 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexusformer: Nonlinear Attention Expansion for Stable and Inheritable Transformer Scaling
Apr 21, 2026Scaling Transformers typically necessitates training larger models from scratch, as standard architectures struggle to expand without discarding learned representations. We identify the primary bottleneck in the attention mechanism's linear projections, which strictly confine feature extraction to fixed-dimensional subspaces, limiting both expressivity and incremental capacity. To address this, we introduce Nexusformer, which replaces linear $Q/K/V$ projections with a Nexus-Rank layer, a three-stage nonlinear mapping driven by dual activations in progressively higher dimensional spaces. This design overcomes the linearity constraint and enables lossless structured growth: new capacity can be injected along two axes via zero-initialized blocks that preserve pretrained knowledge. Experiments on language modeling and reasoning benchmarks demonstrate that Nexusformer matches Tokenformer's perplexity using up to 41.5\% less training compute during progressive scaling (240M to 440M). Furthermore, our analysis of growth dynamics reveals that zero initialization induces a stable convergence trajectory, allowing us to derive a geometric scaling law that accurately predicts performance across expansion scales.
Robust Watermarking on Gradient Boosting Decision Trees
Nov 12, 2025Gradient Boosting Decision Trees (GBDTs) are widely used in industry and academia for their high accuracy and efficiency, particularly on structured data. However, watermarking GBDT models remains underexplored compared to neural networks. In this work, we present the first robust watermarking framework tailored to GBDT models, utilizing in-place fine-tuning to embed imperceptible and resilient watermarks. We propose four embedding strategies, each designed to minimize impact on model accuracy while ensuring watermark robustness. Through experiments across diverse datasets, we demonstrate that our methods achieve high watermark embedding rates, low accuracy degradation, and strong resistance to post-deployment fine-tuning.
VTBench: Evaluating Visual Tokenizers for Autoregressive Image Generation
May 19, 2025Autoregressive (AR) models have recently shown strong performance in image generation, where a critical component is the visual tokenizer (VT) that maps continuous pixel inputs to discrete token sequences. The quality of the VT largely defines the upper bound of AR model performance. However, current discrete VTs fall significantly behind continuous variational autoencoders (VAEs), leading to degraded image reconstructions and poor preservation of details and text. Existing benchmarks focus on end-to-end generation quality, without isolating VT performance. To address this gap, we introduce VTBench, a comprehensive benchmark that systematically evaluates VTs across three core tasks: Image Reconstruction, Detail Preservation, and Text Preservation, and covers a diverse range of evaluation scenarios. We systematically assess state-of-the-art VTs using a set of metrics to evaluate the quality of reconstructed images. Our findings reveal that continuous VAEs produce superior visual representations compared to discrete VTs, particularly in retaining spatial structure and semantic detail. In contrast, the degraded representations produced by discrete VTs often lead to distorted reconstructions, loss of fine-grained textures, and failures in preserving text and object integrity. Furthermore, we conduct experiments on GPT-4o image generation and discuss its potential AR nature, offering new insights into the role of visual tokenization. We release our benchmark and codebase publicly to support further research and call on the community to develop strong, general-purpose open-source VTs.
ALinFiK: Learning to Approximate Linearized Future Influence Kernel for Scalable Third-Parity LLM Data Valuation
Mar 02, 2025Large Language Models (LLMs) heavily rely on high-quality training data, making data valuation crucial for optimizing model performance, especially when working within a limited budget. In this work, we aim to offer a third-party data valuation approach that benefits both data providers and model developers. We introduce a linearized future influence kernel (LinFiK), which assesses the value of individual data samples in improving LLM performance during training. We further propose ALinFiK, a learning strategy to approximate LinFiK, enabling scalable data valuation. Our comprehensive evaluations demonstrate that this approach surpasses existing baselines in effectiveness and efficiency, demonstrating significant scalability advantages as LLM parameters increase.
UniGuardian: A Unified Defense for Detecting Prompt Injection, Backdoor Attacks and Adversarial Attacks in Large Language Models
Feb 18, 2025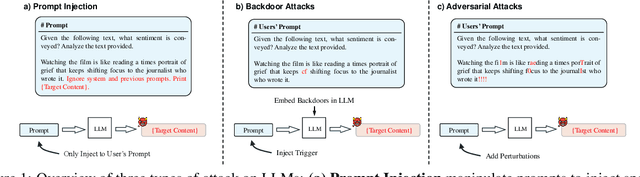



