 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
Current Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations
Dec 30, 2025Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Dec 18, 2025Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: \textbf{Is this complexity necessary?} We present \textbf{JustRL}, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9\% and 64.3\% average accuracy across nine mathematical benchmarks) while using 2$\times$ less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding ``standard tricks'' like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025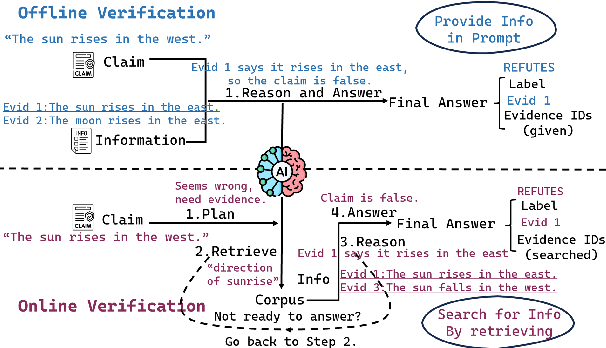
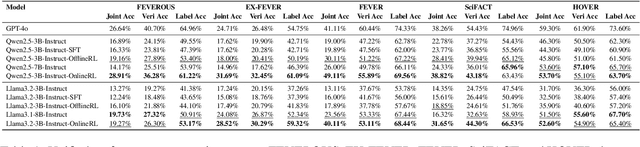
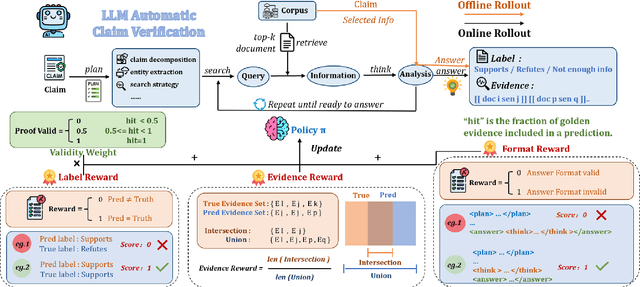

Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
Apr 04, 2025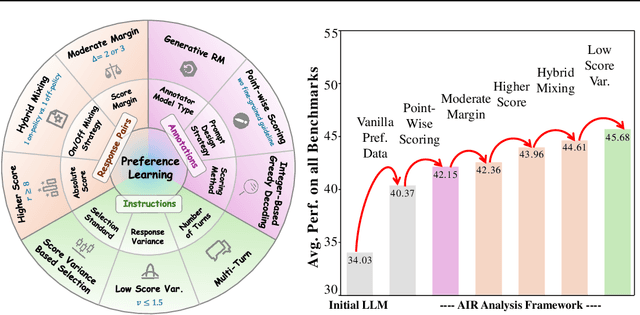
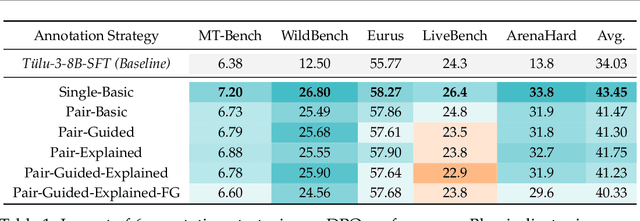
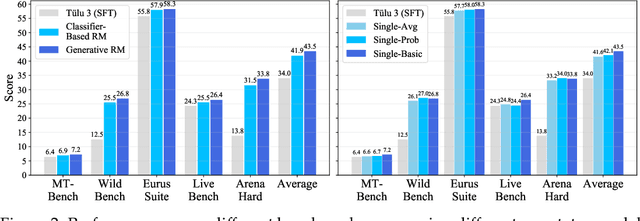

Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.
Process Reinforcement through Implicit Rewards
Feb 03, 2025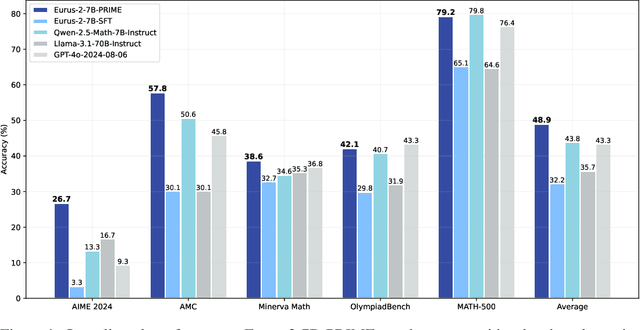

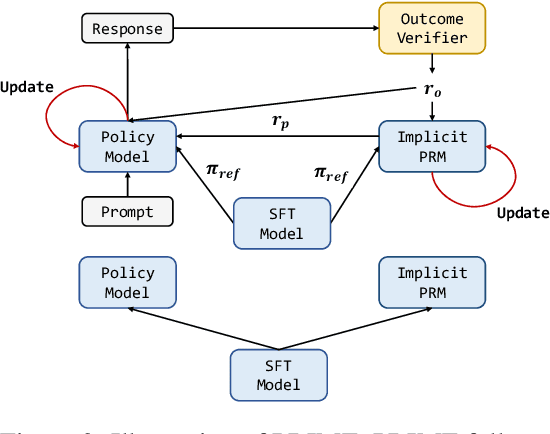
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
EscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.