 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Feature Attenuation to NLP
Jan 02, 2026Transformer classifiers such as BERT deliver impressive closed-set accuracy, yet they remain brittle when confronted with inputs from unseen categories--a common scenario for deployed NLP systems. We investigate Open-Set Recognition (OSR) for text by porting the feature attenuation hypothesis from computer vision to transformers and by benchmarking it against state-of-the-art baselines. Concretely, we adapt the COSTARR framework--originally designed for classification in computer vision--to two modest language models (BERT (base) and GPT-2) trained to label 176 arXiv subject areas. Alongside COSTARR, we evaluate Maximum Softmax Probability (MSP), MaxLogit, and the temperature-scaled free-energy score under the OOSA and AUOSCR metrics. Our results show (i) COSTARR extends to NLP without retraining but yields no statistically significant gain over MaxLogit or MSP, and (ii) free-energy lags behind all other scores in this high-class-count setting. The study highlights both the promise and the current limitations of transplanting vision-centric OSR ideas to language models, and points toward the need for larger backbones and task-tailored attenuation strategies.
GHOST: Gaussian Hypothesis Open-Set Technique
Feb 05, 2025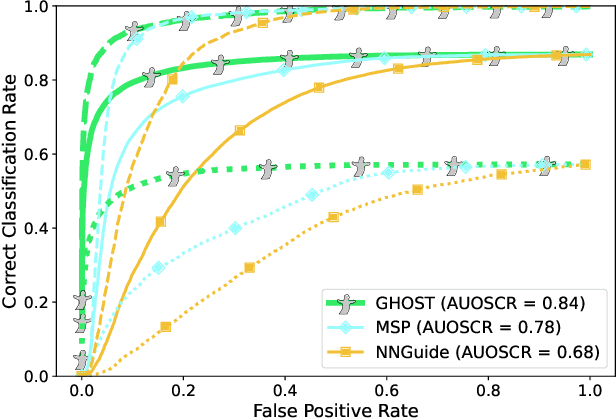

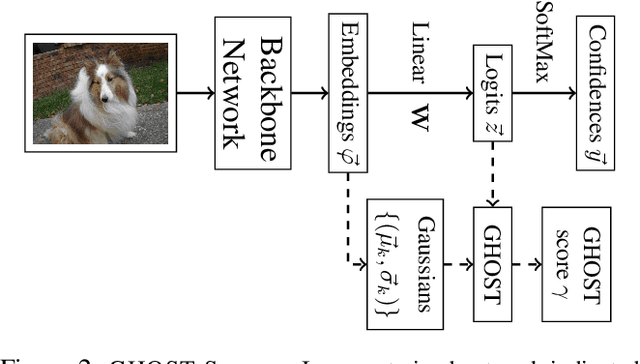
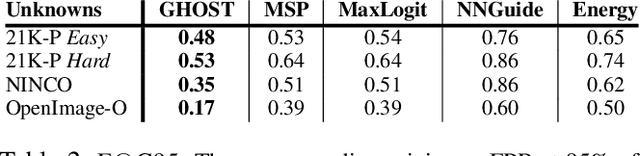
Evaluations of large-scale recognition methods typically focus on overall performance. While this approach is common, it often fails to provide insights into performance across individual classes, which can lead to fairness issues and misrepresentation. Addressing these gaps is crucial for accurately assessing how well methods handle novel or unseen classes and ensuring a fair evaluation. To address fairness in Open-Set Recognition (OSR), we demonstrate that per-class performance can vary dramatically. We introduce Gaussian Hypothesis Open Set Technique (GHOST), a novel hyperparameter-free algorithm that models deep features using class-wise multivariate Gaussian distributions with diagonal covariance matrices. We apply Z-score normalization to logits to mitigate the impact of feature magnitudes that deviate from the model's expectations, thereby reducing the likelihood of the network assigning a high score to an unknown sample. We evaluate GHOST across multiple ImageNet-1K pre-trained deep networks and test it with four different unknown datasets. Using standard metrics such as AUOSCR, AUROC and FPR95, we achieve statistically significant improvements, advancing the state-of-the-art in large-scale OSR. Source code is provided online.
