 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
SwiftSpec: Ultra-Low Latency LLM Decoding by Scaling Asynchronous Speculative Decoding
Jun 12, 2025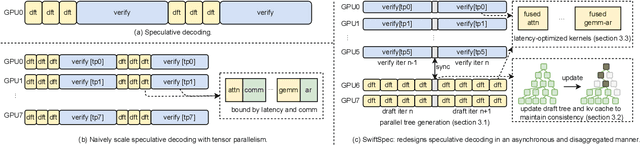


Low-latency decoding for large language models (LLMs) is crucial for applications like chatbots and code assistants, yet generating long outputs remains slow in single-query settings. Prior work on speculative decoding (which combines a small draft model with a larger target model) and tensor parallelism has each accelerated decoding. However, conventional approaches fail to apply both simultaneously due to imbalanced compute requirements (between draft and target models), KV-cache inconsistencies, and communication overheads under small-batch tensor-parallelism. This paper introduces SwiftSpec, a system that targets ultra-low latency for LLM decoding. SwiftSpec redesigns the speculative decoding pipeline in an asynchronous and disaggregated manner, so that each component can be scaled flexibly and remove draft overhead from the critical path. To realize this design, SwiftSpec proposes parallel tree generation, tree-aware KV cache management, and fused, latency-optimized kernels to overcome the challenges listed above. Across 5 model families and 6 datasets, SwiftSpec achieves an average of 1.75x speedup over state-of-the-art speculative decoding systems and, as a highlight, serves Llama3-70B at 348 tokens/s on 8 Nvidia Hopper GPUs, making it the fastest known system for low-latency LLM serving at this scale.
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Apr 15, 2025While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model's tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool's superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI's o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ''aha moment'' in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Feb 27, 2025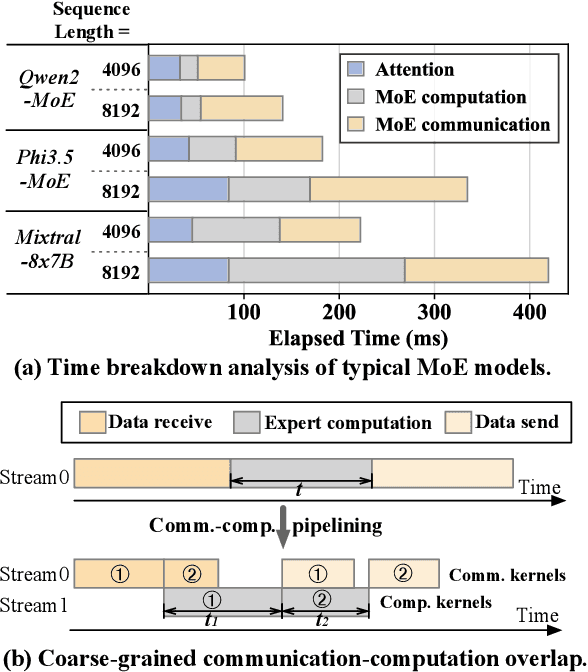



Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal. To this end, we present COMET, an optimized MoE system with fine-grained communication-computation overlapping. Leveraging data dependency analysis and task rescheduling, COMET achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, COMET effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that COMET accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, COMET delivers a $1.71\times$ speedup on average. COMET has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
Jun 12, 2024



