 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
SketchAssist: A Practical Assistant for Semantic Edits and Precise Local Redrawing
Dec 16, 2025
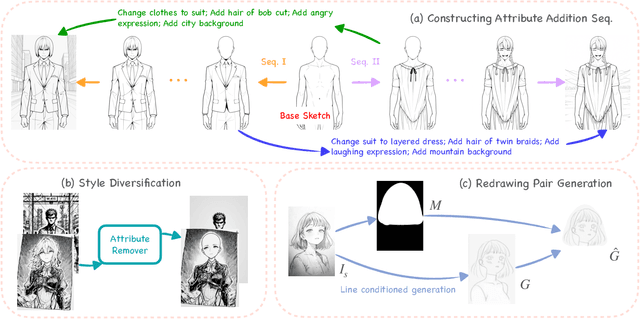
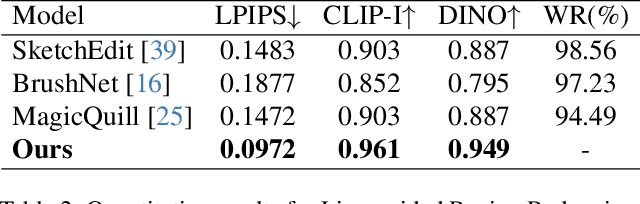
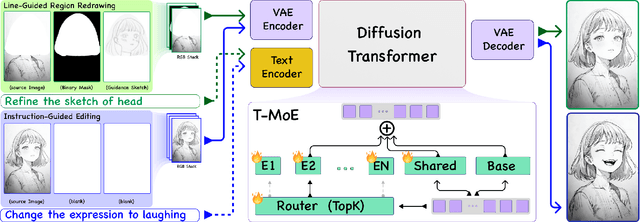
Sketch editing is central to digital illustration, yet existing image editing systems struggle to preserve the sparse, style-sensitive structure of line art while supporting both high-level semantic changes and precise local redrawing. We present SketchAssist, an interactive sketch drawing assistant that accelerates creation by unifying instruction-guided global edits with line-guided region redrawing, while keeping unrelated regions and overall composition intact. To enable this assistant at scale, we introduce a controllable data generation pipeline that (i) constructs attribute-addition sequences from attribute-free base sketches, (ii) forms multi-step edit chains via cross-sequence sampling, and (iii) expands stylistic coverage with a style-preserving attribute-removal model applied to diverse sketches. Building on this data, SketchAssist employs a unified sketch editing framework with minimal changes to DiT-based editors. We repurpose the RGB channels to encode the inputs, enabling seamless switching between instruction-guided edits and line-guided redrawing within a single input interface. To further specialize behavior across modes, we integrate a task-guided mixture-of-experts into LoRA layers, routing by text and visual cues to improve semantic controllability, structural fidelity, and style preservation. Extensive experiments show state-of-the-art results on both tasks, with superior instruction adherence and style/structure preservation compared to recent baselines. Together, our dataset and SketchAssist provide a practical, controllable assistant for sketch creation and revision.
Geometry-Aware Scene-Consistent Image Generation
Dec 14, 2025We study geometry-aware scene-consistent image generation: given a reference scene image and a text condition specifying an entity to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same physical environment as the reference scene while correctly generating the entity according to the spatial relation described in the text. Existing methods struggle to balance scene preservation with prompt adherence: they either replicate the scene with high fidelity but poor responsiveness to the prompt, or prioritize prompt compliance at the expense of scene consistency. To resolve this trade-off, we introduce two key contributions: (i) a scene-consistent data construction pipeline that generates diverse, geometrically-grounded training pairs, and (ii) a novel geometry-guided attention loss that leverages cross-view cues to regularize the model's spatial reasoning. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image consistency than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method produces geometrically coherent images with diverse compositions that remain faithful to the textual instructions and the underlying scene structure.
