 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying by Proxy: Explainable and Reproducible Ensemble of Proxy Tasks for Child Sexual Abuse Imagery Classification
Jun 14, 2026Child Sexual Abuse Imagery (CSAI) classification systems are needed solutions for lessening the psychological impacts often felt by law enforcement agents responsible for evaluating these materials and for efficient removal of these materials from the web. However, due to the nature of the task, researching and developing such systems is not a trivial endeavor. The images are highly sensitive, and the related datasets are under restrictive access regimes, which means most studies in the area are not reproducible or distributable and are therefore hard to compare and validate. More concerning still, most models for this task today lack an aspect often desired by law enforcement agents: explainability. In this paper, we apply an ensemble of Proxy Tasks -- tasks that correlate to CSAI classification -- yielding improvements in reproducibility, explainability, and security for distribution. This concept is applied for the first time to real CSAI, with a novel selection of relevant Proxy Tasks (selected from the CSAI literature) and training adaptations to the original framework. Our final model achieves competitive results, yielding 91.9% balanced accuracy on the RCPD dataset with the best Proxy Task combination. We furthermore contrast these results with the best-in-class representation learning model, DINO, and show that our ensemble improves accuracy and provides explanations for its classification results, a feature that a single deep learning model can seldom provide.
CSA-Graphs: A Privacy-Preserving Structural Dataset for Child Sexual Abuse Research
Apr 08, 2026Child Sexual Abuse Imagery (CSAI) classification is an important yet challenging problem for computer vision research due to the strict legal and ethical restrictions that prevent the public sharing of CSAI datasets. This limitation hinders reproducibility and slows progress in developing automated methods. In this work, we introduce CSA-Graphs, a privacy-preserving structural dataset. Instead of releasing the original images, we provide structural representations that remove explicit visual content while preserving contextual information. CSA-Graphs includes two complementary graph-based modalities: scene graphs describing object relationships and skeleton graphs encoding human pose. Experiments show that both representations retain useful information for classifying CSAI, and that combining them further improves performance. This dataset enables broader research on computer vision methods for child safety while respecting legal and ethical constraints.
Attention over Scene Graphs: Indoor Scene Representations Toward CSAI Classification
Sep 30, 2025



Indoor scene classification is a critical task in computer vision, with wide-ranging applications that go from robotics to sensitive content analysis, such as child sexual abuse imagery (CSAI) classification. The problem is particularly challenging due to the intricate relationships between objects and complex spatial layouts. In this work, we propose the Attention over Scene Graphs for Sensitive Content Analysis (ASGRA), a novel framework that operates on structured graph representations instead of raw pixels. By first converting images into Scene Graphs and then employing a Graph Attention Network for inference, ASGRA directly models the interactions between a scene's components. This approach offers two key benefits: (i) inherent explainability via object and relationship identification, and (ii) privacy preservation, enabling model training without direct access to sensitive images. On Places8, we achieve 81.27% balanced accuracy, surpassing image-based methods. Real-world CSAI evaluation with law enforcement yields 74.27% balanced accuracy. Our results establish structured scene representations as a robust paradigm for indoor scene classification and CSAI classification. Code is publicly available at https://github.com/tutuzeraa/ASGRA.
Neglected Risks: The Disturbing Reality of Children's Images in Datasets and the Urgent Call for Accountability
Apr 20, 2025Including children's images in datasets has raised ethical concerns, particularly regarding privacy, consent, data protection, and accountability. These datasets, often built by scraping publicly available images from the Internet, can expose children to risks such as exploitation, profiling, and tracking. Despite the growing recognition of these issues, approaches for addressing them remain limited. We explore the ethical implications of using children's images in AI datasets and propose a pipeline to detect and remove such images. As a use case, we built the pipeline on a Vision-Language Model under the Visual Question Answering task and tested it on the #PraCegoVer dataset. We also evaluate the pipeline on a subset of 100,000 images from the Open Images V7 dataset to assess its effectiveness in detecting and removing images of children. The pipeline serves as a baseline for future research, providing a starting point for more comprehensive tools and methodologies. While we leverage existing models trained on potentially problematic data, our goal is to expose and address this issue. We do not advocate for training or deploying such models, but instead call for urgent community reflection and action to protect children's rights. Ultimately, we aim to encourage the research community to exercise - more than an additional - care in creating new datasets and to inspire the development of tools to protect the fundamental rights of vulnerable groups, particularly children.