Watchlist Challenge: 3rd Open-set Face Detection and Identification
Sep 11, 2024In the current landscape of biometrics and surveillance, the ability to accurately recognize faces in uncontrolled settings is paramount. The Watchlist Challenge addresses this critical need by focusing on face detection and open-set identification in real-world surveillance scenarios. This paper presents a comprehensive evaluation of participating algorithms, using the enhanced UnConstrained College Students (UCCS) dataset with new evaluation protocols. In total, four participants submitted four face detection and nine open-set face recognition systems. The evaluation demonstrates that while detection capabilities are generally robust, closed-set identification performance varies significantly, with models pre-trained on large-scale datasets showing superior performance. However, open-set scenarios require further improvement, especially at higher true positive identification rates, i.e., lower thresholds.
Open-Set Face Recognition with Maximal Entropy and Objectosphere Loss
Nov 01, 2023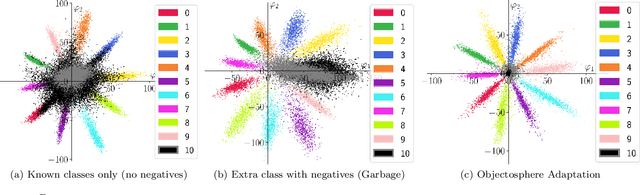
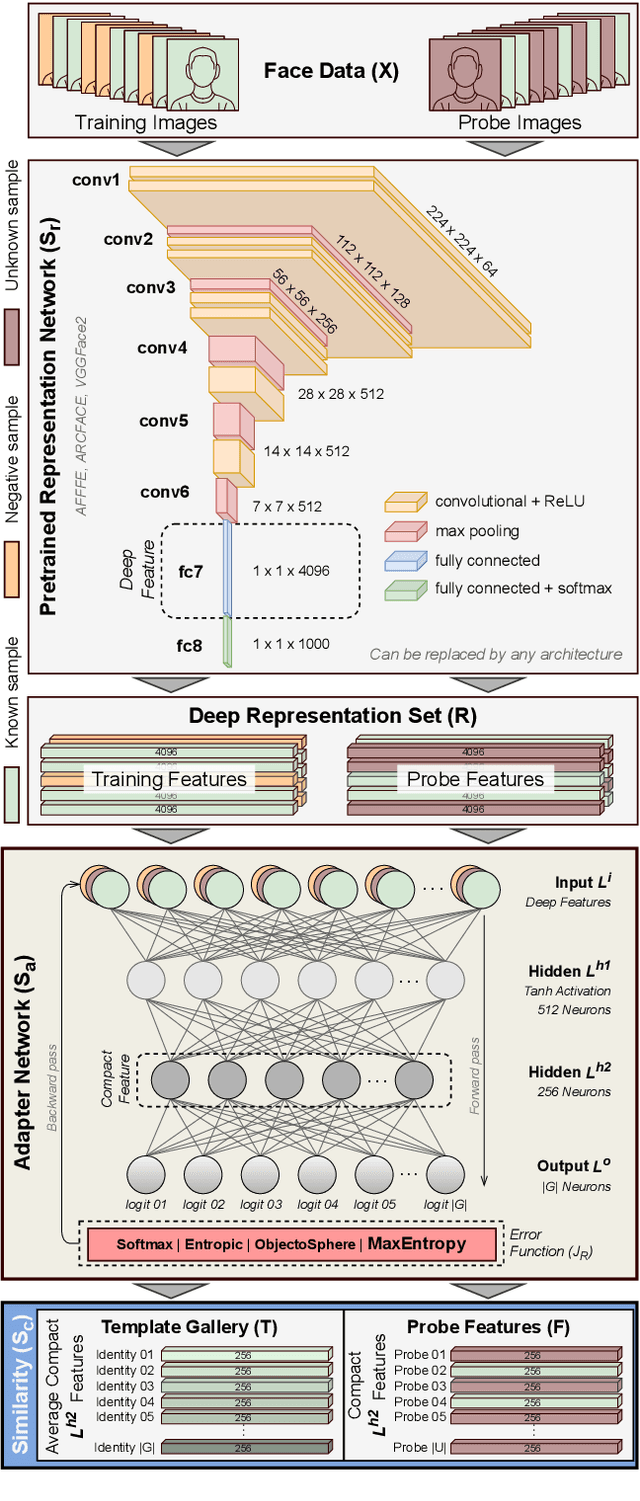
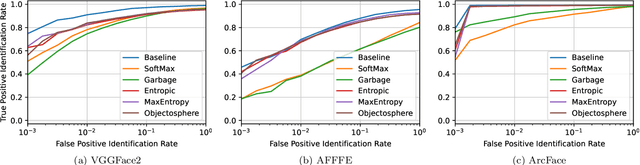
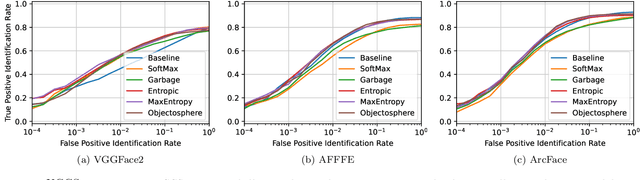
Open-set face recognition characterizes a scenario where unknown individuals, unseen during the training and enrollment stages, appear on operation time. This work concentrates on watchlists, an open-set task that is expected to operate at a low False Positive Identification Rate and generally includes only a few enrollment samples per identity. We introduce a compact adapter network that benefits from additional negative face images when combined with distinct cost functions, such as Objectosphere Loss (OS) and the proposed Maximal Entropy Loss (MEL). MEL modifies the traditional Cross-Entropy loss in favor of increasing the entropy for negative samples and attaches a penalty to known target classes in pursuance of gallery