 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Advancing License Plate Super-Resolution in Real-World Scenarios: A Dataset and Benchmark
May 09, 2025Recent advancements in super-resolution for License Plate Recognition (LPR) have sought to address challenges posed by low-resolution (LR) and degraded images in surveillance, traffic monitoring, and forensic applications. However, existing studies have relied on private datasets and simplistic degradation models. To address this gap, we introduce UFPR-SR-Plates, a novel dataset containing 10,000 tracks with 100,000 paired low and high-resolution license plate images captured under real-world conditions. We establish a benchmark using multiple sequential LR and high-resolution (HR) images per vehicle -- five of each -- and two state-of-the-art models for super-resolution of license plates. We also investigate three fusion strategies to evaluate how combining predictions from a leading Optical Character Recognition (OCR) model for multiple super-resolved license plates enhances overall performance. Our findings demonstrate that super-resolution significantly boosts LPR performance, with further improvements observed when applying majority vote-based fusion techniques. Specifically, the Layout-Aware and Character-Driven Network (LCDNet) model combined with the Majority Vote by Character Position (MVCP) strategy led to the highest recognition rates, increasing from 1.7% with low-resolution images to 31.1% with super-resolution, and up to 44.7% when combining OCR outputs from five super-resolved images. These findings underscore the critical role of super-resolution and temporal information in enhancing LPR accuracy under real-world, adverse conditions. The proposed dataset is publicly available to support further research and can be accessed at: https://valfride.github.io/nascimento2024toward/
Watchlist Challenge: 3rd Open-set Face Detection and Identification
Sep 11, 2024In the current landscape of biometrics and surveillance, the ability to accurately recognize faces in uncontrolled settings is paramount. The Watchlist Challenge addresses this critical need by focusing on face detection and open-set identification in real-world surveillance scenarios. This paper presents a comprehensive evaluation of participating algorithms, using the enhanced UnConstrained College Students (UCCS) dataset with new evaluation protocols. In total, four participants submitted four face detection and nine open-set face recognition systems. The evaluation demonstrates that while detection capabilities are generally robust, closed-set identification performance varies significantly, with models pre-trained on large-scale datasets showing superior performance. However, open-set scenarios require further improvement, especially at higher true positive identification rates, i.e., lower thresholds.
Enhancing License Plate Super-Resolution: A Layout-Aware and Character-Driven Approach
Aug 27, 2024



