 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack on Deep Learning-Based Splice Localization
Paper and Code
Apr 17, 2020

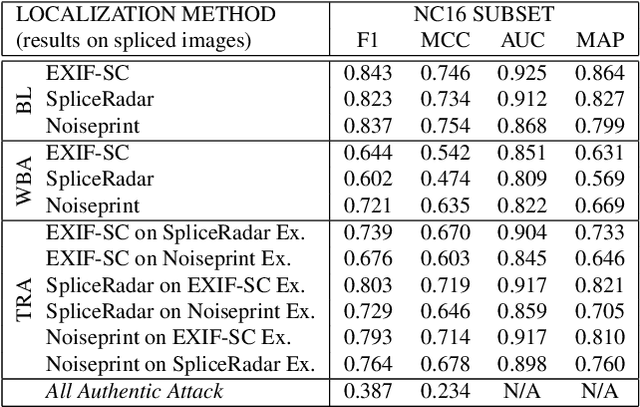
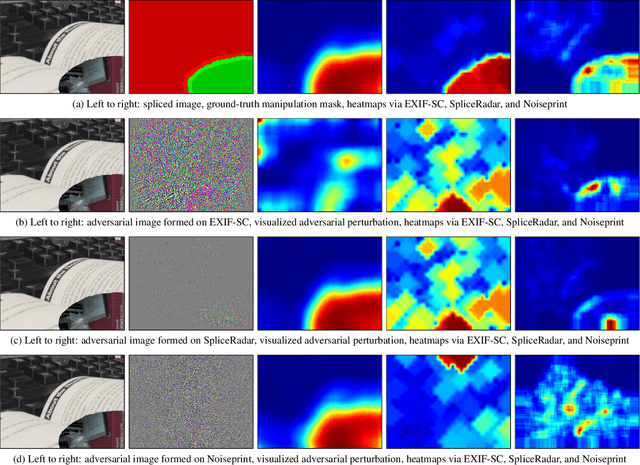
Regarding image forensics, researchers have proposed various approaches to detect and/or localize manipulations, such as splices. Recent best performing image-forensics algorithms greatly benefit from the application of deep learning, but such tools can be vulnerable to adversarial attacks. Due to the fact that most of the proposed adversarial example generation techniques can be used only on end-to-end classifiers, the adversarial robustness of image-forensics methods that utilize deep learning only for feature extraction has not been studied yet. Using a novel algorithm capable of directly adjusting the underlying representations of patches we demonstrate on three non end-to-end deep learning-based splice localization tools that hiding manipulations of images is feasible via adversarial attacks. While the tested image-forensics methods, EXIF-SC, SpliceRadar, and Noiseprint, rely on feature extractors that were trained on different surrogate tasks, we find that the formed adversarial perturbations can be transferable among them regarding the deterioration of their localization performance.