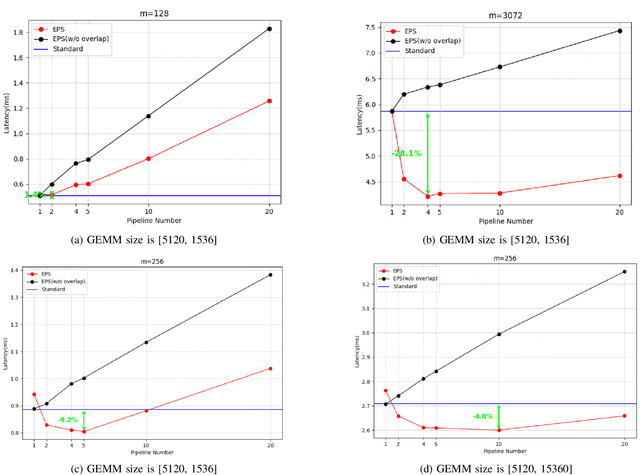
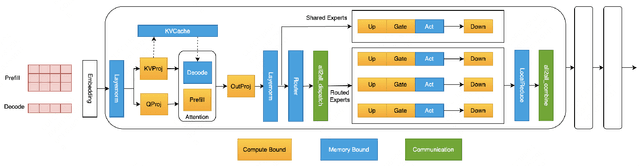
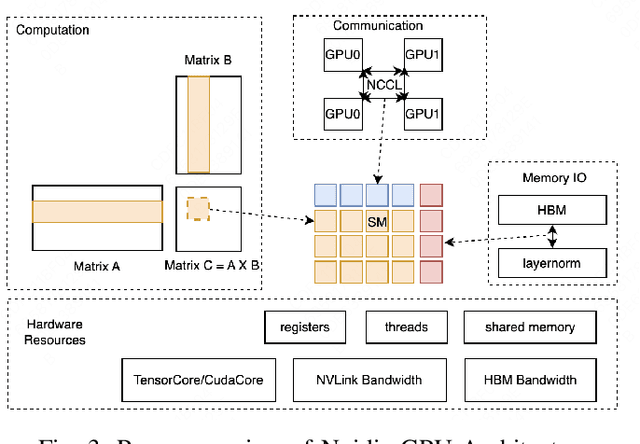
Large Language Model (LLM) has revolutionized the field of artificial intelligence, with their capabilities expanding rapidly due to advances in deep learning and increased computational resources. The mixture-of-experts (MoE) model has emerged as a prominent architecture in the field of LLM, better balancing the model performance and computational efficiency. MoE architecture allows for effective scaling and efficient parallel processing, but the GEMM (General Matrix Multiply) of MoE and the large parameters introduce challenges in terms of computation efficiency and communication overhead, which becomes the throughput bottleneck during inference. Applying a single parallelism strategy like EP, DP, PP, etc. to MoE architecture usually achieves sub-optimal inference throughput, the straightforward combinations of existing different parallelisms on MoE can not obtain optimal inference throughput yet. This paper introduces EPS-MoE, a novel expert pipeline scheduler for MoE that goes beyond the existing inference parallelism schemes. Our approach focuses on optimizing the computation of MoE FFN (FeedForward Network) modules by dynamically selecting the best kernel implementation of GroupGemm and DenseGemm for different loads and adaptively overlapping these computations with \textit{all2all} communication, leading to a substantial increase in throughput. Our experimental results demonstrate an average 21% improvement in prefill throughput over existing parallel inference methods. Specifically, we validated our method on DeepSeekV2, a highly optimized model claimed to achieve a prefill throughput of 100K tokens per second. By applying EPS-MoE, we further accelerated it to at least 120K tokens per second.