specialization. The proposed approach adopts pre-trained deep neural networks (DNNs) for face recognition as feature extractors. Then, the adapter network takes deep feature representations and acts as a substitute for the output layer of the pre-trained DNN in exchange for an agile domain adaptation. Promising results have been achieved following open-set protocols for three different datasets: LFW, IJB-C, and UCCS as well as state-of-the-art performance when supplementary negative data is properly selected to fine-tune the adapter network.
Large-scale Fully-Unsupervised Re-Identification
Jul 26, 2023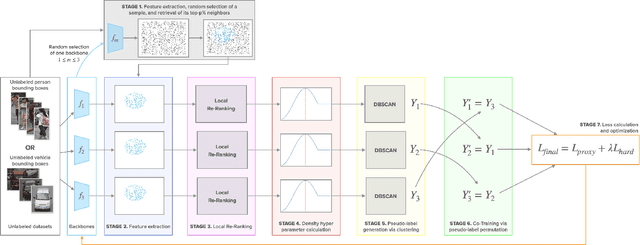
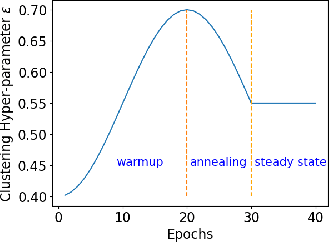


Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
DaliID: Distortion-Adaptive Learned Invariance for Identification Models
Feb 11, 2023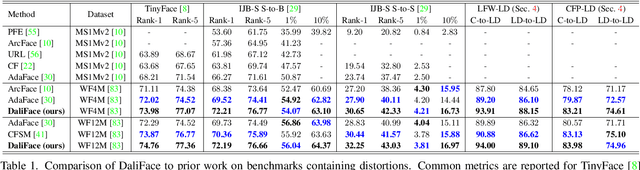


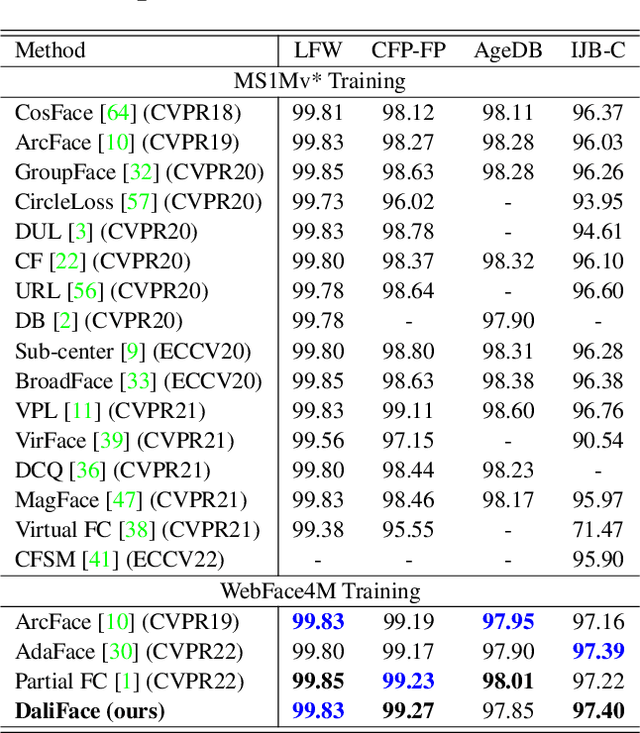
In unconstrained scenarios, face recognition and person re-identification are subject to distortions such as motion blur, atmospheric turbulence, or upsampling artifacts. To improve robustness in these scenarios, we propose a methodology called Distortion-Adaptive Learned Invariance for Identification (DaliID) models. We contend that distortion augmentations, which degrade image quality, can be successfully leveraged to a greater degree than has been shown in the literature. Aided by an adaptive weighting schedule, a novel distortion augmentation is applied at severe levels during training. This training strategy increases feature-level invariance to distortions and decreases domain shift to unconstrained scenarios. At inference, we use a magnitude-weighted fusion of features from parallel models to retain robustness across the range of images. DaliID models achieve state-of-the-art (SOTA) for both face recognition and person re-identification on seven benchmark datasets, including IJB-S, TinyFace, DeepChange, and MSMT17. Additionally, we provide recaptured evaluation data at a distance of 750+ meters and further validate on real long-distance face imagery.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