Skeleton Image Representation for 3D Action Recognition based on Tree Structure and Reference Joints
Sep 11, 2019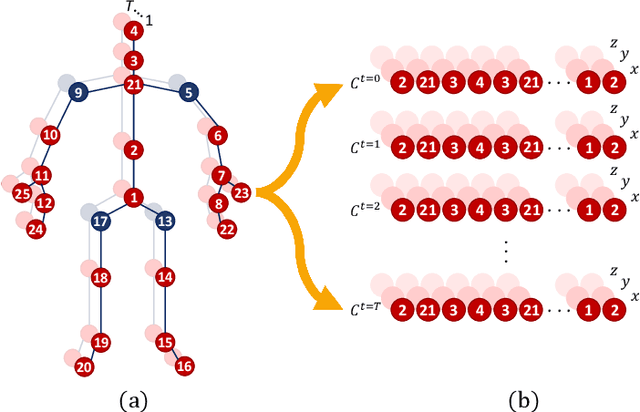
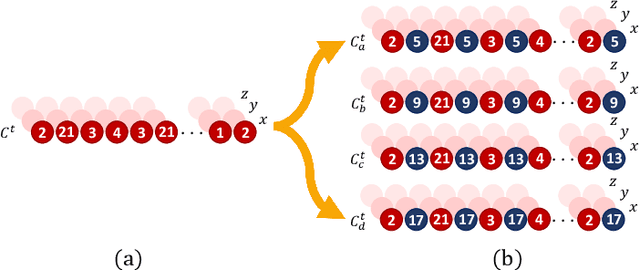
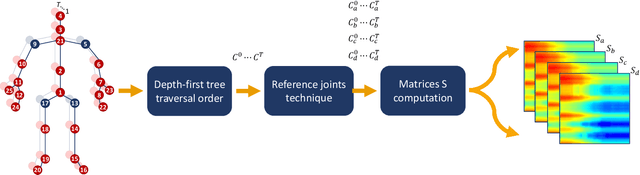
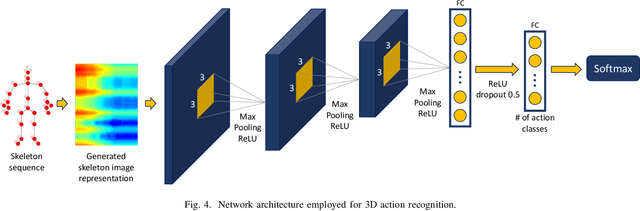
In the last years, the computer vision research community has studied on how to model temporal dynamics in videos to employ 3D human action recognition. To that end, two main baseline approaches have been researched: (i) Recurrent Neural Networks (RNNs) with Long-Short Term Memory (LSTM); and (ii) skeleton image representations used as input to a Convolutional Neural Network (CNN). Although RNN approaches present excellent results, such methods lack the ability to efficiently learn the spatial relations between the skeleton joints. On the other hand, the representations used to feed CNN approaches present the advantage of having the natural ability of learning structural information from 2D arrays (i.e., they learn spatial relations from the skeleton joints). To further improve such representations, we introduce the Tree Structure Reference Joints Image (TSRJI), a novel skeleton image representation to be used as input to CNNs. The proposed representation has the advantage of combining the use of reference joints and a tree structure skeleton. While the former incorporates different spatial relationships between the joints, the latter preserves important spatial relations by traversing a skeleton tree with a depth-first order algorithm. Experimental results demonstrate the effectiveness of the proposed representation for 3D action recognition on two datasets achieving state-of-the-art results on the recent NTU RGB+D~120 dataset.
