 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANDARIN: Mixture-of-Experts Framework for Dynamic Delirium and Coma Prediction in ICU Patients: Development and Validation of an Acute Brain Dysfunction Prediction Model
Mar 08, 2025Acute brain dysfunction (ABD) is a common, severe ICU complication, presenting as delirium or coma and leading to prolonged stays, increased mortality, and cognitive decline. Traditional screening tools like the Glasgow Coma Scale (GCS), Confusion Assessment Method (CAM), and Richmond Agitation-Sedation Scale (RASS) rely on intermittent assessments, causing delays and inconsistencies. In this study, we propose MANDARIN (Mixture-of-Experts Framework for Dynamic Delirium and Coma Prediction in ICU Patients), a 1.5M-parameter mixture-of-experts neural network to predict ABD in real-time among ICU patients. The model integrates temporal and static data from the ICU to predict the brain status in the next 12 to 72 hours, using a multi-branch approach to account for current brain status. The MANDARIN model was trained on data from 92,734 patients (132,997 ICU admissions) from 2 hospitals between 2008-2019 and validated externally on data from 11,719 patients (14,519 ICU admissions) from 15 hospitals and prospectively on data from 304 patients (503 ICU admissions) from one hospital in 2021-2024. Three datasets were used: the University of Florida Health (UFH) dataset, the electronic ICU Collaborative Research Database (eICU), and the Medical Information Mart for Intensive Care (MIMIC)-IV dataset. MANDARIN significantly outperforms the baseline neurological assessment scores (GCS, CAM, and RASS) for delirium prediction in both external (AUROC 75.5% CI: 74.2%-76.8% vs 68.3% CI: 66.9%-69.5%) and prospective (AUROC 82.0% CI: 74.8%-89.2% vs 72.7% CI: 65.5%-81.0%) cohorts, as well as for coma prediction (external AUROC 87.3% CI: 85.9%-89.0% vs 72.8% CI: 70.6%-74.9%, and prospective AUROC 93.4% CI: 88.5%-97.9% vs 67.7% CI: 57.7%-76.8%) with a 12-hour lead time. This tool has the potential to assist clinicians in decision-making by continuously monitoring the brain status of patients in the ICU.
