 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Right Rollouts: Data Attribution for PPO-based LLM Post-Training
Apr 02, 2026Traditional RL algorithms like Proximal Policy Optimization (PPO) typically train on the entire rollout buffer, operating under the assumption that all generated episodes provide a beneficial optimization signal. However, these episodes frequently contain noisy or unfaithful reasoning, which can degrade model performance and slow down training. In this paper, we propose \textbf{Influence-Guided PPO (I-PPO)}, a novel framework that integrates data attribution into the RL post-training loop. By calculating an influence score for each episode using a gradient-based approximation, I-PPO identifies and eliminates episodes that are anti-aligned with a validation gradient. Our experiments demonstrate that I-PPO consistently outperforms SFT and PPO baselines. We show that our filtering process acts as an intrinsic early stopping mechanism, accelerating training efficiency while effectively reducing unfaithful CoT reasoning.
Causally-Guided Diffusion for Stable Feature Selection
Mar 21, 2026Feature selection is fundamental to robust data-centric AI, but most existing methods optimize predictive performance under a single data distribution. This often selects spurious features that fail under distribution shifts. Motivated by principles from causal invariance, we study feature selection from a stability perspective and introduce Causally-Guided Diffusion for Stable Feature Selection (CGDFS). In CGDFS, we formalized feature selection as approximate posterior inference over feature subsets, whose posterior mass favors low prediction error and low cross-environment variance. Our framework combines three key insights: First, we formulate feature selection as stability-aware posterior sampling. Here, causal invariance serves as a soft inductive bias rather than explicit causal discovery. Second, we train a diffusion model as a learned prior over plausible continuous selection masks, combined with a stability-aware likelihood that rewards invariance across environments. This diffusion prior captures structural dependencies among features and enables scalable exploration of the combinatorially large selection space. Third, we perform guided annealed Langevin sampling that combines the diffusion prior with the stability objective, which yields a tractable, uncertainty-aware posterior inference that avoids discrete optimization and produces robust feature selections. We evaluate CGDFS on open-source real-world datasets exhibiting distribution shifts. Across both classification and regression tasks, CGDFS consistently selects more stable and transferable feature subsets, which leads to improved out-of-distribution performance and greater selection robustness compared to sparsity-based, tree-based, and stability-selection baselines.
FinRule-Bench: A Benchmark for Joint Reasoning over Financial Tables and Principles
Mar 11, 2026Large language models (LLMs) are increasingly applied to financial analysis, yet their ability to audit structured financial statements under explicit accounting principles remains poorly explored. Existing benchmarks primarily evaluate question answering, numerical reasoning, or anomaly detection on synthetically corrupted data, making it unclear whether models can reliably verify or localize rule compliance on correct financial statements. We introduce FinRule-Bench, a benchmark for evaluating diagnostic completeness in rule-based financial reasoning over real-world financial tables. FinRule-Bench pairs ground-truth financial statements with explicit, human-curated accounting principles and spans four canonical statement types: Balance Sheets, Cash Flow Statements, Income Statements, and Statements of Equity. The benchmark defines three auditing tasks that require progressively stronger reasoning capabilities: (i) rule verification, which tests compliance with a single principle; (ii) rule identification, which requires selecting the violated principle from a provided rule set; and (iii) joint rule diagnosis, which requires detecting and localizing multiple simultaneous violations at the record level. We evaluate LLMs under zero-shot and few-shot prompting, and introduce a causal-counterfactual reasoning protocol that enforces consistency between decisions, explanations, and counterfactual judgments. Across tasks and statement types, we find that while models perform well on isolated rule verification, performance degrades sharply for rule discrimination and multi-violation diagnosis. FinRule-Bench provides a principled and reproducible testbed for studying rule-governed reasoning, diagnostic coverage, and failure modes of LLMs in high-stakes financial analysis.