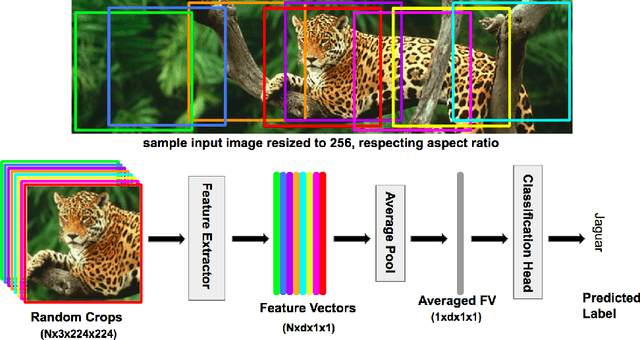
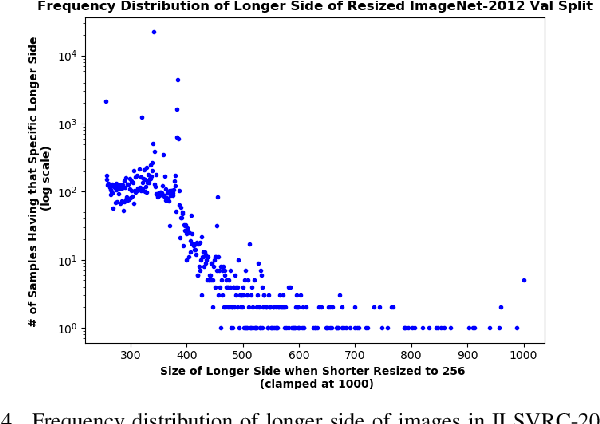
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Self-Supervised Features Improve Open-World Learning
Feb 15, 2021
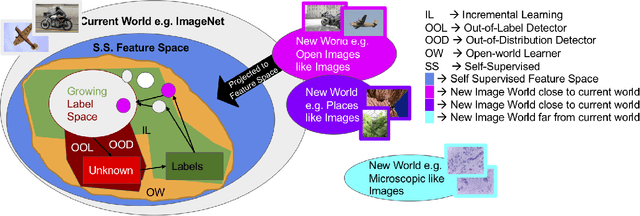
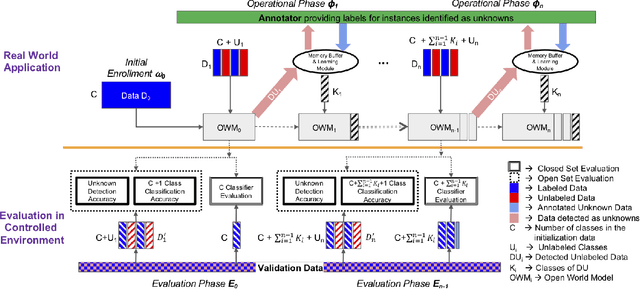
This is a position paper that addresses the problem of Open-World learning while proposing for the underlying feature representation to be learnt using self-supervision. We also present an unifying open-world framework combining three individual research dimensions which have been explored independently \ie Incremental Learning, Out-of-Distribution detection and Open-World learning. We observe that the supervised feature representations are limited and degenerate for the Open-World setting and unsupervised feature representation is native to each of these three problem domains. Under an unsupervised feature representation, we categorize the problem of detecting unknowns as either Out-of-Label-space or Out-of-Distribution detection, depending on the data used during system training versus system testing. The incremental learning component of our pipeline is a zero-exemplar online model which performs comparatively against state-of-the-art on ImageNet-100 protocol and does not require any back-propagation or retraining of the underlying deep-network. It further outperforms the current state-of-the-art by simply using the same number of exemplars as its counterparts. To evaluate our approach for Open-World learning, we propose a new comprehensive protocol and evaluate its performance in both Out-of-Label and Out-of-Distribution settings for each incremental stage. We also demonstrate the adaptability of our approach by showing how it can work as a plug-in with any of the recently proposed self-supervised feature representation methods.
