 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
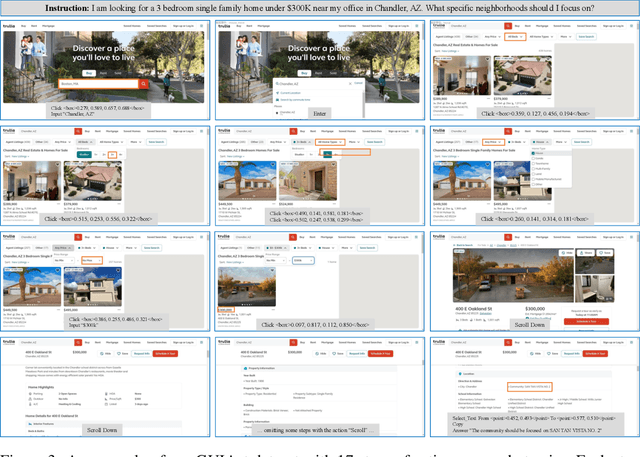
Jun 09, 2026Recent years have witnessed the rapid evolution of AI agents toward handling increasingly complex, real-world tasks. However, existing benchmarks rarely evaluate whether agents can operate graphical user interfaces to complete long-horizon, high-value professional workflows across diverse domains. Current GUI benchmarks still predominantly focus on general-purpose software, relatively simple applications, and short-horizon tasks, leaving it largely unknown whether modern agents can follow user instructions to autonomously operate domain-specific professional software and accomplish economically valuable work in an end-to-end manner. To bridge this gap, we introduce Workflow-GYM, a benchmark for long-horizon GUI tasks centered on professional domains and specialized software environments. Through extensive experiments on state-of-the-art models, we find that even the strongest models achieve only slightly above 30% success rates, highlighting that professional long-horizon GUI workflows remain highly challenging for current GUI agents. Further analysis reveals that current agents struggle to maintain long-horizon workflow consistency, frequently exhibiting workflow stage omission, error propagation, objective drift, and insufficient understanding of professional software environments. Our findings provide important insights into the limitations of current agent systems and suggest key directions for the next generation of GUI-agent research.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Nov 12, 2025
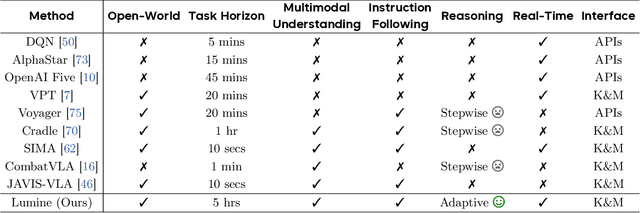