Despite significant advancements in License Plate Recognition (LPR) through deep learning, most improvements rely on high-resolution images with clear characters. This scenario does not reflect real-world conditions where traffic surveillance often captures low-resolution and blurry images. Under these conditions, characters tend to blend with the background or neighboring characters, making accurate LPR challenging. To address this issue, we introduce a novel loss function, Layout and Character Oriented Focal Loss (LCOFL), which considers factors such as resolution, texture, and structural details, as well as the performance of the LPR task itself. We enhance character feature learning using deformable convolutions and shared weights in an attention module and employ a GAN-based training approach with an Optical Character Recognition (OCR) model as the discriminator to guide the super-resolution process. Our experimental results show significant improvements in character reconstruction quality, outperforming two state-of-the-art methods in both quantitative and qualitative measures. Our code is publicly available at https://github.com/valfride/lpsr-lacd
The Potential of Wearable Sensors for Assessing Patient Acuity in Intensive Care Unit (ICU)
Nov 03, 2023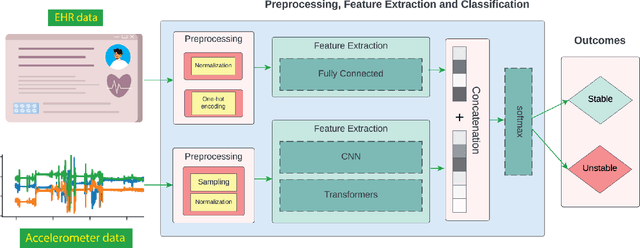
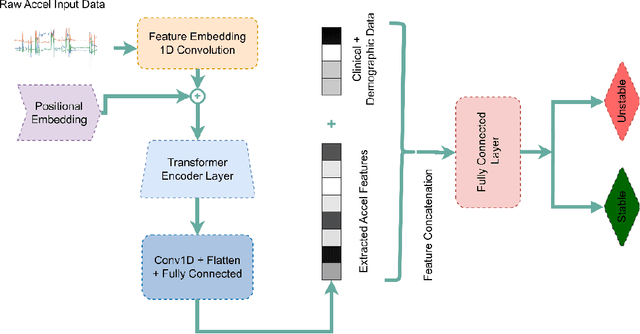

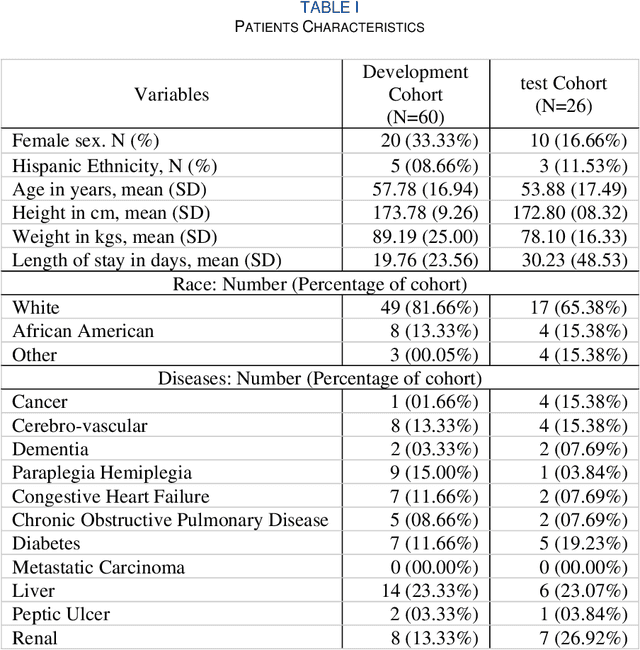
Acuity assessments are vital in critical care settings to provide timely interventions and fair resource allocation. Traditional acuity scores rely on manual assessments and documentation of physiological states, which can be time-consuming, intermittent, and difficult to use for healthcare providers. Furthermore, such scores do not incorporate granular information such as patients' mobility level, which can indicate recovery or deterioration in the ICU. We hypothesized that existing acuity scores could be potentially improved by employing Artificial Intelligence (AI) techniques in conjunction with Electronic Health Records (EHR) and wearable sensor data. In this study, we evaluated the impact of integrating mobility data collected from wrist-worn accelerometers with clinical data obtained from EHR for developing an AI-driven acuity assessment score. Accelerometry data were collected from 86 patients wearing accelerometers on their wrists in an academic hospital setting. The data was analyzed using five deep neural network models: VGG, ResNet, MobileNet, SqueezeNet, and a custom Transformer network. These models outperformed a rule-based clinical score (SOFA= Sequential Organ Failure Assessment) used as a baseline, particularly regarding the precision, sensitivity, and F1 score. The results showed that while a model relying solely on accelerometer data achieved limited performance (AUC 0.50, Precision 0.61, and F1-score 0.68), including demographic information with the accelerometer data led to a notable enhancement in performance (AUC 0.69, Precision 0.75, and F1-score 0.67). This work shows that the combination of mobility and patient information can successfully differentiate between stable and unstable states in critically ill patients.
