 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond
May 19, 2026The rapid advancement toward long-context reasoning and multi-modal intelligence has made the memory footprint of the Key-Value (KV) cache a dominant memory bottleneck for efficient deployment. While the established per-channel quantization effectively accommodates intrinsic channel-wise outliers in Key tensors, its efficacy diminishes under extreme compression. In this work, we revisit the inherent limitations of the per-channel quantization paradigm from both empirical and theoretical perspectives. Our analysis identifies Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity. We demonstrate that TNI systematically amplifies errors when shared quantization parameters are required to span token groups exhibiting substantial norm disparities. Instead of relying on intricate quantization pipelines (e.g., TurboQuant), we propose OScaR (Omni-Scaled Canalized Rotation), an accurate and lightweight KV cache compression framework for X-LLMs (i.e., text-only, multi-modal, and omni-modal LLMs). Advancing the per-channel paradigm, OScaR employs Canalized Rotation followed by Omni-Token Scaling to mitigate TNI-induced sequence-dimensional variance both effectively and efficiently, further supported by our optimized system design and CUDA kernels. Extensive evaluations across X-LLMs show that OScaR consistently outperforms existing methods and achieves near-lossless performance under INT2 quantization, establishing it as a robust, low-complexity, and universal framework that defines a new Pareto front. Compared with the BF16 FlashDecoding-v2 baseline, our OScaR implementation achieves a notable up to 3.0x speedup in decoding, reduces memory footprint by 5.3x, and increases throughput by 4.1x. The code for OScaR is publicly available at https://github.com/ZunhaiSu/OScaR-KV-Quant.
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Apr 11, 2026As the foundational architecture of modern machine learning, Transformers have driven remarkable progress across diverse AI domains. Despite their transformative impact, a persistent challenge across various Transformers is Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens. AS complicates interpretability, significantly affecting the training and inference dynamics, and exacerbates issues such as hallucinations. In recent years, substantial research has been dedicated to understanding and harnessing AS. However, a comprehensive survey that systematically consolidates AS-related research and offers guidance for future advancements remains lacking. To address this gap, we present the first survey on AS, structured around three key dimensions that define the current research landscape: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation. Our work provides a pivotal contribution by clarifying key concepts and guiding researchers through the evolution and trends of the field. We envision this survey as a definitive resource, empowering researchers and practitioners to effectively manage AS within the current Transformer paradigm, while simultaneously inspiring innovative advancements for the next generation of Transformers. The paper list of this work is available at https://github.com/ZunhaiSu/Awesome-Attention-Sink.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
Feb 12, 2026While FP8 attention has shown substantial promise in innovations like FlashAttention-3, its integration into the decoding phase of the DeepSeek Multi-head Latent Attention (MLA) architecture presents notable challenges. These challenges include numerical heterogeneity arising from the decoupling of positional embeddings, misalignment of quantization scales in FP8 PV GEMM, and the need for optimized system-level support. In this paper, we introduce SnapMLA, an FP8 MLA decoding framework optimized to improve long-context efficiency through the following hardware-aware algorithm-kernel co-optimization techniques: (i) RoPE-Aware Per-Token KV Quantization, where the RoPE part is maintained in high precision, motivated by our comprehensive analysis of the heterogeneous quantization sensitivity inherent to the MLA KV cache. Furthermore, per-token granularity is employed to align with the autoregressive decoding process and maintain quantization accuracy. (ii) Quantized PV Computation Pipeline Reconstruction, which resolves the misalignment of quantization scale in FP8 PV computation stemming from the shared KV structure of the MLA KV cache. (iii) End-to-End Dataflow Optimization, where we establish an efficient data read-and-write workflow using specialized kernels, ensuring efficient data flow and performance gains. Extensive experiments on state-of-the-art MLA LLMs show that SnapMLA achieves up to a 1.91x improvement in throughput, with negligible risk of performance degradation in challenging long-context tasks, including mathematical reasoning and code generation benchmarks. Code is available at https://github.com/meituan-longcat/SGLang-FluentLLM.