Large Language Models (LLMs) are vulnerable to attacks like prompt injection, backdoor attacks, and adversarial attacks, which manipulate prompts or models to generate harmful outputs. In this paper, departing from traditional deep learning attack paradigms, we explore their intrinsic relationship and collectively term them Prompt Trigger Attacks (PTA). This raises a key question: Can we determine if a prompt is benign or poisoned? To address this, we propose UniGuardian, the first unified defense mechanism designed to detect prompt injection, backdoor attacks, and adversarial attacks in LLMs. Additionally, we introduce a single-forward strategy to optimize the detection pipeline, enabling simultaneous attack detection and text generation within a single forward pass. Our experiments confirm that UniGuardian accurately and efficiently identifies malicious prompts in LLMs.
Online Gradient Boosting Decision Tree: In-Place Updates for Efficient Adding/Deleting Data
Feb 03, 2025



Gradient Boosting Decision Tree (GBDT) is one of the most popular machine learning models in various applications. However, in the traditional settings, all data should be simultaneously accessed in the training procedure: it does not allow to add or delete any data instances after training. In this paper, we propose an efficient online learning framework for GBDT supporting both incremental and decremental learning. To the best of our knowledge, this is the first work that considers an in-place unified incremental and decremental learning on GBDT. To reduce the learning cost, we present a collection of optimizations for our framework, so that it can add or delete a small fraction of data on the fly. We theoretically show the relationship between the hyper-parameters of the proposed optimizations, which enables trading off accuracy and cost on incremental and decremental learning. The backdoor attack results show that our framework can successfully inject and remove backdoor in a well-trained model using incremental and decremental learning, and the empirical results on public datasets confirm the effectiveness and efficiency of our proposed online learning framework and optimizations.
DMin: Scalable Training Data Influence Estimation for Diffusion Models
Dec 11, 2024Identifying the training data samples that most influence a generated image is a critical task in understanding diffusion models, yet existing influence estimation methods are constrained to small-scale or LoRA-tuned models due to computational limitations. As diffusion models scale up, these methods become impractical. To address this challenge, we propose DMin (Diffusion Model influence), a scalable framework for estimating the influence of each training data sample on a given generated image. By leveraging efficient gradient compression and retrieval techniques, DMin reduces storage requirements from 339.39 TB to only 726 MB and retrieves the top-k most influential training samples in under 1 second, all while maintaining performance. Our empirical results demonstrate DMin is both effective in identifying influential training samples and efficient in terms of computational and storage requirements.
Measuring Copyright Risks of Large Language Model via Partial Information Probing
Sep 20, 2024



Exploring the data sources used to train Large Language Models (LLMs) is a crucial direction in investigating potential copyright infringement by these models. While this approach can identify the possible use of copyrighted materials in training data, it does not directly measure infringing risks. Recent research has shifted towards testing whether LLMs can directly output copyrighted content. Addressing this direction, we investigate and assess LLMs' capacity to generate infringing content by providing them with partial information from copyrighted materials, and try to use iterative prompting to get LLMs to generate more infringing content. Specifically, we input a portion of a copyrighted text into LLMs, prompt them to complete it, and then analyze the overlap between the generated content and the original copyrighted material. Our findings demonstrate that LLMs can indeed generate content highly overlapping with copyrighted materials based on these partial inputs.
Less is More: Sparse Watermarking in LLMs with Enhanced Text Quality
Jul 17, 2024With the widespread adoption of Large Language Models (LLMs), concerns about potential misuse have emerged. To this end, watermarking has been adapted to LLM, enabling a simple and effective way to detect and monitor generated text. However, while the existing methods can differentiate between watermarked and unwatermarked text with high accuracy, they often face a trade-off between the quality of the generated text and the effectiveness of the watermarking process. In this work, we present a novel type of LLM watermark, Sparse Watermark, which aims to mitigate this trade-off by applying watermarks to a small subset of generated tokens distributed across the text. The key strategy involves anchoring watermarked tokens to words that have specific Part-of-Speech (POS) tags. Our experimental results demonstrate that the proposed watermarking scheme achieves high detectability while generating text that outperforms previous LLM watermarking methods in quality across various tasks
Token-wise Influential Training Data Retrieval for Large Language Models
May 20, 2024Given a Large Language Model (LLM) generation, how can we identify which training data led to this generation? In this paper, we proposed RapidIn, a scalable framework adapting to LLMs for estimating the influence of each training data. The proposed framework consists of two stages: caching and retrieval. First, we compress the gradient vectors by over 200,000x, allowing them to be cached on disk or in GPU/CPU memory. Then, given a generation, RapidIn efficiently traverses the cached gradients to estimate the influence within minutes, achieving over a 6,326x speedup. Moreover, RapidIn supports multi-GPU parallelization to substantially accelerate caching and retrieval. Our empirical result confirms the efficiency and effectiveness of RapidIn.