Large deep learning models have demonstrated strong ability to solve many tasks across a wide range of applications. Those large models typically require training and inference to be distributed. Tensor parallelism is a common technique partitioning computation of an operation or layer across devices to overcome the memory capacity limitation of a single processor, and/or to accelerate computation to meet a certain latency requirement. However, this kind of parallelism introduces additional communication that might contribute a significant portion of overall runtime. Thus limits scalability of this technique within a group of devices with high speed interconnects, such as GPUs with NVLinks in a node. This paper proposes a novel method, Flux, to significantly hide communication latencies with dependent computations for GPUs. Flux over-decomposes communication and computation operations into much finer-grained operations and further fuses them into a larger kernel to effectively hide communication without compromising kernel efficiency. Flux can potentially overlap up to 96% of communication given a fused kernel. Overall, it can achieve up to 1.24x speedups for training over Megatron-LM on a cluster of 128 GPUs with various GPU generations and interconnects, and up to 1.66x and 1.30x speedups for prefill and decoding inference over vLLM on a cluster with 8 GPUs with various GPU generations and interconnects.
ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs
Oct 06, 2022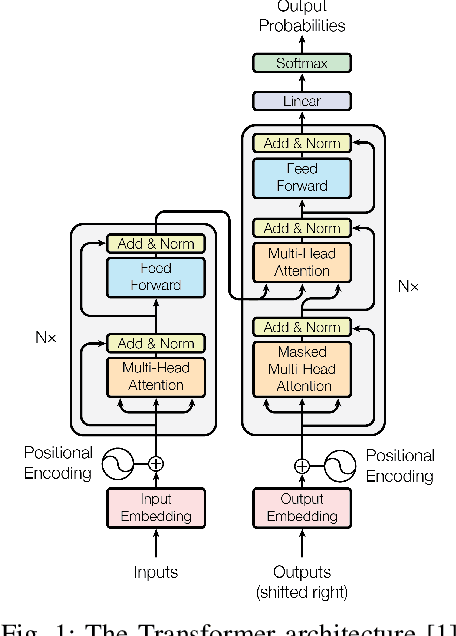
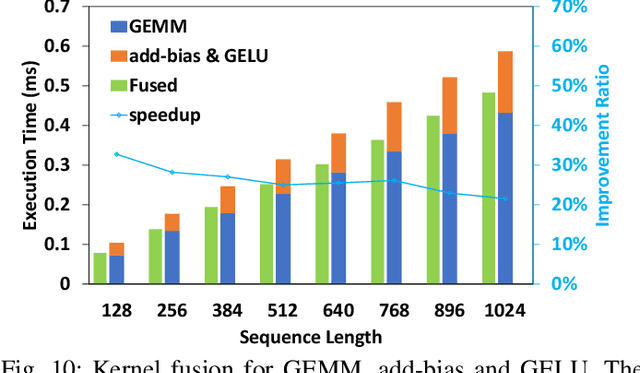
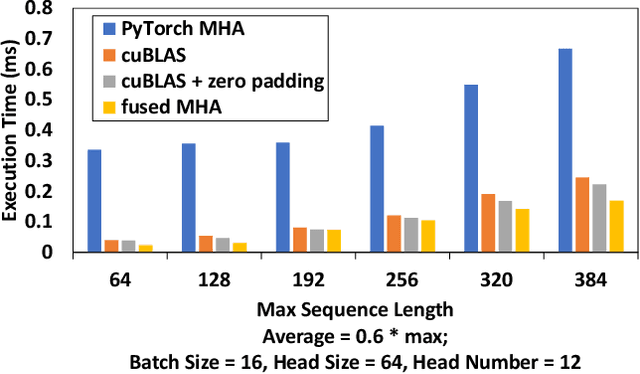
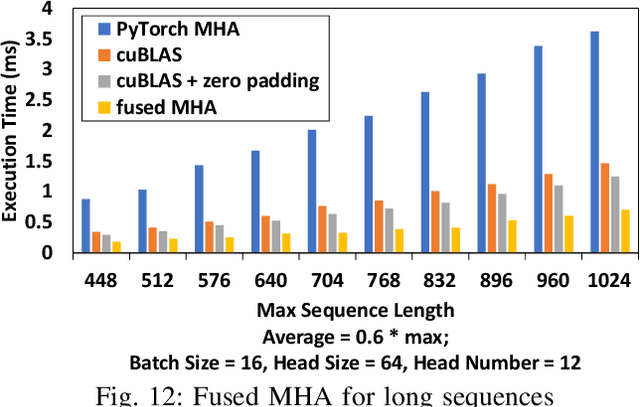
Transformer is the cornerstone model of Natural Language Processing (NLP) over the past decade. Despite its great success in Deep Learning (DL) applications, the increasingly growing parameter space required by transformer models boosts the demand on accelerating the performance of transformer models. In addition, NLP problems can commonly be faced with variable-length sequences since their word numbers can vary among sentences. Existing DL frameworks need to pad variable-length sequences to the maximal length, which, however, leads to significant memory and computational overhead. In this paper, we present ByteTransformer, a high-performance transformer boosted for variable-length inputs. We propose a zero padding algorithm that enables the whole transformer to be free from redundant computations on useless padded tokens. Besides the algorithmic level optimization, we provide architectural-aware optimizations for transformer functioning modules, especially the performance-critical algorithm, multi-head attention (MHA). Experimental results on an NVIDIA A100 GPU with variable-length sequence inputs validate that our fused MHA (FMHA) outperforms the standard PyTorch MHA by 6.13X. The end-to-end performance of ByteTransformer for a standard BERT transformer model surpasses the state-of-the-art Transformer frameworks, such as PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer and NVIDIA FasterTransformer, by 87\%, 131\%, 138\% and 46\%, respectively.