 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore Normalization for Demographic Fairness in Face Recognition
Jul 19, 2024



Fair biometric algorithms have similar verification performance across different demographic groups given a single decision threshold. Unfortunately, for state-of-the-art face recognition networks, score distributions differ between demographics. Contrary to work that tries to align those distributions by extra training or fine-tuning, we solely focus on score post-processing methods. As proved, well-known sample-centered score normalization techniques, Z-norm and T-norm, do not improve fairness for high-security operating points. Thus, we extend the standard Z/T-norm to integrate demographic information in normalization. Additionally, we investigate several possibilities to incorporate cohort similarities for both genuine and impostor pairs per demographic to improve fairness across different operating points. We run experiments on two datasets with different demographics (gender and ethnicity) and show that our techniques generally improve the overall fairness of five state-of-the-art pre-trained face recognition networks, without downgrading verification performance. We also indicate that an equal contribution of False Match Rate (FMR) and False Non-Match Rate (FNMR) in fairness evaluation is required for the highest gains. Code and protocols are available.
Open-Set Face Recognition with Maximal Entropy and Objectosphere Loss
Nov 01, 2023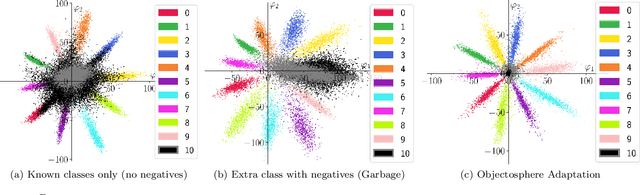
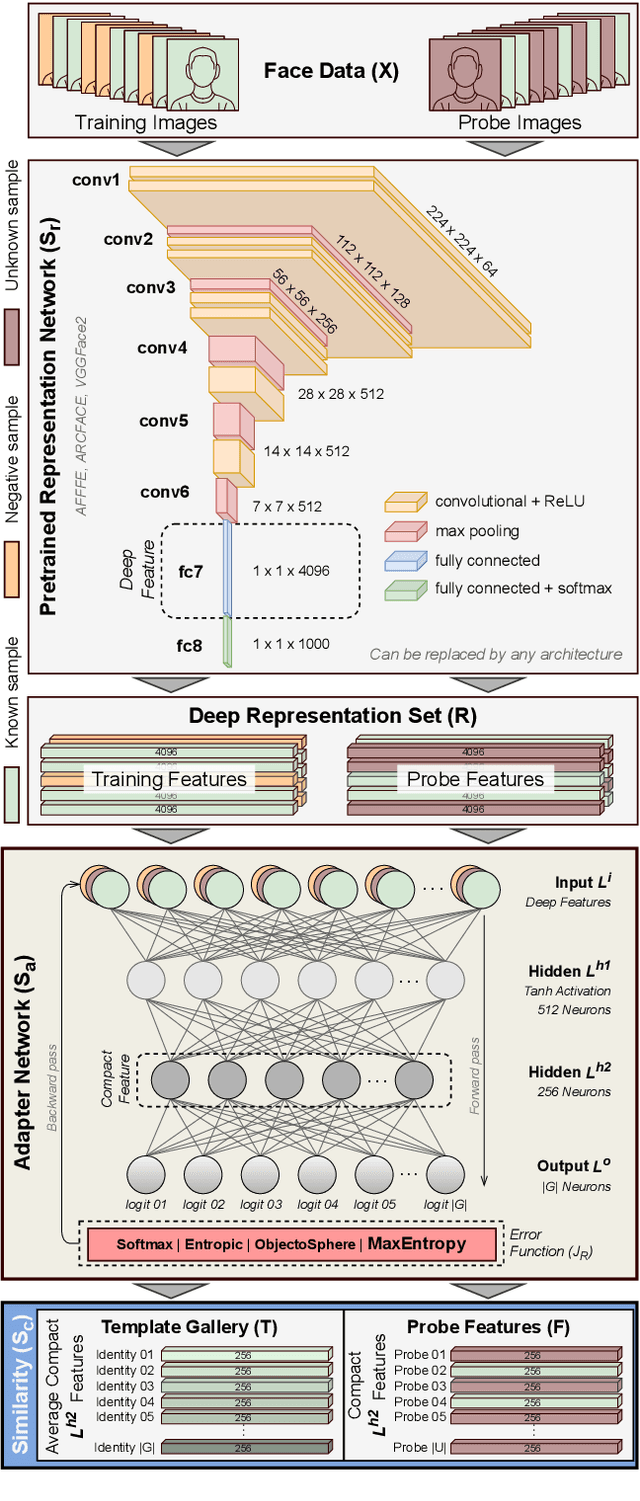
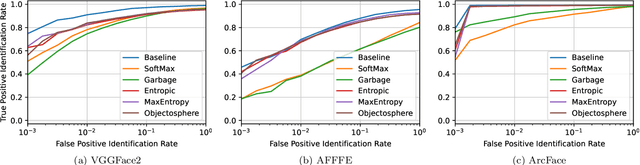
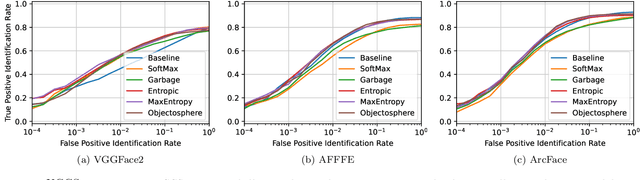
Open-set face recognition characterizes a scenario where unknown individuals, unseen during the training and enrollment stages, appear on operation time. This work concentrates on watchlists, an open-set task that is expected to operate at a low False Positive Identification Rate and generally includes only a few enrollment samples per identity. We introduce a compact adapter network that benefits from additional negative face images when combined with distinct cost functions, such as Objectosphere Loss (OS) and the proposed Maximal Entropy Loss (MEL). MEL modifies the traditional Cross-Entropy loss in favor of increasing the entropy for negative samples and attaches a penalty to known target classes in pursuance of gallery specialization. The proposed approach adopts pre-trained deep neural networks (DNNs) for face recognition as