Scaling Embeddings Outperforms Scaling Experts in Language Models
Jan 29, 2026While Mixture-of-Experts (MoE) architectures have become the standard for sparsity scaling in large language models, they increasingly face diminishing returns and system-level bottlenecks. In this work, we explore embedding scaling as a potent, orthogonal dimension for scaling sparsity. Through a comprehensive analysis and experiments, we identify specific regimes where embedding scaling achieves a superior Pareto frontier compared to expert scaling. We systematically characterize the critical architectural factors governing this efficacy -- ranging from parameter budgeting to the interplay with model width and depth. Moreover, by integrating tailored system optimizations and speculative decoding, we effectively convert this sparsity into tangible inference speedups. Guided by these insights, we introduce LongCat-Flash-Lite, a 68.5B parameter model with ~3B activated trained from scratch. Despite allocating over 30B parameters to embeddings, LongCat-Flash-Lite not only surpasses parameter-equivalent MoE baselines but also exhibits exceptional competitiveness against existing models of comparable scale, particularly in agentic and coding domains.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Efficient Context Scaling with LongCat ZigZag Attention
Dec 30, 2025We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Oct 16, 2024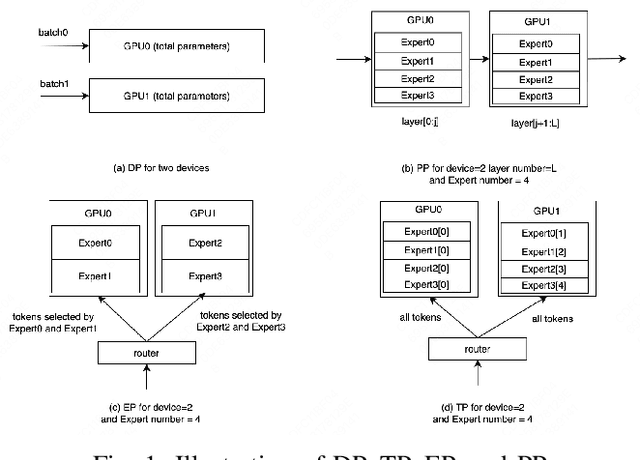
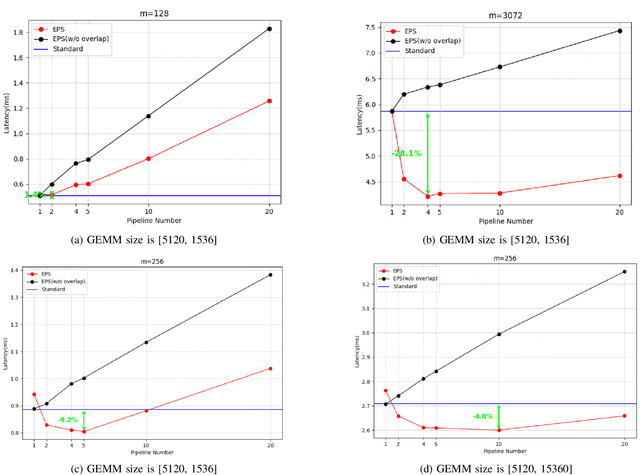
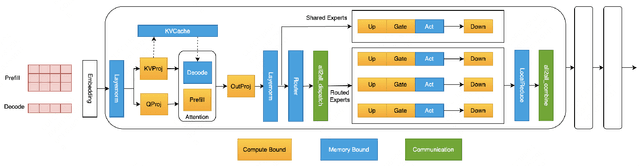
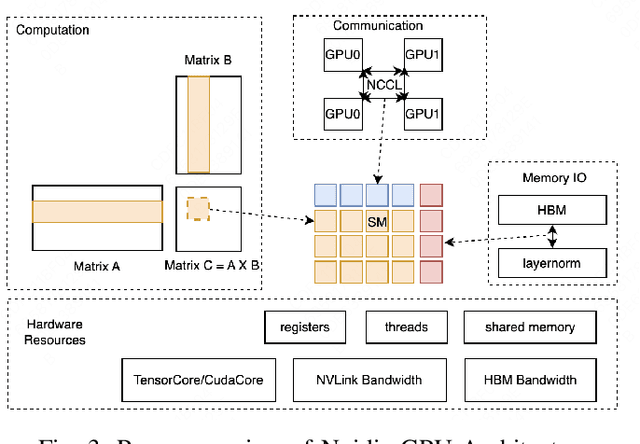
Large Language Model (LLM) has revolutionized the field of artificial intelligence, with their capabilities expanding rapidly due to advances in deep learning and increased computational resources. The mixture-of-experts (MoE) model has emerged as a prominent architecture in the field of LLM, better balancing the model performance and computational efficiency. MoE architecture allows for effective scaling and efficient parallel processing, but the GEMM (General Matrix Multiply) of MoE and the large parameters introduce challenges in terms of computation efficiency and communication overhead, which becomes the throughput bottleneck during inference. Applying a single parallelism strategy like EP, DP, PP, etc. to MoE architecture usually achieves sub-optimal inference throughput, the straightforward combinations of existing different parallelisms on MoE can not obtain optimal inference throughput yet. This paper introduces EPS-MoE, a novel expert pipeline scheduler for MoE that goes beyond the existing inference parallelism schemes. Our approach focuses on optimizing the computation of MoE FFN (FeedForward Network) modules by dynamically selecting the best kernel implementation of GroupGemm and DenseGemm for different loads and adaptively overlapping these computations with \textit{all2all} communication, leading to a substantial increase in throughput. Our experimental results demonstrate an average 21% improvement in prefill throughput over existing parallel inference methods. Specifically, we validated our method on DeepSeekV2, a highly optimized model claimed to achieve a prefill throughput of 100K tokens per second. By applying EPS-MoE, we further accelerated it to at least 120K tokens per second.