Open-World Learning Without Labels
Dec 14, 2020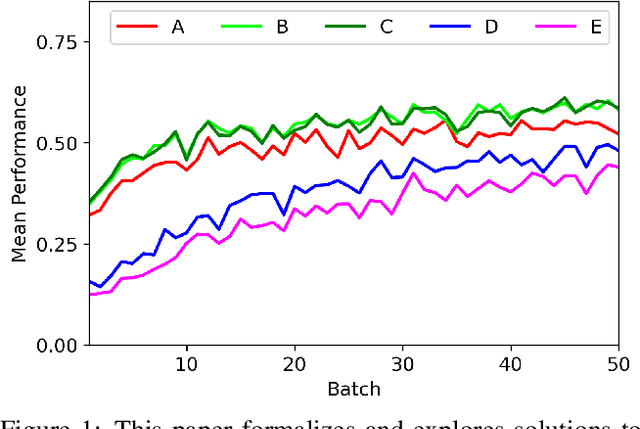

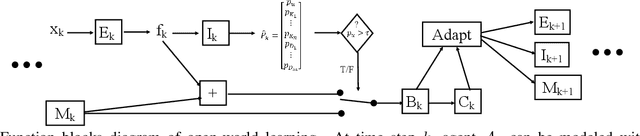
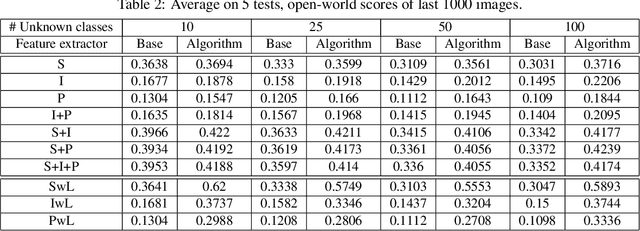
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
Automatic Open-World Reliability Assessment
Nov 11, 2020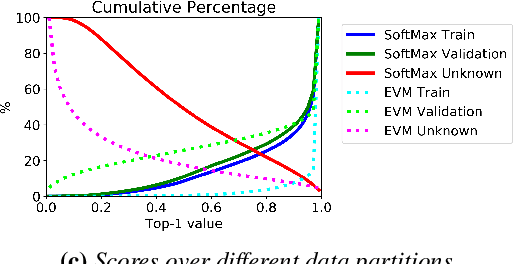
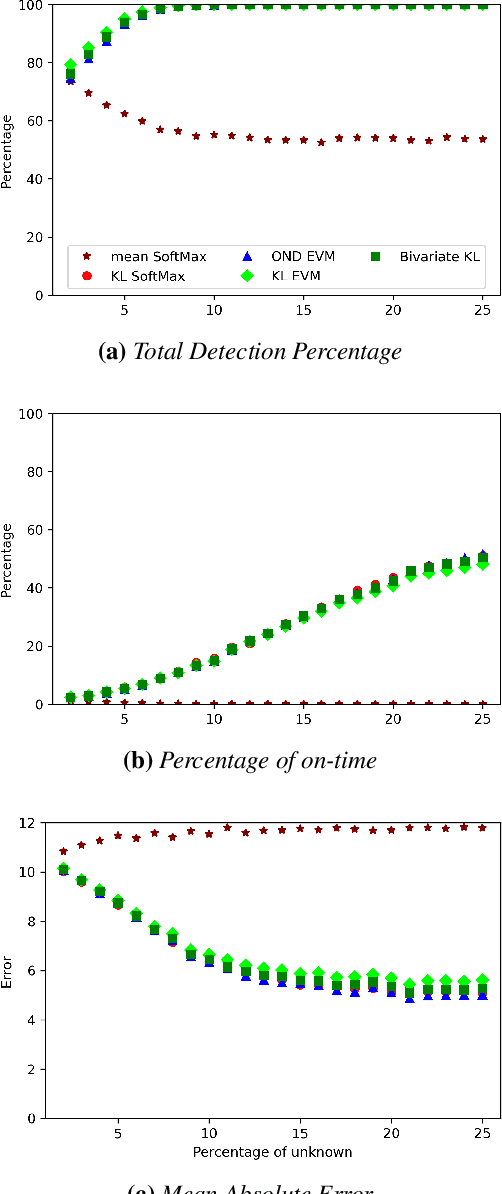
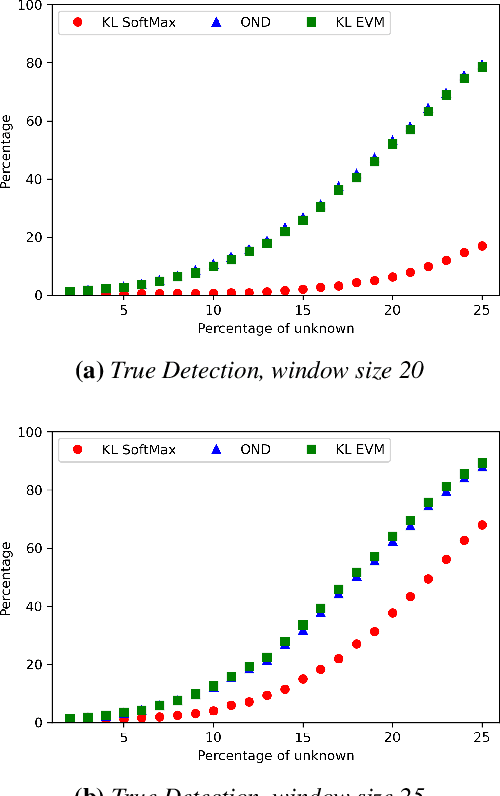
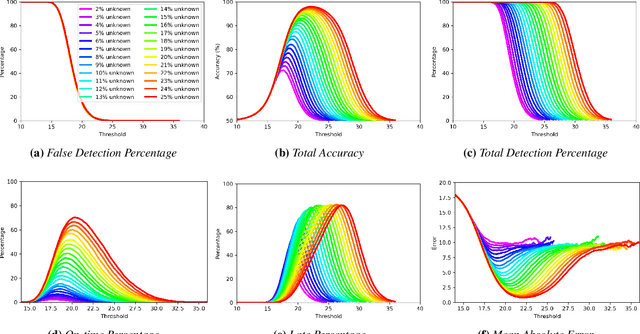
Image classification in the open-world must handle out-of-distribution (OOD) images. Systems should ideally reject OOD images, or they will map atop of known classes and reduce reliability. Using open-set classifiers that can reject OOD inputs can help. However, optimal accuracy of open-set classifiers depend on the frequency of OOD data. Thus, for either standard or open-set classifiers, it is important to be able to determine when the world changes and increasing OOD inputs will result in reduced system reliability. However, during operations, we cannot directly assess accuracy as there are no labels. Thus, the reliability assessment of these classifiers must be done by human operators, made more complex because networks are not 100% accurate, so some failures are to be expected. To automate this process, herein, we formalize the open-world recognition reliability problem and propose multiple automatic reliability assessment policies to address this new problem using only the distribution of reported scores/probability data. The distributional algorithms can be applied to both classic classifiers with SoftMax as well as the open-world Extreme Value Machine (EVM) to provide automated reliability assessment. We show that all of the new algorithms significantly outperform detection using the mean of SoftMax.
* 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)