 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Feb 27, 2025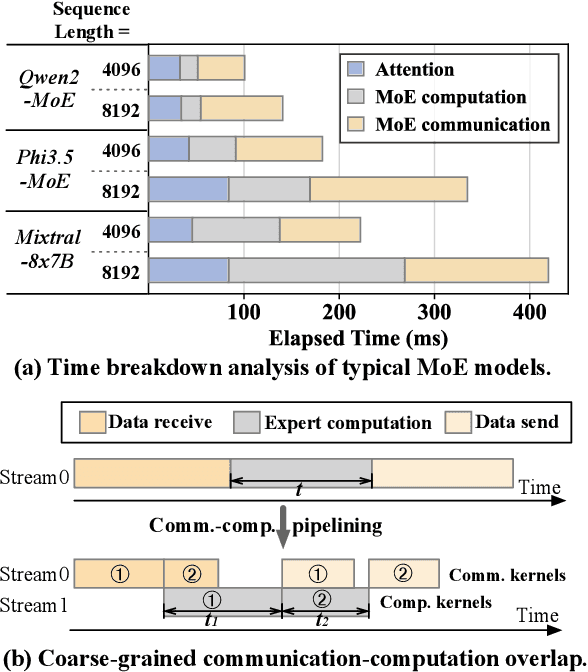



Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal. To this end, we present COMET, an optimized MoE system with fine-grained communication-computation overlapping. Leveraging data dependency analysis and task rescheduling, COMET achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, COMET effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that COMET accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, COMET delivers a $1.71\times$ speedup on average. COMET has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
Jun 12, 2024



Large deep learning models have demonstrated strong ability to solve many tasks across a wide range of applications. Those large models typically require training and inference to be distributed. Tensor parallelism is a common technique partitioning computation of an operation or layer across devices to overcome the memory capacity limitation of a single processor, and/or to accelerate computation to meet a certain latency requirement. However, this kind of parallelism introduces additional communication that might contribute a significant portion of overall runtime. Thus limits scalability of this technique within a group of devices with high speed interconnects, such as GPUs with NVLinks in a node. This paper proposes a novel method, Flux, to significantly hide communication latencies with dependent computations for GPUs. Flux over-decomposes communication and computation operations into much finer-grained operations and further fuses them into a larger kernel to effectively hide communication without compromising kernel efficiency. Flux can potentially overlap up to 96% of communication given a fused kernel. Overall, it can achieve up to 1.24x speedups for training over Megatron-LM on a cluster of 128 GPUs with various GPU generations and interconnects, and up to 1.66x and 1.30x speedups for prefill and decoding inference over vLLM on a cluster with 8 GPUs with various GPU generations and interconnects.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024



We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
The Automatic Identification of Butterfly Species
Mar 18, 2018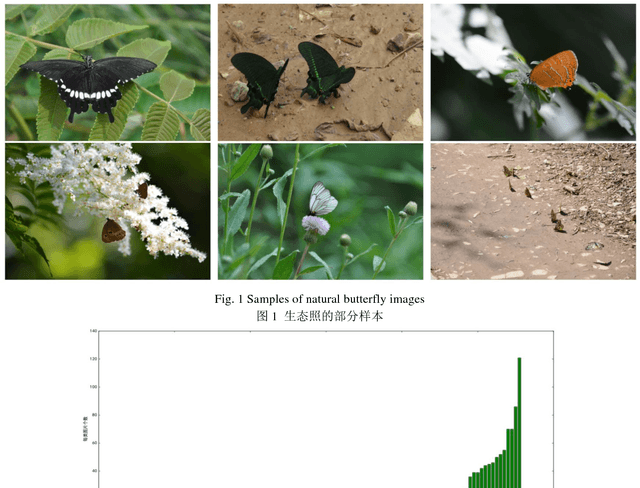

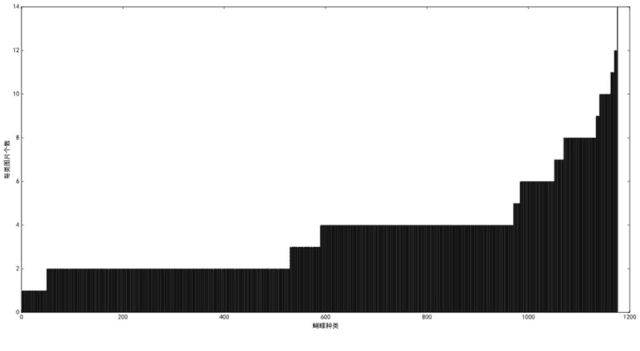
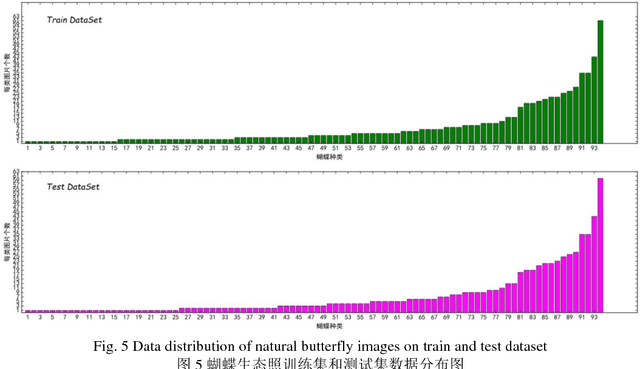
The available butterfly data sets comprise a few limited species, and the images in the data sets are always standard patterns without the images of butterflies in their living environment. To overcome the aforementioned limitations in the butterfly data sets, we build a butterfly data set composed of all species of butterflies in China with 4270 standard pattern images of 1176 butterfly species, and 1425 images from living environment of 111 species. We propose to use the deep learning technique Faster-Rcnn to train an automatic butterfly identification system including butterfly position detection and species recognition. We delete those species with only one living environment image from data set, then partition the rest images from living environment into two subsets, one used as test subset, the other as training subset respectively combined with all standard pattern butterfly images or the standard pattern butterfly images with the same species of the images from living environment. In order to construct the training subset for FasterRcnn, nine methods were adopted to amplifying the images in the training subset including the turning of up and down, and left and right, rotation with different angles, adding noises, blurring, and contrast ratio adjusting etc. Three prediction models were trained. The mAP (Mean Average prediction) criterion was used to evaluate the performance of the prediction model. The experimental results demonstrate that our Faster-Rcnn based butterfly automatic identification system performed well, and its worst mAP is up to 60%, and can simultaneously detect the positions of more than one butterflies in one images from living environment and recognize the species of those butterflies as well.