Pick of the Bunch: Detecting Infrared Small Targets Beyond Hit-Miss Trade-Offs via Selective Rank-Aware Attention
Aug 07, 2024Infrared small target detection faces the inherent challenge of precisely localizing dim targets amidst complex background clutter. Traditional approaches struggle to balance detection precision and false alarm rates. To break this dilemma, we propose SeRankDet, a deep network that achieves high accuracy beyond the conventional hit-miss trade-off, by following the ``Pick of the Bunch'' principle. At its core lies our Selective Rank-Aware Attention (SeRank) module, employing a non-linear Top-K selection process that preserves the most salient responses, preventing target signal dilution while maintaining constant complexity. Furthermore, we replace the static concatenation typical in U-Net structures with our Large Selective Feature Fusion (LSFF) module, a dynamic fusion strategy that empowers SeRankDet with adaptive feature integration, enhancing its ability to discriminate true targets from false alarms. The network's discernment is further refined by our Dilated Difference Convolution (DDC) module, which merges differential convolution aimed at amplifying subtle target characteristics with dilated convolution to expand the receptive field, thereby substantially improving target-background separation. Despite its lightweight architecture, the proposed SeRankDet sets new benchmarks in state-of-the-art performance across multiple public datasets. The code is available at https://github.com/GrokCV/SeRankDet.
Sparse Prior Is Not All You Need: When Differential Directionality Meets Saliency Coherence for Infrared Small Target Detection
Jul 22, 2024Infrared small target detection is crucial for the efficacy of infrared search and tracking systems. Current tensor decomposition methods emphasize representing small targets with sparsity but struggle to separate targets from complex backgrounds due to insufficient use of intrinsic directional information and reduced target visibility during decomposition. To address these challenges, this study introduces a Sparse Differential Directionality prior (SDD) framework. SDD leverages the distinct directional characteristics of targets to differentiate them from the background, applying mixed sparse constraints on the differential directional images and continuity difference matrix of the temporal component, both derived from Tucker decomposition. We further enhance target detectability with a saliency coherence strategy that intensifies target contrast against the background during hierarchical decomposition. A Proximal Alternating Minimization-based (PAM) algorithm efficiently solves our proposed model. Experimental results on several real-world datasets validate our method's effectiveness, outperforming ten state-of-the-art methods in target detection and clutter suppression. Our code is available at https://github.com/GrokCV/SDD.