 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Wrong with End-to-End Learning for Phase Retrieval?
Mar 18, 2024For nonlinear inverse problems that are prevalent in imaging science, symmetries in the forward model are common. When data-driven deep learning approaches are used to solve such problems, these intrinsic symmetries can cause substantial learning difficulties. In this paper, we explain how such difficulties arise and, more importantly, how to overcome them by preprocessing the training set before any learning, i.e., symmetry breaking. We take far-field phase retrieval (FFPR), which is central to many areas of scientific imaging, as an example and show that symmetric breaking can substantially improve data-driven learning. We also formulate the mathematical principle of symmetry breaking.
Tell Me More! Towards Implicit User Intention Understanding of Language Model Driven Agents
Feb 15, 2024Current language model-driven agents often lack mechanisms for effective user participation, which is crucial given the vagueness commonly found in user instructions. Although adept at devising strategies and performing tasks, these agents struggle with seeking clarification and grasping precise user intentions. To bridge this gap, we introduce Intention-in-Interaction (IN3), a novel benchmark designed to inspect users' implicit intentions through explicit queries. Next, we propose the incorporation of model experts as the upstream in agent designs to enhance user-agent interaction. Employing IN3, we empirically train Mistral-Interact, a powerful model that proactively assesses task vagueness, inquires user intentions, and refines them into actionable goals before starting downstream agent task execution. Integrating it into the XAgent framework, we comprehensively evaluate the enhanced agent system regarding user instruction understanding and execution, revealing that our approach notably excels at identifying vague user tasks, recovering and summarizing critical missing information, setting precise and necessary agent execution goals, and minimizing redundant tool usage, thus boosting overall efficiency. All the data and codes are released.
Subgraph Centralization: A Necessary Step for Graph Anomaly Detection
Jan 17, 2023



Graph anomaly detection has attracted a lot of interest recently. Despite their successes, existing detectors have at least two of the three weaknesses: (a) high computational cost which limits them to small-scale networks only; (b) existing treatment of subgraphs produces suboptimal detection accuracy; and (c) unable to provide an explanation as to why a node is anomalous, once it is identified. We identify that the root cause of these weaknesses is a lack of a proper treatment for subgraphs. A treatment called Subgraph Centralization for graph anomaly detection is proposed to address all the above weaknesses. Its importance is shown in two ways. First, we present a simple yet effective new framework called Graph-Centric Anomaly Detection (GCAD). The key advantages of GCAD over existing detectors including deep-learning detectors are: (i) better anomaly detection accuracy; (ii) linear time complexity with respect to the number of nodes; and (iii) it is a generic framework that admits an existing point anomaly detector to be used to detect node anomalies in a network. Second, we show that Subgraph Centralization can be incorporated into two existing detectors to overcome the above-mentioned weaknesses.
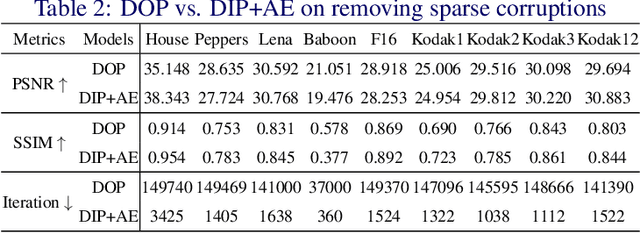
Practical Phase Retrieval Using Double Deep Image Priors
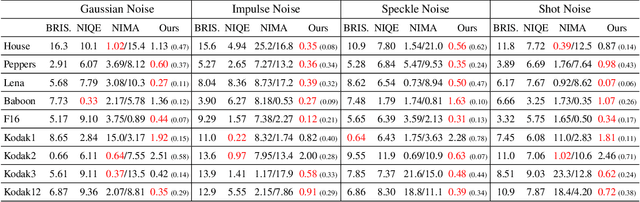
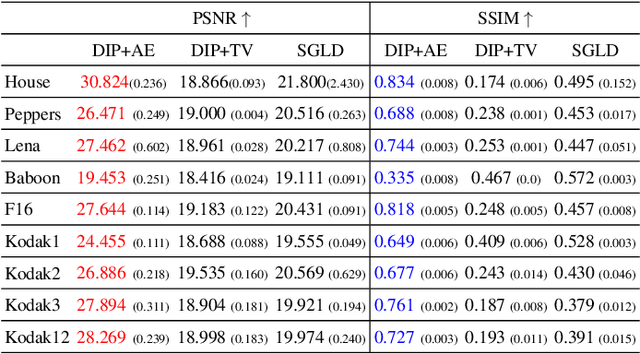
Nov 02, 2022Phase retrieval (PR) concerns the recovery of complex phases from complex magnitudes. We identify the connection between the difficulty level and the number and variety of symmetries in PR problems. We focus on the most difficult far-field PR (FFPR), and propose a novel method using double deep image priors. In realistic evaluation, our method outperforms all competing methods by large margins. As a single-instance method, our method requires no training data and minimal hyperparameter tuning, and hence enjoys good practicality.
Blind Image Deblurring with Unknown Kernel Size and Substantial Noise
Aug 18, 2022