MANGO: Multimodal Acuity traNsformer for intelliGent ICU Outcomes
Dec 13, 2024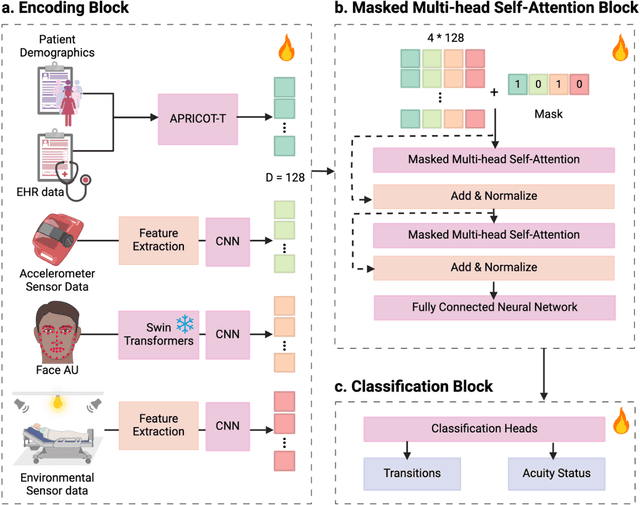
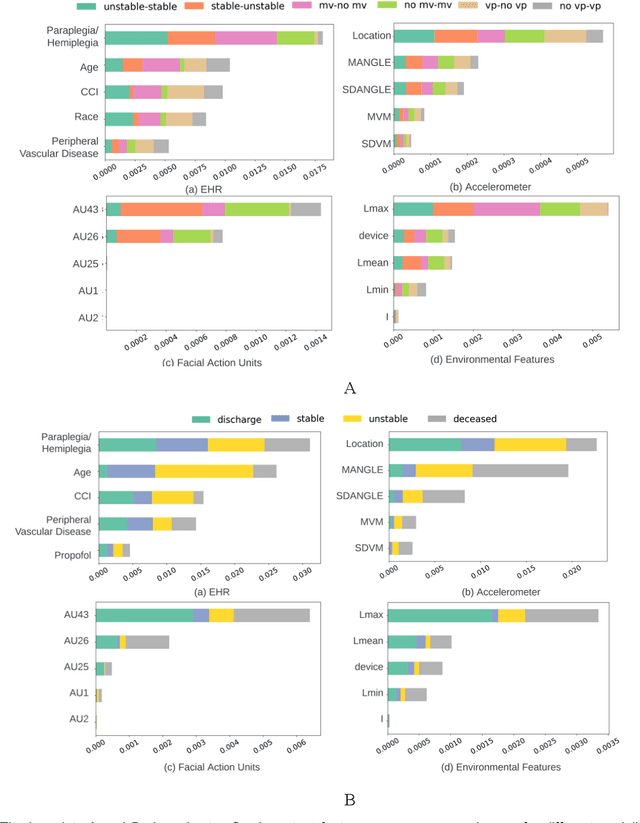
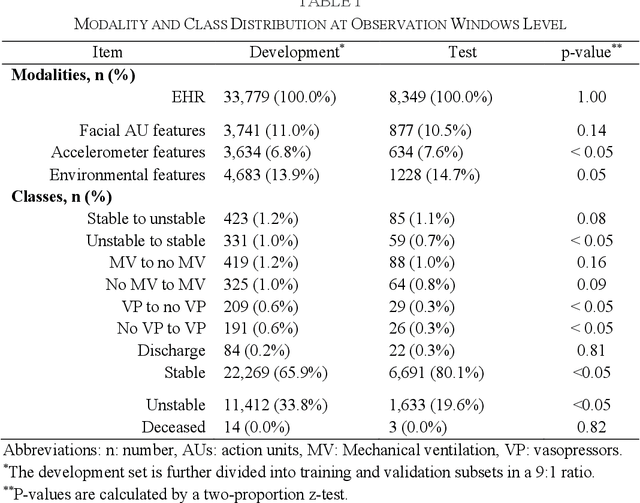

Estimation of patient acuity in the Intensive Care Unit (ICU) is vital to ensure timely and appropriate interventions. Advances in artificial intelligence (AI) technologies have significantly improved the accuracy of acuity predictions. However, prior studies using machine learning for acuity prediction have predominantly relied on electronic health records (EHR) data, often overlooking other critical aspects of ICU stay, such as patient mobility, environmental factors, and facial cues indicating pain or agitation. To address this gap, we present MANGO: the Multimodal Acuity traNsformer for intelliGent ICU Outcomes, designed to enhance the prediction of patient acuity states, transitions, and the need for life-sustaining therapy. We collected a multimodal dataset ICU-Multimodal, incorporating four key modalities, EHR data, wearable sensor data, video of patient's facial cues, and ambient sensor data, which we utilized to train MANGO. The MANGO model employs a multimodal feature fusion network powered by Transformer masked self-attention method, enabling it to capture and learn complex interactions across these diverse data modalities even when some modalities are absent. Our results demonstrated that integrating multiple modalities significantly improved the model's ability to predict acuity status, transitions, and the need for life-sustaining therapy. The best-performing models achieved an area under the receiver operating characteristic curve (AUROC) of 0.76 (95% CI: 0.72-0.79) for predicting transitions in acuity status and the need for life-sustaining therapy, while 0.82 (95% CI: 0.69-0.89) for acuity status prediction...
