 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025
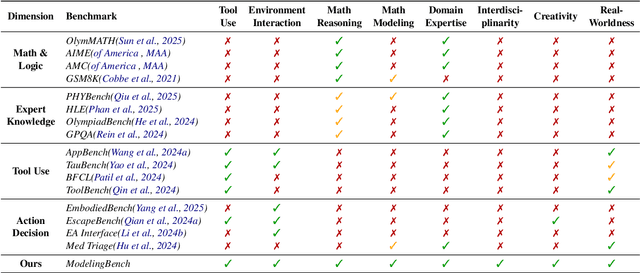
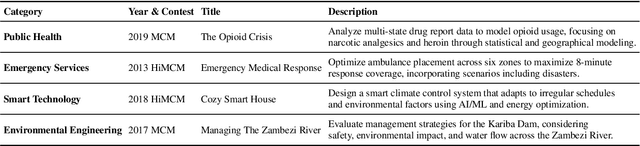
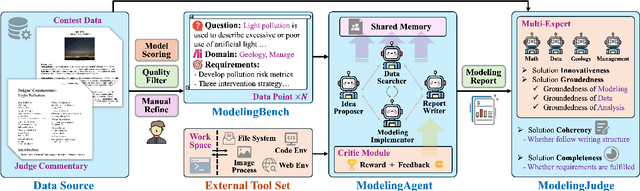
Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Mar 03, 2025Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%. Code and datasets are public available at https://github.com/MultiagentBench/MARBLE.
EscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.