SkeleMotion: A New Representation of Skeleton Joint Sequences Based on Motion Information for 3D Action Recognition
Jul 30, 2019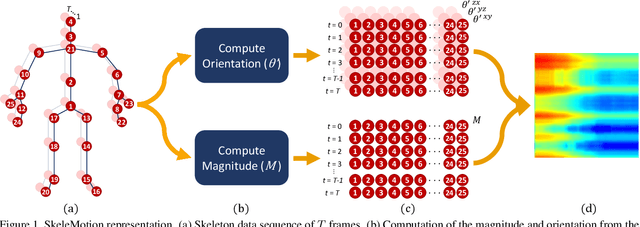
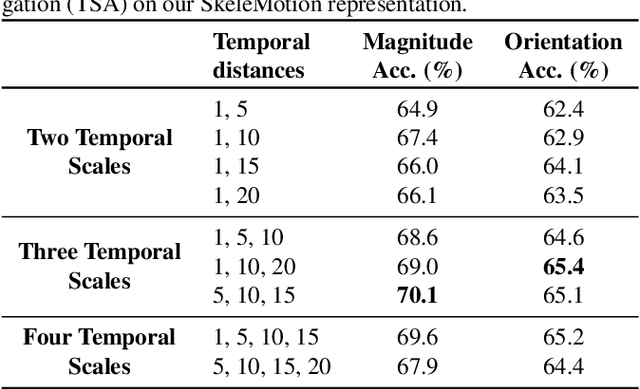
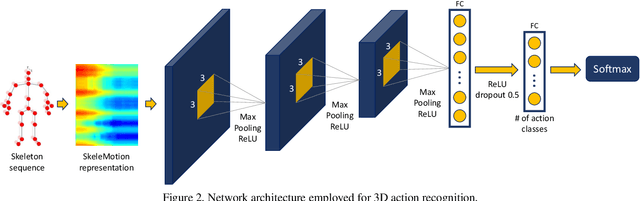
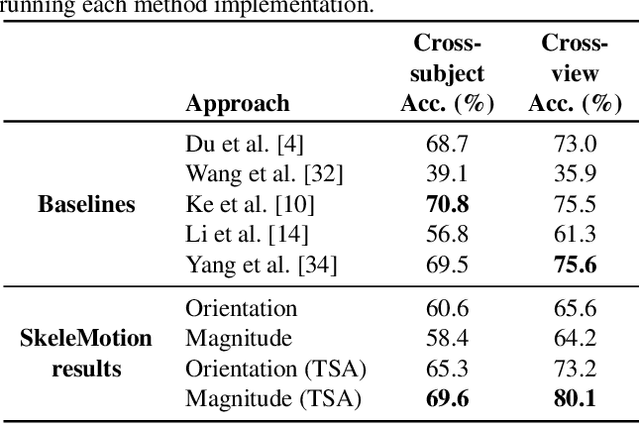
Due to the availability of large-scale skeleton datasets, 3D human action recognition has recently called the attention of computer vision community. Many works have focused on encoding skeleton data as skeleton image representations based on spatial structure of the skeleton joints, in which the temporal dynamics of the sequence is encoded as variations in columns and the spatial structure of each frame is represented as rows of a matrix. To further improve such representations, we introduce a novel skeleton image representation to be used as input of Convolutional Neural Networks (CNNs), named SkeleMotion. The proposed approach encodes the temporal dynamics by explicitly computing the magnitude and orientation values of the skeleton joints. Different temporal scales are employed to compute motion values to aggregate more temporal dynamics to the representation making it able to capture longrange joint interactions involved in actions as well as filtering noisy motion values. Experimental results demonstrate the effectiveness of the proposed representation on 3D action recognition outperforming the state-of-the-art on NTU RGB+D 120 dataset.
