 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
HoVer: A Dataset for Many-Hop Fact Extraction And Claim Verification
Nov 16, 2020

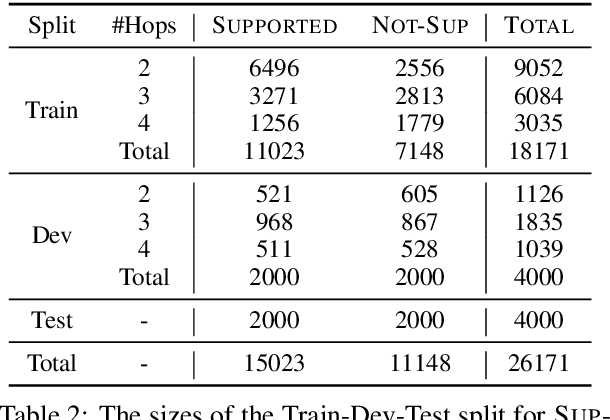
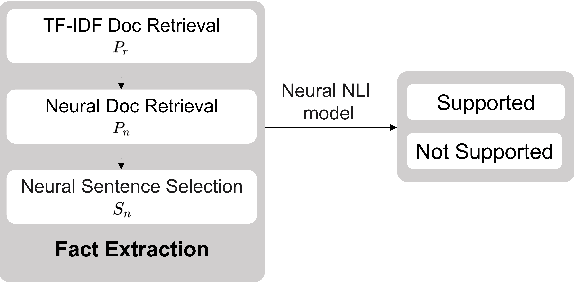
We introduce HoVer (HOppy VERification), a dataset for many-hop evidence extraction and fact verification. It challenges models to extract facts from several Wikipedia articles that are relevant to a claim and classify whether the claim is Supported or Not-Supported by the facts. In HoVer, the claims require evidence to be extracted from as many as four English Wikipedia articles and embody reasoning graphs of diverse shapes. Moreover, most of the 3/4-hop claims are written in multiple sentences, which adds to the complexity of understanding long-range dependency relations such as coreference. We show that the performance of an existing state-of-the-art semantic-matching model degrades significantly on our dataset as the number of reasoning hops increases, hence demonstrating the necessity of many-hop reasoning to achieve strong results. We hope that the introduction of this challenging dataset and the accompanying evaluation task will encourage research in many-hop fact retrieval and information verification. We make the HoVer dataset publicly available at https://hover-nlp.github.io
Adversarial Attack on Deep Learning-Based Splice Localization
Apr 17, 2020

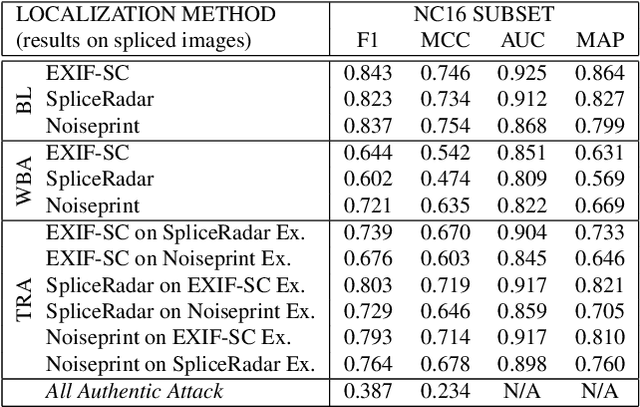
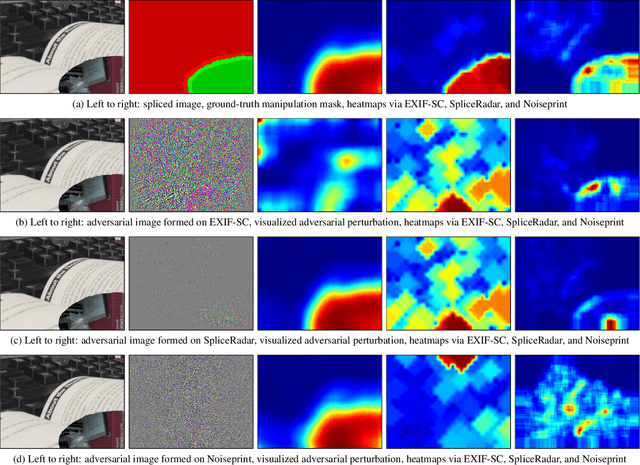
Regarding image forensics, researchers have proposed various approaches to detect and/or localize manipulations, such as splices. Recent best performing image-forensics algorithms greatly benefit from the application of deep learning, but such tools can be vulnerable to adversarial attacks. Due to the fact that most of the proposed adversarial example generation techniques can be used only on end-to-end classifiers, the adversarial robustness of image-forensics methods that utilize deep learning only for feature extraction has not been studied yet. Using a novel algorithm capable of directly adjusting the underlying representations of patches we demonstrate on three non end-to-end deep learning-based splice localization tools that hiding manipulations of images is feasible via adversarial attacks. While the tested image-forensics methods, EXIF-SC, SpliceRadar, and Noiseprint, rely on feature extractors that were trained on different surrogate tasks, we find that the formed adversarial perturbations can be transferable among them regarding the deterioration of their localization performance.