Reframing Music-Driven 2D Dance Pose Generation as Multi-Channel Image Generation
Dec 12, 2025Recent pose-to-video models can translate 2D pose sequences into photorealistic, identity-preserving dance videos, so the key challenge is to generate temporally coherent, rhythm-aligned 2D poses from music, especially under complex, high-variance in-the-wild distributions. We address this by reframing music-to-dance generation as a music-token-conditioned multi-channel image synthesis problem: 2D pose sequences are encoded as one-hot images, compressed by a pretrained image VAE, and modeled with a DiT-style backbone, allowing us to inherit architectural and training advances from modern text-to-image models and better capture high-variance 2D pose distributions. On top of this formulation, we introduce (i) a time-shared temporal indexing scheme that explicitly synchronizes music tokens and pose latents over time and (ii) a reference-pose conditioning strategy that preserves subject-specific body proportions and on-screen scale while enabling long-horizon segment-and-stitch generation. Experiments on a large in-the-wild 2D dance corpus and the calibrated AIST++2D benchmark show consistent improvements over representative music-to-dance methods in pose- and video-space metrics and human preference, and ablations validate the contributions of the representation, temporal indexing, and reference conditioning. See supplementary videos at https://hot-dance.github.io
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
SerialGen: Personalized Image Generation by First Standardization Then Personalization
Dec 02, 2024

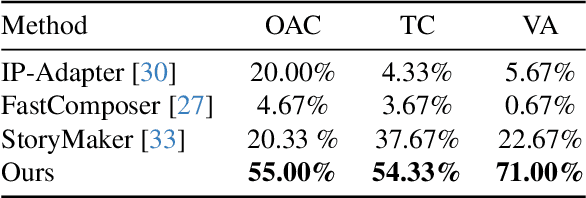

In this work, we are interested in achieving both high text controllability and overall appearance consistency in the generation of personalized human characters. We propose a novel framework, named SerialGen, which is a serial generation method consisting of two stages: first, a standardization stage that standardizes reference images, and then a personalized generation stage based on the standardized reference. Furthermore, we introduce two modules aimed at enhancing the standardization process. Our experimental results validate the proposed framework's ability to produce personalized images that faithfully recover the reference image's overall appearance while accurately responding to a wide range of text prompts. Through thorough analysis, we highlight the critical contribution of the proposed serial generation method and standardization model, evidencing enhancements in appearance consistency between reference and output images and across serial outputs generated from diverse text prompts. The term "Serial" in this work carries a double meaning: it refers to the two-stage method and also underlines our ability to generate serial images with consistent appearance throughout.
Distributed Sign Momentum with Local Steps for Training Transformers
Nov 26, 2024Pre-training Transformer models is resource-intensive, and recent studies have shown that sign momentum is an efficient technique for training large-scale deep learning models, particularly Transformers. However, its application in distributed training or federated learning remains underexplored. This paper investigates a novel communication-efficient distributed sign momentum method with local updates. Our proposed method allows for a broad class of base optimizers for local updates, and uses sign momentum in global updates, where momentum is generated from differences accumulated during local steps. We evaluate our method on the pre-training of various GPT-2 models, and the empirical results show significant improvement compared to other distributed methods with local updates. Furthermore, by approximating the sign operator with a randomized version that acts as a continuous analog in expectation, we present an $O(1/\sqrt{T})$ convergence for one instance of the proposed method for nonconvex smooth functions.
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
Oct 20, 2024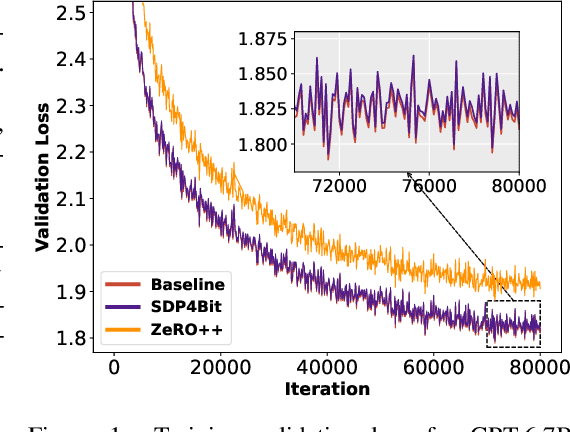
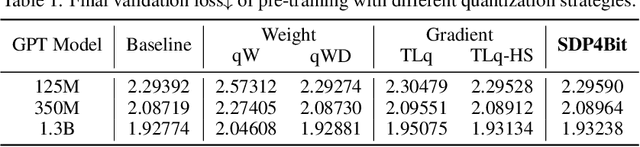
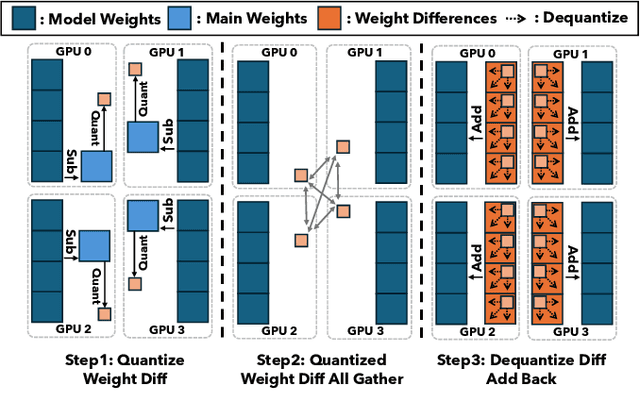
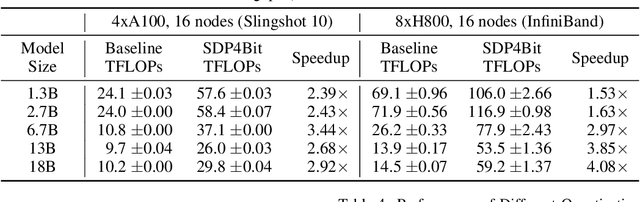
Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. In addition to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08$\times$ speedup in end-to-end throughput on a scale of 128 GPUs.