Activity Recognition based on a Magnitude-Orientation Stream Network
Aug 22, 2017



The temporal component of videos provides an important clue for activity recognition, as a number of activities can be reliably recognized based on the motion information. In view of that, this work proposes a novel temporal stream for two-stream convolutional networks based on images computed from the optical flow magnitude and orientation, named Magnitude-Orientation Stream (MOS), to learn the motion in a better and richer manner. Our method applies simple nonlinear transformations on the vertical and horizontal components of the optical flow to generate input images for the temporal stream. Experimental results, carried on two well-known datasets (HMDB51 and UCF101), demonstrate that using our proposed temporal stream as input to existing neural network architectures can improve their performance for activity recognition. Results demonstrate that our temporal stream provides complementary information able to improve the classical two-stream methods, indicating the suitability of our approach to be used as a temporal video representation.
A Mid-level Video Representation based on Binary Descriptors: A Case Study for Pornography Detection
May 12, 2016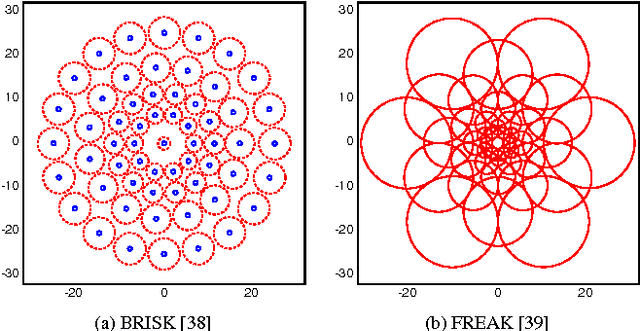
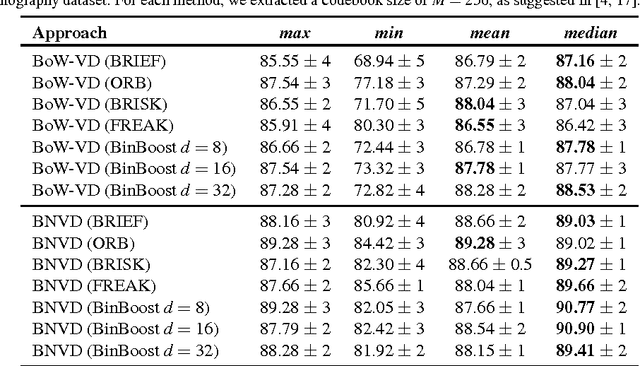
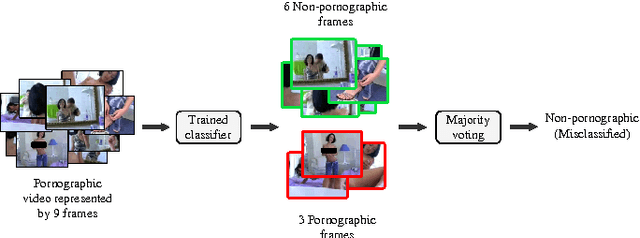

With the growing amount of inappropriate content on the Internet, such as pornography, arises the need to detect and filter such material. The reason for this is given by the fact that such content is often prohibited in certain environments (e.g., schools and workplaces) or for certain publics (e.g., children). In recent years, many works have been mainly focused on detecting pornographic images and videos based on visual content, particularly on the detection of skin color. Although these approaches provide good results, they generally have the disadvantage of a high false positive rate since not all images with large areas of skin exposure are necessarily pornographic images, such as people wearing swimsuits or images related to sports. Local feature based approaches with Bag-of-Words models (BoW) have been successfully applied to visual recognition tasks in the context of pornography detection. Even though existing methods provide promising results, they use local feature descriptors that require a high computational processing time yielding high-dimensional vectors. In this work, we propose an approach for pornography detection based on local binary feature extraction and BossaNova image representation, a BoW model extension that preserves more richly the visual information. Moreover, we propose two approaches for video description based on the combination of mid-level representations namely BossaNova Video Descriptor (BNVD) and BoW Video Descriptor (BoW-VD). The proposed techniques are promising, achieving an accuracy of 92.40%, thus reducing the classification error by 16% over the current state-of-the-art local features approach on the Pornography dataset.