Open-Set Face Recognition with Maximal Entropy and Objectosphere Loss
Nov 01, 2023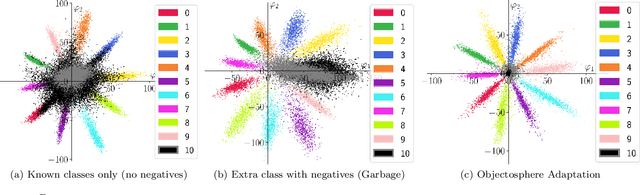
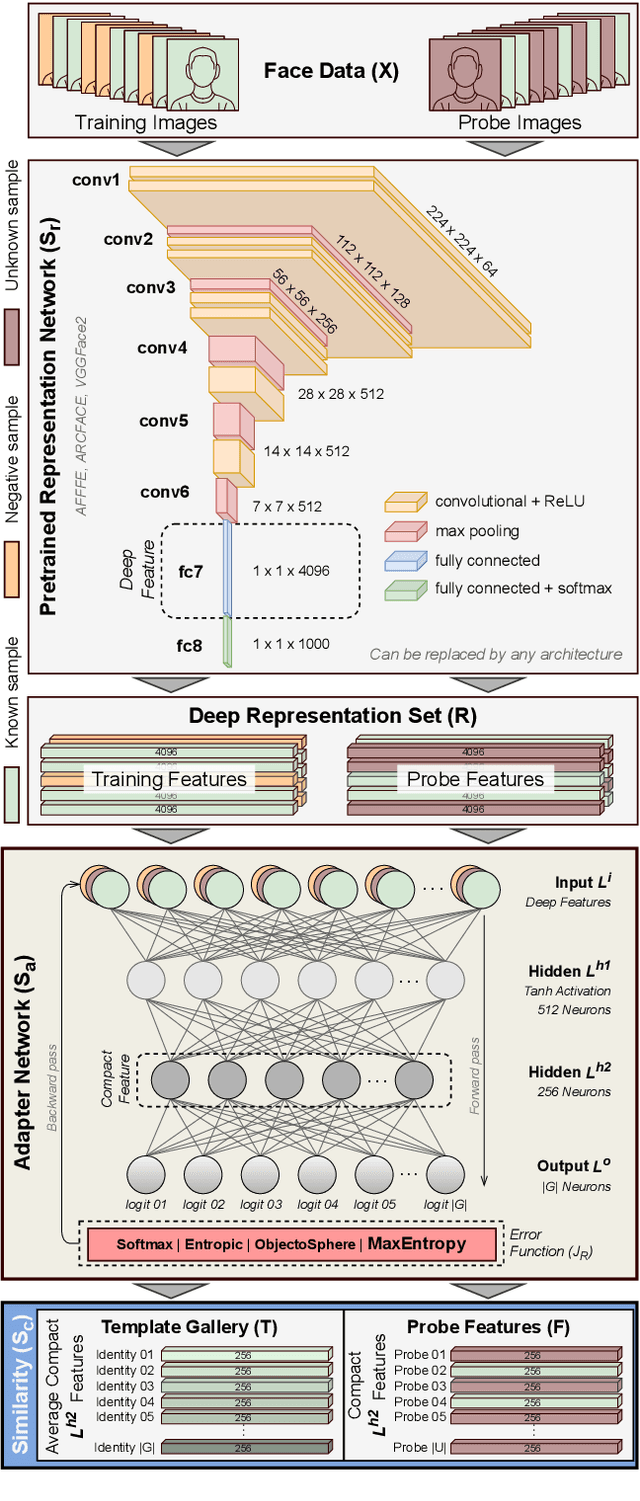
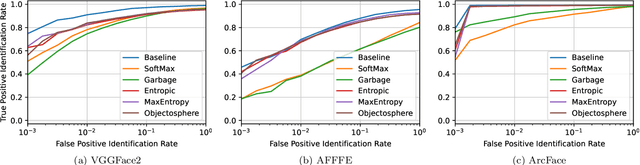
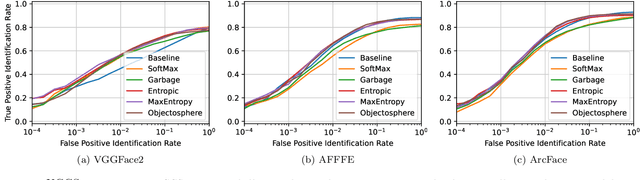
Open-set face recognition characterizes a scenario where unknown individuals, unseen during the training and enrollment stages, appear on operation time. This work concentrates on watchlists, an open-set task that is expected to operate at a low False Positive Identification Rate and generally includes only a few enrollment samples per identity. We introduce a compact adapter network that benefits from additional negative face images when combined with distinct cost functions, such as Objectosphere Loss (OS) and the proposed Maximal Entropy Loss (MEL). MEL modifies the traditional Cross-Entropy loss in favor of increasing the entropy for negative samples and attaches a penalty to known target classes in pursuance of gallery specialization. The proposed approach adopts pre-trained deep neural networks (DNNs) for face recognition as feature extractors. Then, the adapter network takes deep feature representations and acts as a substitute for the output layer of the pre-trained DNN in exchange for an agile domain adaptation. Promising results have been achieved following open-set protocols for three different datasets: LFW, IJB-C, and UCCS as well as state-of-the-art performance when supplementary negative data is properly selected to fine-tune the adapter network.