The Potential of Wearable Sensors for Assessing Patient Acuity in Intensive Care Unit (ICU)
Nov 03, 2023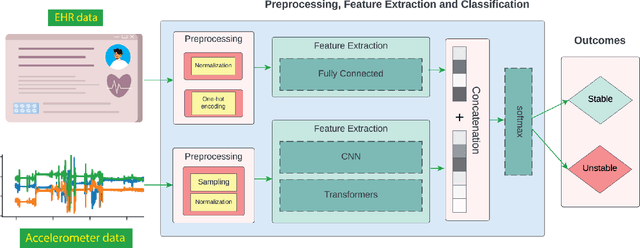
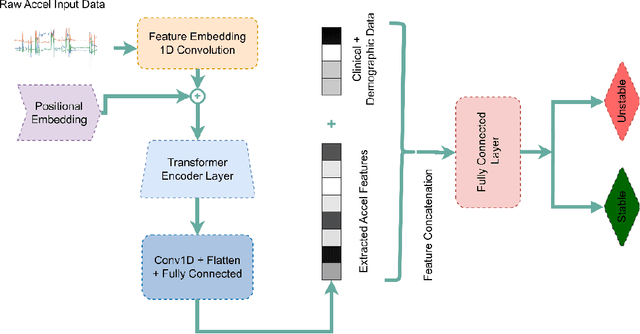

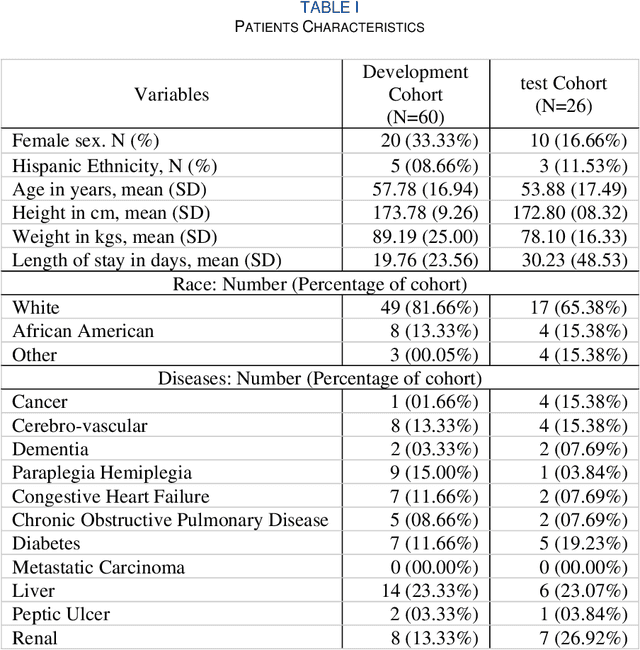
Acuity assessments are vital in critical care settings to provide timely interventions and fair resource allocation. Traditional acuity scores rely on manual assessments and documentation of physiological states, which can be time-consuming, intermittent, and difficult to use for healthcare providers. Furthermore, such scores do not incorporate granular information such as patients' mobility level, which can indicate recovery or deterioration in the ICU. We hypothesized that existing acuity scores could be potentially improved by employing Artificial Intelligence (AI) techniques in conjunction with Electronic Health Records (EHR) and wearable sensor data. In this study, we evaluated the impact of integrating mobility data collected from wrist-worn accelerometers with clinical data obtained from EHR for developing an AI-driven acuity assessment score. Accelerometry data were collected from 86 patients wearing accelerometers on their wrists in an academic hospital setting. The data was analyzed using five deep neural network models: VGG, ResNet, MobileNet, SqueezeNet, and a custom Transformer network. These models outperformed a rule-based clinical score (SOFA= Sequential Organ Failure Assessment) used as a baseline, particularly regarding the precision, sensitivity, and F1 score. The results showed that while a model relying solely on accelerometer data achieved limited performance (AUC 0.50, Precision 0.61, and F1-score 0.68), including demographic information with the accelerometer data led to a notable enhancement in performance (AUC 0.69, Precision 0.75, and F1-score 0.67). This work shows that the combination of mobility and patient information can successfully differentiate between stable and unstable states in critically ill patients.
Transformers in Healthcare: A Survey
Jun 30, 2023



With Artificial Intelligence (AI) increasingly permeating various aspects of society, including healthcare, the adoption of the Transformers neural network architecture is rapidly changing many applications. Transformer is a type of deep learning architecture initially developed to solve general-purpose Natural Language Processing (NLP) tasks and has subsequently been adapted in many fields, including healthcare. In this survey paper, we provide an overview of how this architecture has been adopted to analyze various forms of data, including medical imaging, structured and unstructured Electronic Health Records (EHR), social media, physiological signals, and biomolecular sequences. Those models could help in clinical diagnosis, report generation, data reconstruction, and drug/protein synthesis. We identified relevant studies using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. We also discuss the benefits and limitations of using transformers in healthcare and examine issues such as computational cost, model interpretability, fairness, alignment with human values, ethical implications, and environmental impact.