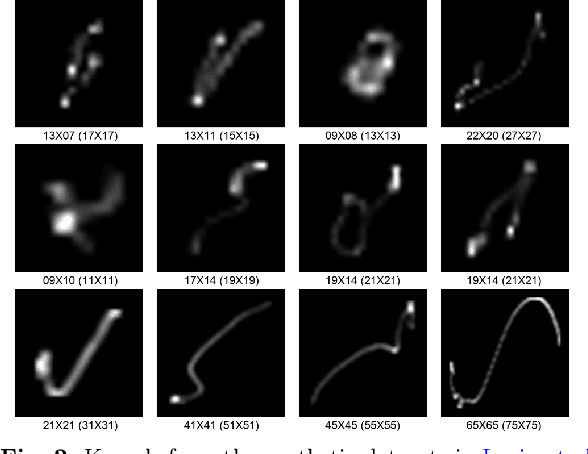

Blind image deblurring (BID) has been extensively studied in computer vision and adjacent fields. Modern methods for BID can be grouped into two categories: single-instance methods that deal with individual instances using statistical inference and numerical optimization, and data-driven methods that train deep-learning models to deblur future instances directly. Data-driven methods can be free from the difficulty in deriving accurate blur models, but are fundamentally limited by the diversity and quality of the training data -- collecting sufficiently expressive and realistic training data is a standing challenge. In this paper, we focus on single-instance methods that remain competitive and indispensable. However, most such methods do not prescribe how to deal with unknown kernel size and substantial noise, precluding practical deployment. Indeed, we show that several state-of-the-art (SOTA) single-instance methods are unstable when the kernel size is overspecified, and/or the noise level is high. On the positive side, we propose a practical BID method that is stable against both, the first of its kind. Our method builds on the recent ideas of solving inverse problems by integrating the physical models and structured deep neural networks, without extra training data. We introduce several crucial modifications to achieve the desired stability. Extensive empirical tests on standard synthetic datasets, as well as real-world NTIRE2020 and RealBlur datasets, show the superior effectiveness and practicality of our BID method compared to SOTA single-instance as well as data-driven methods. The code of our method is available at: \url{https://github.com/sun-umn/Blind-Image-Deblurring}.
Early Stopping for Deep Image Prior
Dec 11, 2021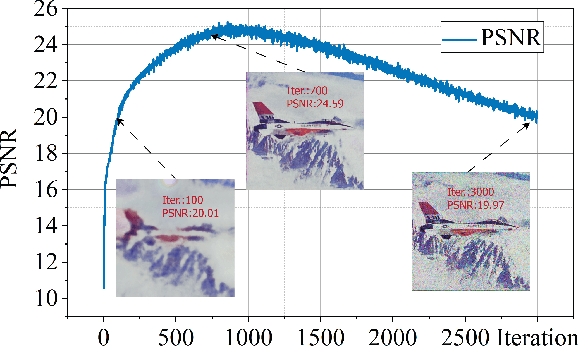
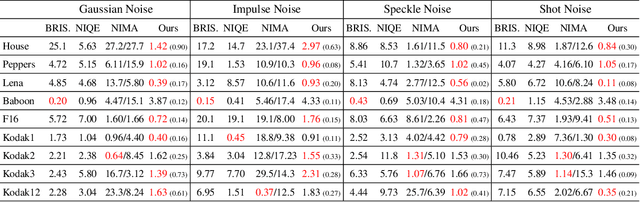
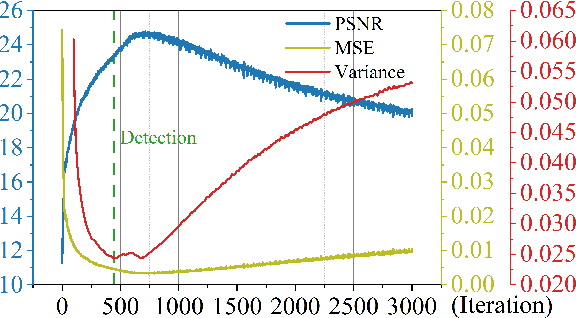
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021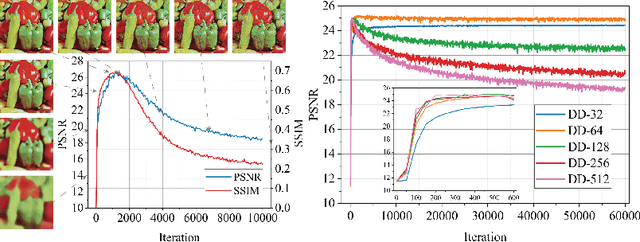
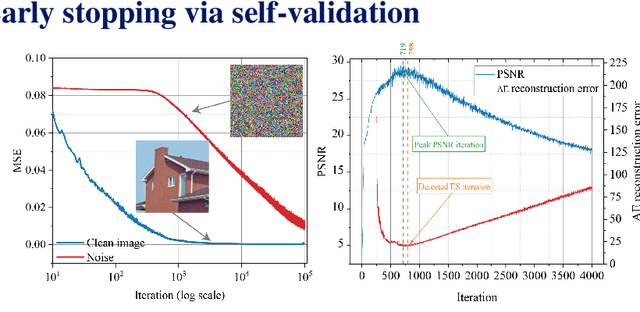
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Phase Retrieval using Single-Instance Deep Generative Prior
Jun 22, 2021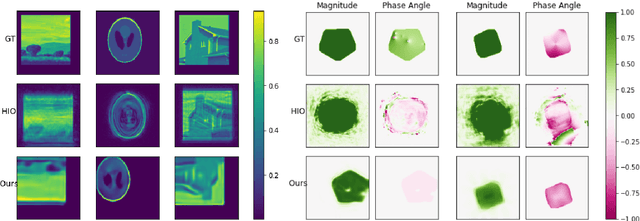
Several deep learning methods for phase retrieval exist, but most of them fail on realistic data without precise support information. We propose a novel method based on single-instance deep generative prior that works well on complex-valued crystal data.