Open-set Face Recognition with Neural Ensemble, Maximal Entropy Loss and Feature Augmentation
Aug 23, 2023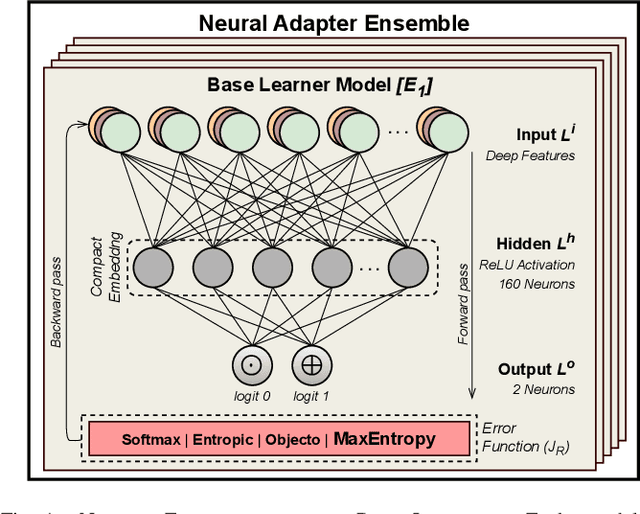
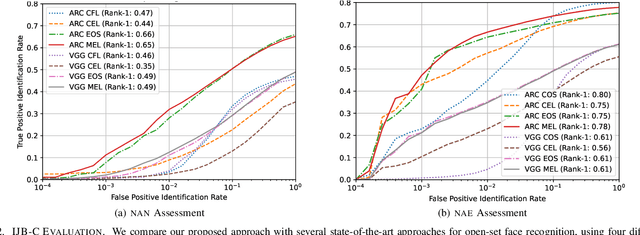

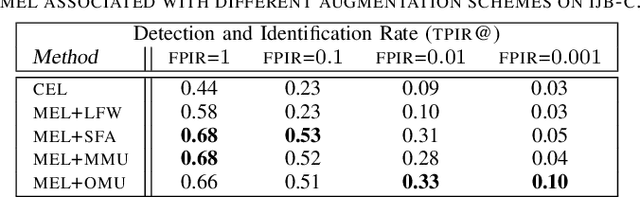
Open-set face recognition refers to a scenario in which biometric systems have incomplete knowledge of all existing subjects. Therefore, they are expected to prevent face samples of unregistered subjects from being identified as previously enrolled identities. This watchlist context adds an arduous requirement that calls for the dismissal of irrelevant faces by focusing mainly on subjects of interest. As a response, this work introduces a novel method that associates an ensemble of compact neural networks with a margin-based cost function that explores additional samples. Supplementary negative samples can be obtained from external databases or synthetically built at the representation level in training time with a new mix-up feature augmentation approach. Deep neural networks pre-trained on large face datasets serve as the preliminary feature extraction module. We carry out experiments on well-known LFW and IJB-C datasets where results show that the approach is able to boost closed and open-set identification rates.
Open-set Face Recognition using Ensembles trained on Clustered Data
Aug 14, 2023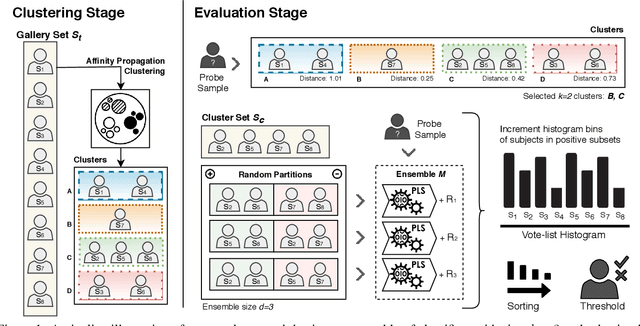
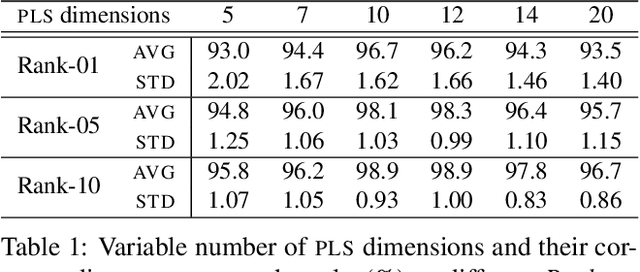
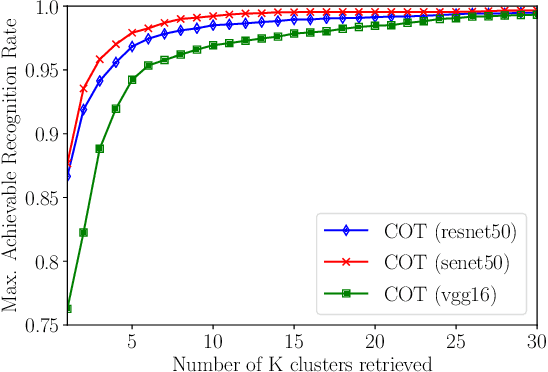
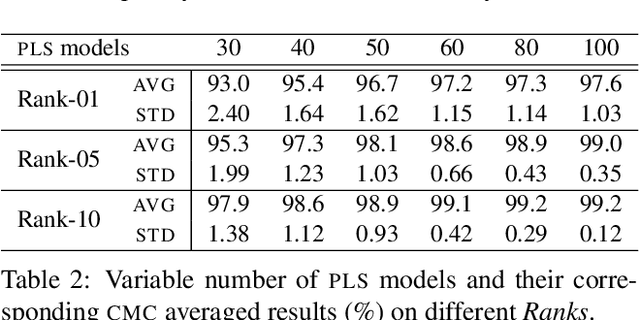
Open-set face recognition describes a scenario where unknown subjects, unseen during the training stage, appear on test time. Not only it requires methods that accurately identify individuals of interest, but also demands approaches that effectively deal with unfamiliar faces. This work details a scalable open-set face identification approach to galleries composed of hundreds and thousands of subjects. It is composed of clustering and an ensemble of binary learning algorithms that estimates when query face samples belong to the face gallery and then retrieves their correct identity. The approach selects the most suitable gallery subjects and uses the ensemble to improve prediction performance. We carry out experiments on well-known LFW and YTF benchmarks. Results show that competitive performance can be achieved even when targeting scalability.