Predicting risk of delirium from ambient noise and light information in the ICU
Mar 11, 2023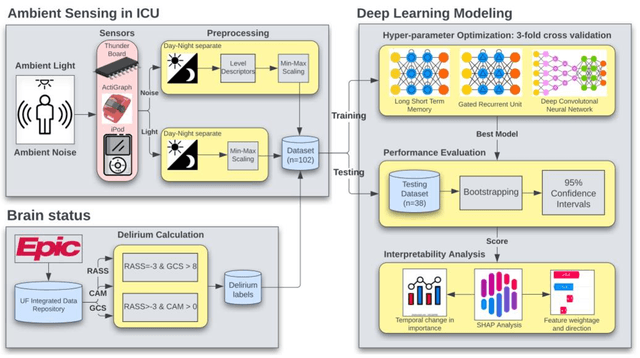
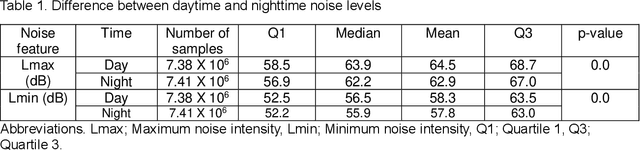
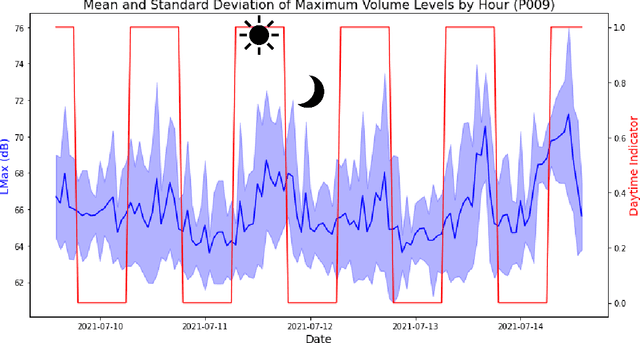
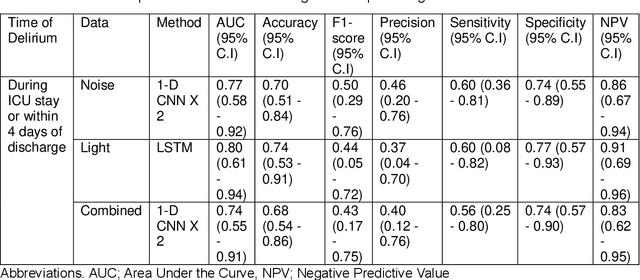
Existing Intensive Care Unit (ICU) delirium prediction models do not consider environmental factors despite strong evidence of their influence on delirium. This study reports the first deep-learning based delirium prediction model for ICU patients using only ambient noise and light information. Ambient light and noise intensities were measured from ICU rooms of 102 patients from May 2021 to September 2022 using Thunderboard, ActiGraph sensors and an iPod with AudioTools application. These measurements were divided into daytime (0700 to 1859) and nighttime (1900 to 0659). Deep learning models were trained using this data to predict the incidence of delirium during ICU stay or within 4 days of discharge. Finally, outcome scores were analyzed to evaluate the importance and directionality of every feature. Daytime noise levels were significantly higher than nighttime noise levels. When using only noise features or a combination of noise and light features 1-D convolutional neural networks (CNN) achieved the strongest performance: AUC=0.77, 0.74; Sensitivity=0.60, 0.56; Specificity=0.74, 0.74; Precision=0.46, 0.40 respectively. Using only light features, Long Short-Term Memory (LSTM) networks performed best: AUC=0.80, Sensitivity=0.60, Specificity=0.77, Precision=0.37. Maximum nighttime and minimum daytime noise levels were the strongest positive and negative predictors of delirium respectively. Nighttime light level was a stronger predictor of delirium than daytime light level. Total influence of light features outweighed that of noise features on the second and fourth day of ICU stay. This study shows that ambient light and noise intensities are strong predictors of long-term delirium incidence in the ICU. It reveals that daytime and nighttime environmental factors might influence delirium differently and that the importance of light and noise levels vary over the course of an ICU stay.