OSExpert: Computer-Use Agents Learning Professional Skills via Exploration
Mar 09, 2026General-purpose computer-use agents have shown impressive performance across diverse digital environments. However, our new benchmark, OSExpert-Eval, indicates they remain far less helpful than human experts. Although inference-time scaling enables adaptation, these agents complete complex tasks inefficiently with degraded performance, transfer poorly to unseen UIs, and struggle with fine-grained action sequences. To solve the problem, we introduce a GUI-based depth-first search (GUI-DFS) exploration algorithm to comprehensively explore and verify an environment's unit functions. The agent then exploits compositionality between unit skills to self-construct a curriculum for composite tasks. To support fine-grained actions, we curate a database of action primitives for agents to discover during exploration; these are saved as a skill set once the exploration is complete. We use the learned skills to improve the agent's performance and efficiency by (1) enriching agents with ready-to-use procedural knowledge, allowing them to plan only once for long trajectories and generate accurate actions, and (2) enabling them to end inference-time scaling earlier by realizing their boundary of capabilities. Extensive experiments show that our environment-learned agent takes a meaningful step toward expert-level computer use, achieving a around 20 percent performance gain on OSExpert-Eval and closing the efficiency gap to humans by around 80 percent
Copyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
ISACL: Internal State Analyzer for Copyrighted Training Data Leakage
Aug 25, 2025
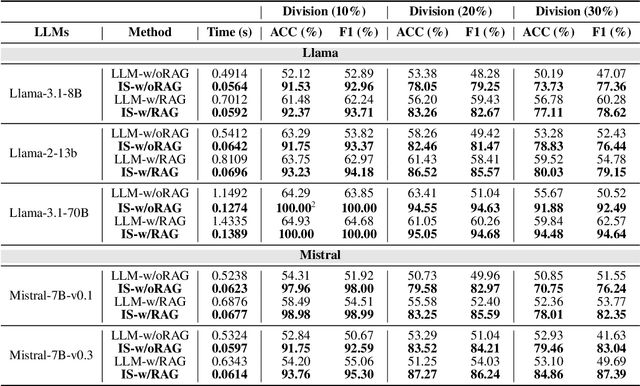
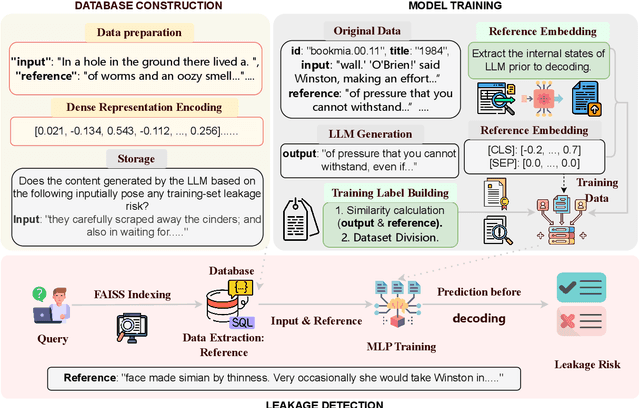
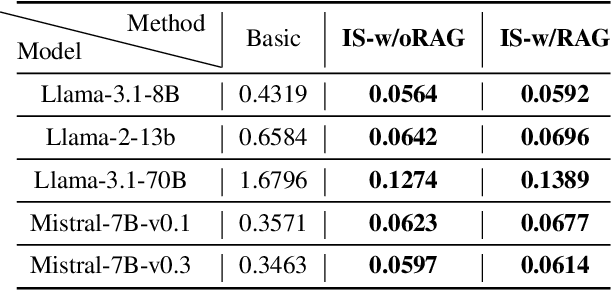
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but pose risks of inadvertently exposing copyrighted or proprietary data, especially when such data is used for training but not intended for distribution. Traditional methods address these leaks only after content is generated, which can lead to the exposure of sensitive information. This study introduces a proactive approach: examining LLMs' internal states before text generation to detect potential leaks. By using a curated dataset of copyrighted materials, we trained a neural network classifier to identify risks, allowing for early intervention by stopping the generation process or altering outputs to prevent disclosure. Integrated with a Retrieval-Augmented Generation (RAG) system, this framework ensures adherence to copyright and licensing requirements while enhancing data privacy and ethical standards. Our results show that analyzing internal states effectively mitigates the risk of copyrighted data leakage, offering a scalable solution that fits smoothly into AI workflows, ensuring compliance with copyright regulations while maintaining high-quality text generation. The implementation is available on GitHub.\footnote{https://github.com/changhu73/Internal_states_leakage}
Beyond Reactive Safety: Risk-Aware LLM Alignment via Long-Horizon Simulation
Jun 26, 2025Given the growing influence of language model-based agents on high-stakes societal decisions, from public policy to healthcare, ensuring their beneficial impact requires understanding the far-reaching implications of their suggestions. We propose a proof-of-concept framework that projects how model-generated advice could propagate through societal systems on a macroscopic scale over time, enabling more robust alignment. To assess the long-term safety awareness of language models, we also introduce a dataset of 100 indirect harm scenarios, testing models' ability to foresee adverse, non-obvious outcomes from seemingly harmless user prompts. Our approach achieves not only over 20% improvement on the new dataset but also an average win rate exceeding 70% against strong baselines on existing safety benchmarks (AdvBench, SafeRLHF, WildGuardMix), suggesting a promising direction for safer agents.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
DEL-ToM: Inference-Time Scaling for Theory-of-Mind Reasoning via Dynamic Epistemic Logic
May 22, 2025Theory-of-Mind (ToM) tasks pose a unique challenge for small language models (SLMs) with limited scale, which often lack the capacity to perform deep social reasoning. In this work, we propose DEL-ToM, a framework that improves ToM reasoning through inference-time scaling rather than architectural changes. Our approach decomposes ToM tasks into a sequence of belief updates grounded in Dynamic Epistemic Logic (DEL), enabling structured and transparent reasoning. We train a verifier, called the Process Belief Model (PBM), to score each belief update step using labels generated automatically via a DEL simulator. During inference, candidate belief traces generated by a language model are evaluated by the PBM, and the highest-scoring trace is selected. This allows SLMs to emulate more deliberate reasoning by allocating additional compute at test time. Experiments across multiple model scales and benchmarks show that DEL-ToM consistently improves performance, demonstrating that verifiable belief supervision can significantly enhance ToM abilities of SLMs without retraining.
RM-R1: Reward Modeling as Reasoning
May 05, 2025Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. In this work, we introduce a new class of generative reward models -- Reasoning Reward Models (ReasRMs) -- which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them. Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1-405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.