Super-Resolution of License Plate Images Using Attention Modules and Sub-Pixel Convolution Layers
May 27, 2023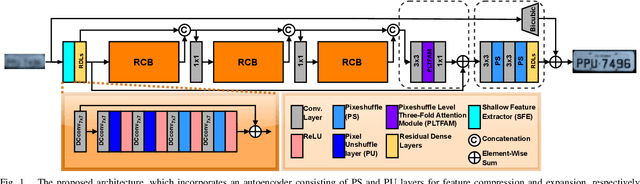
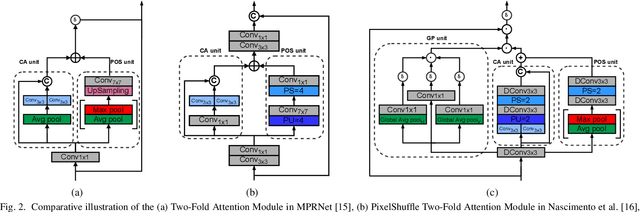


Recent years have seen significant developments in the field of License Plate Recognition (LPR) through the integration of deep learning techniques and the increasing availability of training data. Nevertheless, reconstructing license plates (LPs) from low-resolution (LR) surveillance footage remains challenging. To address this issue, we introduce a Single-Image Super-Resolution (SISR) approach that integrates attention and transformer modules to enhance the detection of structural and textural features in LR images. Our approach incorporates sub-pixel convolution layers (also known as PixelShuffle) and a loss function that uses an Optical Character Recognition (OCR) model for feature extraction. We trained the proposed architecture on synthetic images created by applying heavy Gaussian noise to high-resolution LP images from two public datasets, followed by bicubic downsampling. As a result, the generated images have a Structural Similarity Index Measure (SSIM) of less than 0.10. Our results show that our approach for reconstructing these low-resolution synthesized images outperforms existing ones in both quantitative and qualitative measures. Our code is publicly available at https://github.com/valfride/lpr-rsr-ext/
Combining Attention Module and Pixel Shuffle for License Plate Super-Resolution
Oct 30, 2022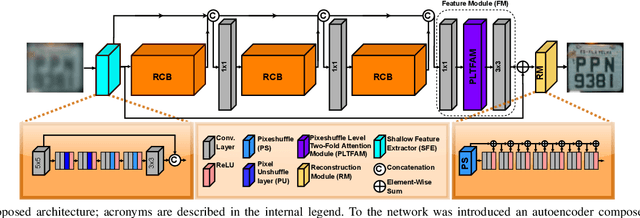
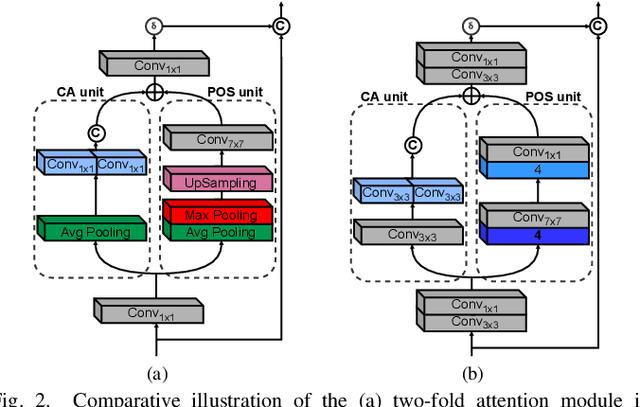


The License Plate Recognition (LPR) field has made impressive advances in the last decade due to novel deep learning approaches combined with the increased availability of training data. However, it still has some open issues, especially when the data come from low-resolution (LR) and low-quality images/videos, as in surveillance