We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-language model. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Apr 15, 2025While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model's tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool's superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI's o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ''aha moment'' in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
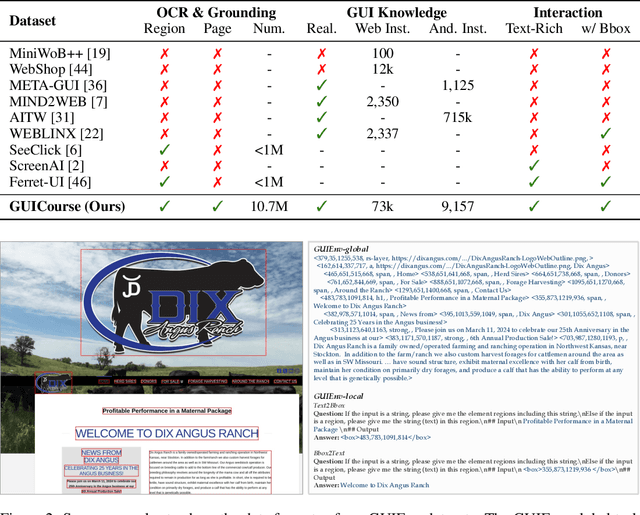
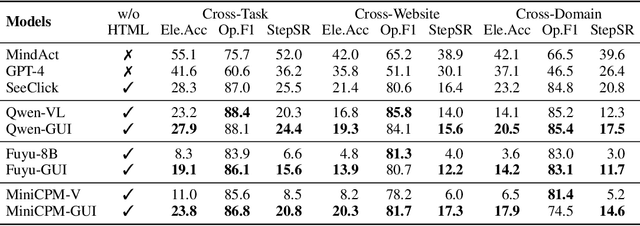
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Mar 13, 2024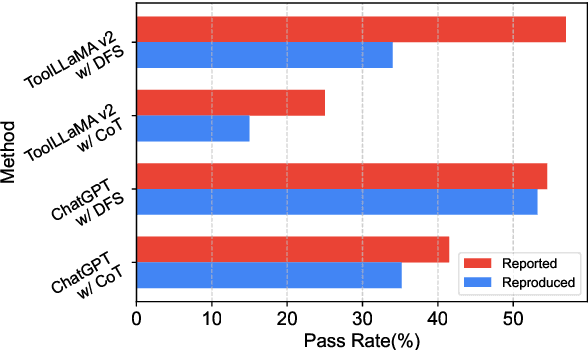
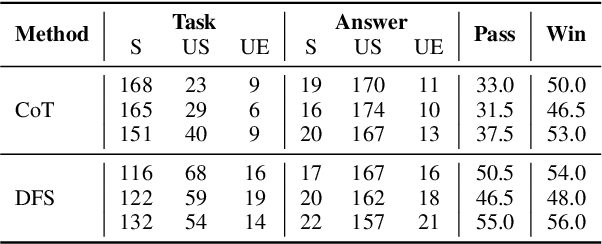
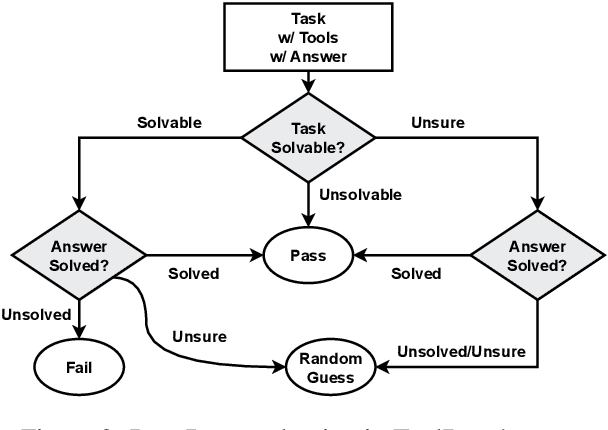
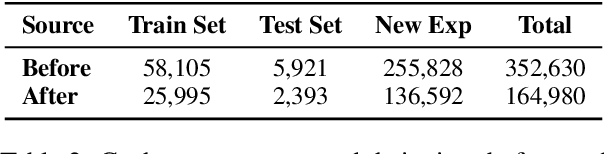
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
Feb 26, 2024
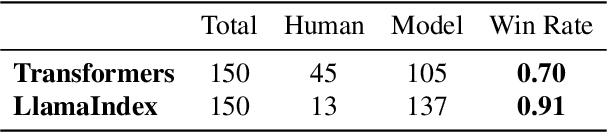
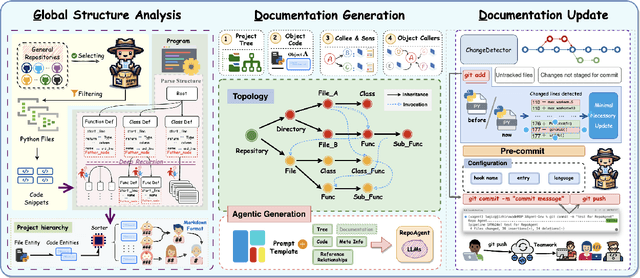
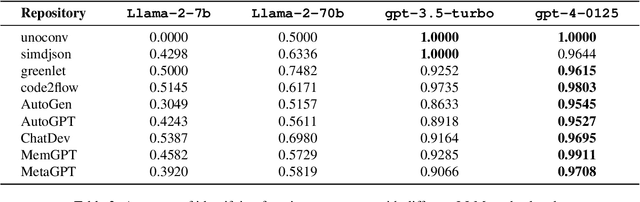
Generative models have demonstrated considerable potential in software engineering, particularly in tasks such as code generation and debugging. However, their utilization in the domain of code documentation generation remains underexplored. To this end, we introduce RepoAgent, a large language model powered open-source framework aimed at proactively generating, maintaining, and updating code documentation. Through both qualitative and quantitative evaluations, we have validated the effectiveness of our approach, showing that RepoAgent excels in generating high-quality repository-level documentation. The code and results are publicly accessible at https://github.com/OpenBMB/RepoAgent.