SkeleMotion: A New Representation of Skeleton Joint Sequences Based on Motion Information for 3D Action Recognition
Jul 30, 2019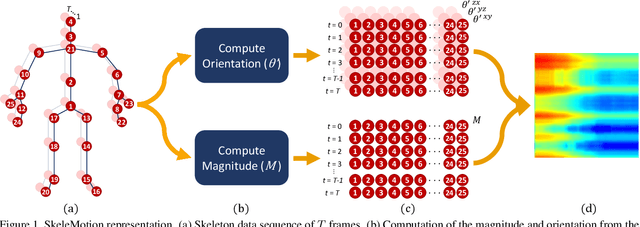
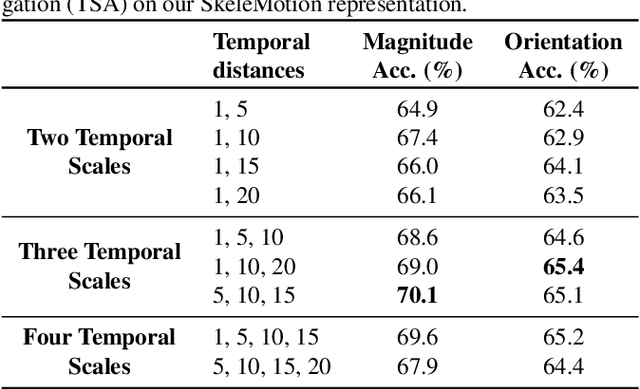
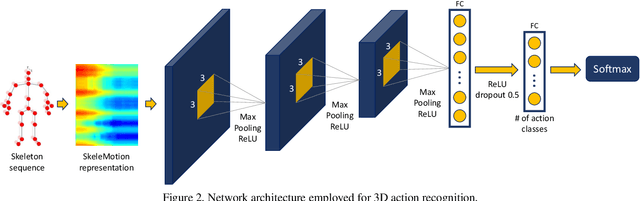
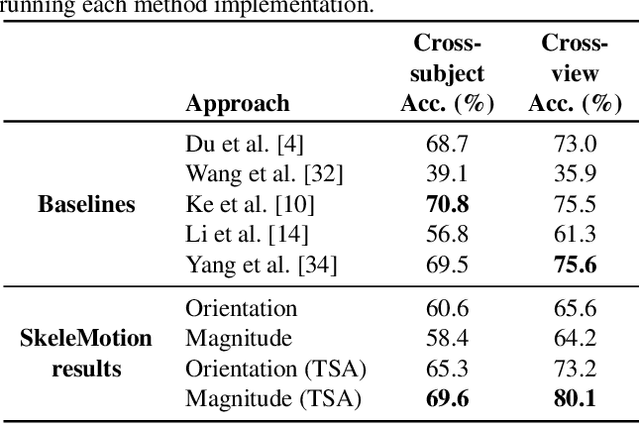
Due to the availability of large-scale skeleton datasets, 3D human action recognition has recently called the attention of computer vision community. Many works have focused on encoding skeleton data as skeleton image representations based on spatial structure of the skeleton joints, in which the temporal dynamics of the sequence is encoded as variations in columns and the spatial structure of each frame is represented as rows of a matrix. To further improve such representations, we introduce a novel skeleton image representation to be used as input of Convolutional Neural Networks (CNNs), named SkeleMotion. The proposed approach encodes the temporal dynamics by explicitly computing the magnitude and orientation values of the skeleton joints. Different temporal scales are employed to compute motion values to aggregate more temporal dynamics to the representation making it able to capture longrange joint interactions involved in actions as well as filtering noisy motion values. Experimental results demonstrate the effectiveness of the proposed representation on 3D action recognition outperforming the state-of-the-art on NTU RGB+D 120 dataset.
Human Activity Recognition Based on Wearable Sensor Data: A Standardization of the State-of-the-Art
Jun 18, 2018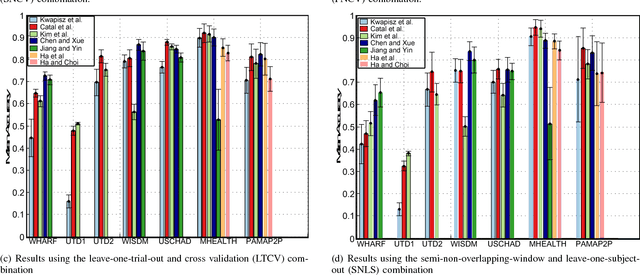
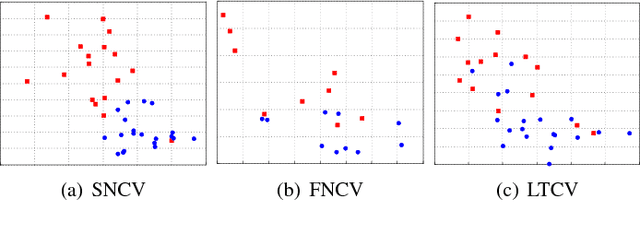
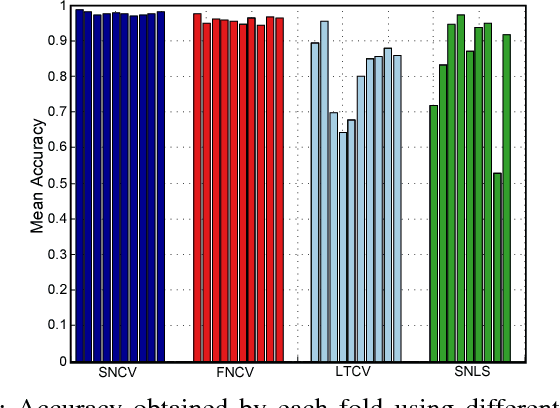
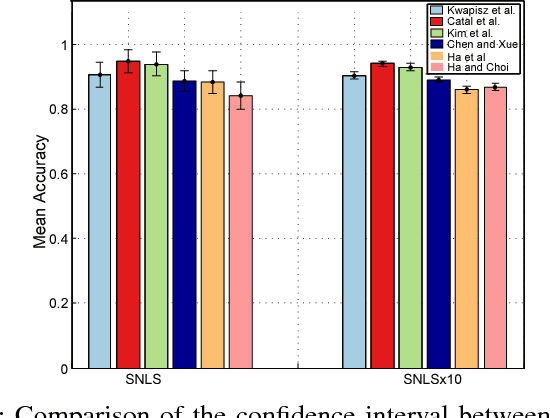
Human activity recognition based on wearable sensor data has been an attractive research topic due to its application in areas such as healthcare, homeland security and smart environments. In this context, many works have presented remarkable results using accelerometer, gyroscope and magnetometer data to represent the categories of activities. However, the current studies do not consider important issues that lead to skewed results, making hard to measure how well sensor-based human activity recognition is and preventing a direct comparison