feature extractors. Then, the adapter network takes deep feature representations and acts as a substitute for the output layer of the pre-trained DNN in exchange for an agile domain adaptation. Promising results have been achieved following open-set protocols for three different datasets: LFW, IJB-C, and UCCS as well as state-of-the-art performance when supplementary negative data is properly selected to fine-tune the adapter network.
Eight Years of Face Recognition Research: Reproducibility, Achievements and Open Issues
Aug 09, 2022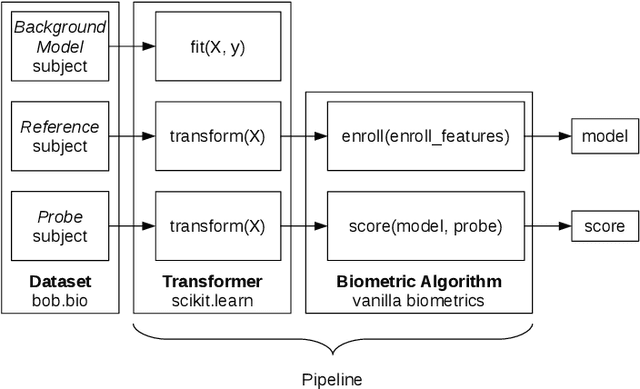
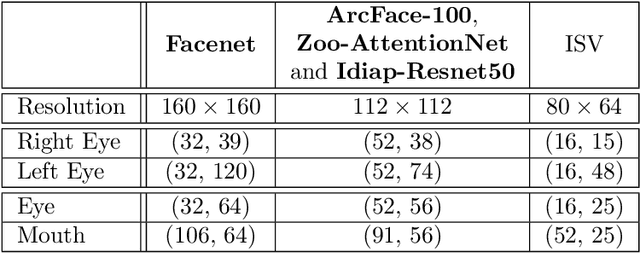

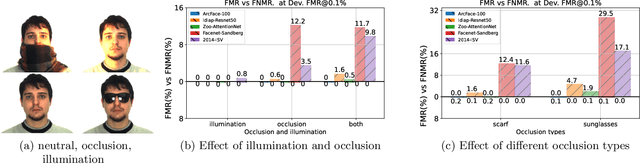
Automatic face recognition is a research area with high popularity. Many different face recognition algorithms have been proposed in the last thirty years of intensive research in the field. With the popularity of deep learning and its capability to solve a huge variety of different problems, face recognition researchers have concentrated effort on creating better models under this paradigm. From the year 2015, state-of-the-art face recognition has been rooted in deep learning models. Despite the availability of large-scale and diverse datasets for evaluating the performance of face recognition algorithms, many of the modern datasets just combine different factors that influence face recognition, such as face pose, occlusion, illumination, facial expression and image quality. When algorithms produce errors on these datasets, it is not clear which of the factors has caused this error and, hence, there is no guidance in which direction more research is required. This work is a followup from our previous works developed in 2014 and eventually published in 2016, showing the impact of various facial aspects on face recognition algorithms. By comparing the current state-of-the-art with the best systems from the past, we demonstrate that faces under strong occlusions, some types of illumination, and strong expressions are problems mastered by deep learning algorithms, whereas recognition with low-resolution images, extreme pose variations, and open-set recognition is still an open problem. To show this, we run a sequence of experiments using six different datasets and five different face recognition algorithms in an open-source and reproducible manner. We provide the source code to run all of our experiments, which is easily extensible so that utilizing your own deep network in our evaluation is just a few minutes away.