systems. This work focuses on license plate (LP) reconstruction in LR and low-quality images. We present a Single-Image Super-Resolution (SISR) approach that extends the attention/transformer module concept by exploiting the capabilities of PixelShuffle layers and that has an improved loss function based on LPR predictions. For training the proposed architecture, we use synthetic images generated by applying heavy Gaussian noise in terms of Structural Similarity Index Measure (SSIM) to the original high-resolution (HR) images. In our experiments, the proposed method outperformed the baselines both quantitatively and qualitatively. The datasets we created for this work are publicly available to the research community at https://github.com/valfride/lpr-rsr/
Face Attributes as Cues for Deep Face Recognition Understanding
May 14, 2021

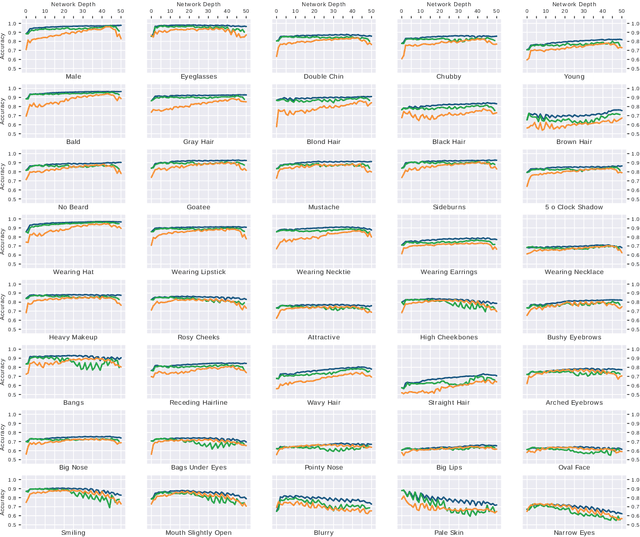

Deeply learned representations are the state-of-the-art descriptors for face recognition methods. These representations encode latent features that are difficult to explain, compromising the confidence and interpretability of their predictions. Most attempts to explain deep features are visualization techniques that are often open to interpretation. Instead of relying only on visualizations, we use the outputs of hidden layers to predict face attributes. The obtained performance is an indicator of how well the attribute is implicitly learned in that layer of the network. Using a variable selection technique, we also analyze how these semantic concepts are distributed inside each layer, establishing the precise location of relevant neurons for each attribute. According to our experiments, gender, eyeglasses and hat usage can be predicted with over 96% accuracy even when only a single neural output is used to predict each attribute. These performances are less than 3 percentage points lower than the ones achieved by deep supervised face attribute networks. In summary, our experiments show that, inside DCNNs optimized for face identification, there exists latent neurons encoding face attributes almost as accurately as DCNNs optimized for these attributes.