Severity Assessment of Coronavirus Disease 2019 (COVID-19) Using Quantitative Features from Chest CT Images
Mar 26, 2020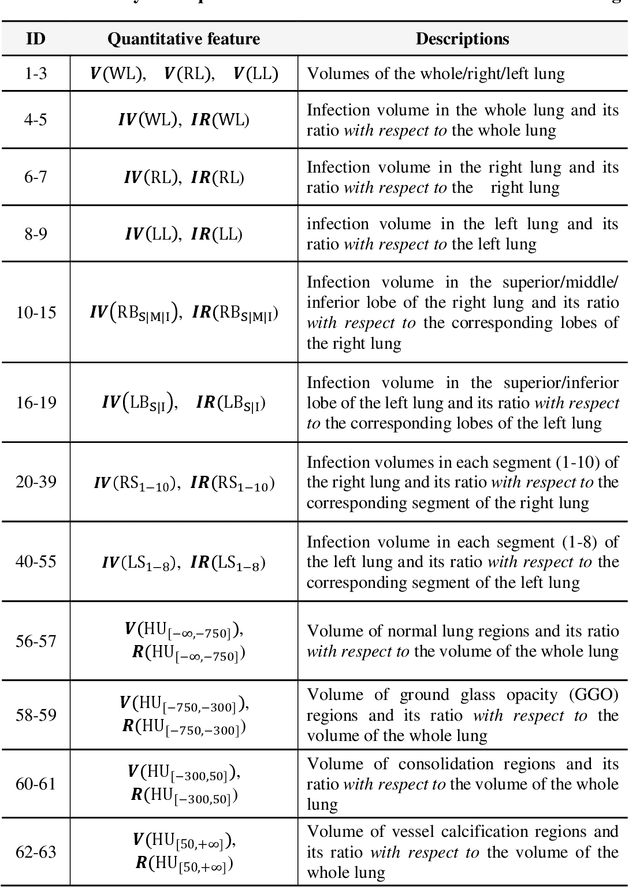
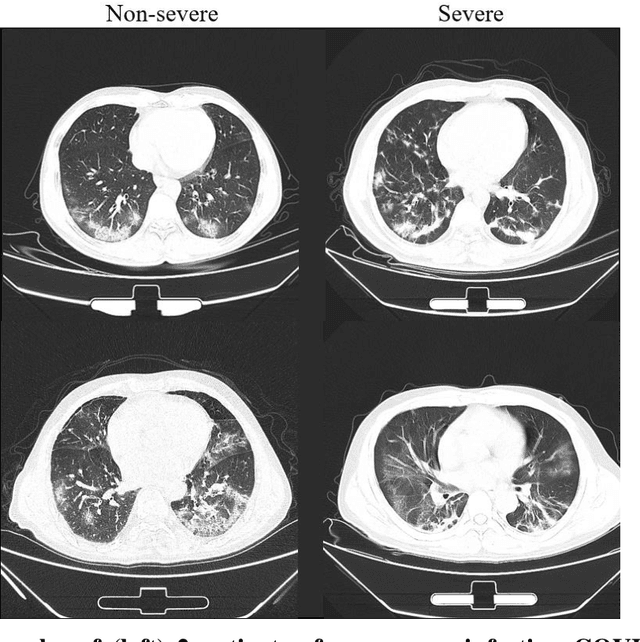
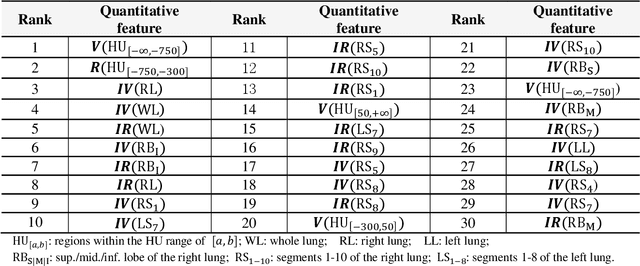
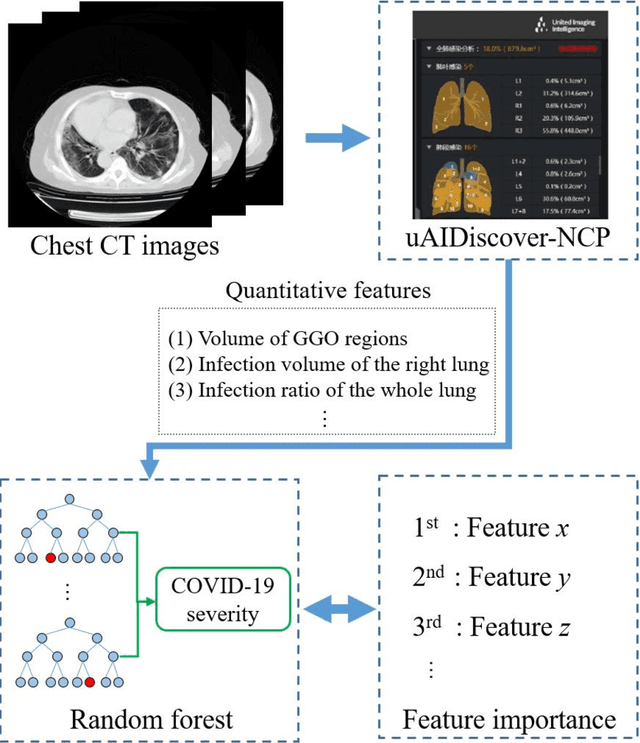
Background: Chest computed tomography (CT) is recognized as an important tool for COVID-19 severity assessment. As the number of affected patients increase rapidly, manual severity assessment becomes a labor-intensive task, and may lead to delayed treatment. Purpose: Using machine learning method to realize automatic severity assessment (non-severe or severe) of COVID-19 based on chest CT images, and to explore the severity-related features from the resulting assessment model. Materials and Method: Chest CT images of 176 patients (age 45.3$\pm$16.5 years, 96 male and 80 female) with confirmed COVID-19 are used, from which 63 quantitative features, e.g., the infection volume/ratio of the whole lung and the volume of ground-glass opacity (GGO) regions, are calculated. A random forest (RF) model is trained to assess the severity (non-severe or severe) based on quantitative features. Importance of each quantitative feature, which reflects the correlation to the severity of COVID-19, is calculated from the RF model. Results: Using three-fold cross validation, the RF model shows promising results, i.e., 0.933 of true positive rate, 0.745 of true negative rate, 0.875 of accuracy, and 0.91 of area under receiver operating characteristic curve (AUC). The resulting importance of quantitative features shows that the volume and its ratio (with respect to the whole lung volume) of ground glass opacity (GGO) regions are highly related to the severity of COVID-19, and the quantitative