of previous works. These issues include the employed metrics, the validation protocol used, the samples generation process, and the quality of the dataset (i.e., the sampling rate and the number of activities to be recognized). We emphasize that in other research areas, such as image classification and object detection, these issues are well-defined, which brings more efforts towards the application. Inspired by this, in this work, we conduct an extensive set of experiments to indicate the vulnerable points in human activity recognition based on wearable sensor data. To this purpose, we implement and evaluate several state-of-the-art approaches, ranging from handcrafted-based methods to convolutional neural networks. Furthermore, we standardize a large number of datasets, which vary in terms of sampling rate, number of sensors, activities and subjects. According to our study, the most of evaluation types applied in the literature are not adequate to perform the activity recognition in the context of wearable sensor data, in which the recognition accuracy drops around ten percentage points when compared to the appropriate validation.
A Content-Based Late Fusion Approach Applied to Pedestrian Detection
Jun 08, 2018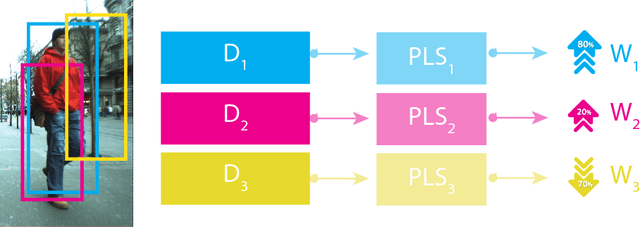
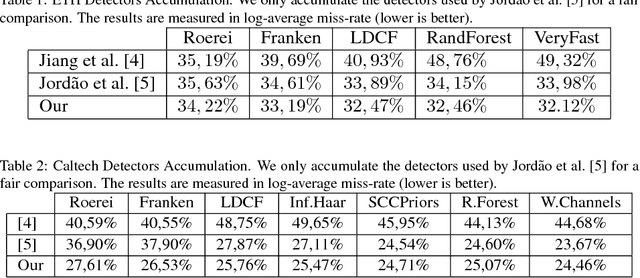

The variety of pedestrians detectors proposed in recent years has encouraged some works to fuse pedestrian detectors to achieve a more accurate detection. The intuition behind is to combine the detectors based on its spatial consensus. We propose a novel method called Content-Based Spatial Consensus (CSBC), which, in addition to relying on spatial consensus, considers the content of the detection windows to learn a weighted-fusion of pedestrian detectors. The result is a reduction in false alarms and an enhancement in the detection. In this work, we also demonstrate that there is small influence of the feature used to learn the contents of the windows of each detector, which enables our method to be efficient even employing simple features. The CSBC overcomes state-of-the-art fusion methods in the ETH dataset and in the Caltech dataset. Particularly, our method is more efficient since fewer detectors are necessary to achieve expressive results.