features calculated from the right lung are more related to the severity assessment than those of the left lung. Conclusion: The RF based model can achieve automatic severity assessment (non-severe or severe) of COVID-19 infection, and the performance is promising. Several quantitative features, which have the potential to reflect the severity of COVID-19, were revealed.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
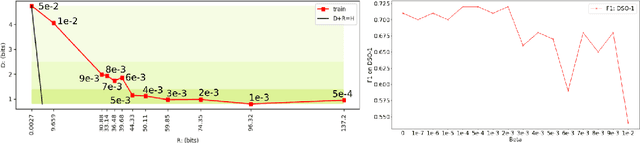

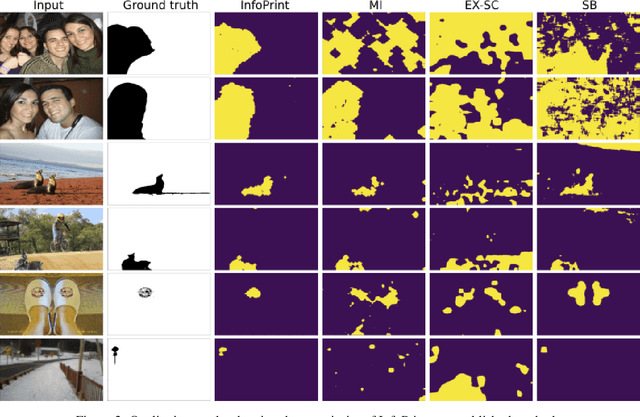
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
SpliceRadar: A Learned Method For Blind Image Forensics
Jun 27, 2019

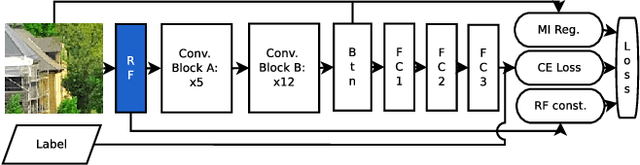
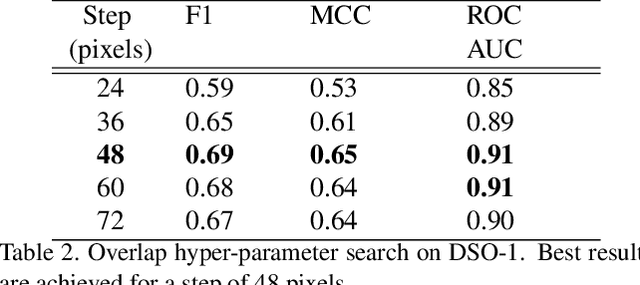
Detection and localization of image manipulations like splices are gaining in importance with the easy accessibility of image editing softwares. While detection generates a verdict for an image it provides no insight into the manipulation. Localization helps explain a positive detection by identifying the pixels of the image which have been tampered. We propose a deep learning based method for splice localization without prior knowledge of a test image's camera-model. It comprises a novel approach for learning rich filters and for suppressing image-edges. Additionally, we train our model on a surrogate task of camera model identification, which allows us to leverage large and widely available, unmanipulated, camera-tagged image databases. During inference, we assume that the spliced and host regions come from different camera-models and we segment these regions using a Gaussian-mixture model. Experiments on three test databases demonstrate results on par with and above the state-of-the-art and a good generalization ability to unknown datasets.