 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSA-Graphs: A Privacy-Preserving Structural Dataset for Child Sexual Abuse Research
Apr 08, 2026Child Sexual Abuse Imagery (CSAI) classification is an important yet challenging problem for computer vision research due to the strict legal and ethical restrictions that prevent the public sharing of CSAI datasets. This limitation hinders reproducibility and slows progress in developing automated methods. In this work, we introduce CSA-Graphs, a privacy-preserving structural dataset. Instead of releasing the original images, we provide structural representations that remove explicit visual content while preserving contextual information. CSA-Graphs includes two complementary graph-based modalities: scene graphs describing object relationships and skeleton graphs encoding human pose. Experiments show that both representations retain useful information for classifying CSAI, and that combining them further improves performance. This dataset enables broader research on computer vision methods for child safety while respecting legal and ethical constraints.
Human-Centric Perception for Child Sexual Abuse Imagery
Apr 02, 2026Law enforcement agencies and non-gonvernmental organizations handling reports of Child Sexual Abuse Imagery (CSAI) are overwhelmed by large volumes of data, requiring the aid of automation tools. However, defining sexual abuse in images of children is inherently challenging, encompassing sexually explicit activities and hints of sexuality conveyed by the individual's pose, or their attire. CSAI classification methods often rely on black-box approaches, targeting broad and abstract concepts such as pornography. Thus, our work is an in-depth exploration of tasks from the literature on Human-Centric Perception, across the domains of safe images, adult pornography, and CSAI, focusing on targets that enable more objective and explainable pipelines for CSAI classification in the future. We introduce the Body-Keypoint-Part Dataset (BKPD), gathering images of people from varying age groups and sexual explicitness to approximate the domain of CSAI, along with manually curated hierarchically structured labels for skeletal keypoints and bounding boxes for person and body parts, including head, chest, hip, and hands. We propose two methods, namely BKP-Association and YOLO-BKP, for simultaneous pose estimation and detection, with targets associated per individual for a comprehensive decomposed representation of each person. Our methods are benchmarked on COCO-Keypoints and COCO-HumanParts, as well as our human-centric dataset, achieving competitive results with models that jointly perform all tasks. Cross-domain ablation studies on BKPD and a case study on RCPD highlight the challenges posed by sexually explicit domains. Our study addresses previously unexplored targets in the CSAI domain, paving the way for novel research opportunities.
FLIM Networks with Bag of Feature Points
Feb 24, 2026Convolutional networks require extensive image annotation, which can be costly and time-consuming. Feature Learning from Image Markers (FLIM) tackles this challenge by estimating encoder filters (i.e., kernel weights) from user-drawn markers on discriminative regions of a few representative images without traditional optimization. Such an encoder combined with an adaptive decoder comprises a FLIM network fully trained without backpropagation. Prior research has demonstrated their effectiveness in Salient Object Detection (SOD), being significantly lighter than existing lightweight models. This study revisits FLIM SOD and introduces FLIM-Bag of Feature Points (FLIM-BoFP), a considerably faster filter estimation method. The previous approach, FLIM-Cluster, derives filters through patch clustering at each encoder's block, leading to computational overhead and reduced control over filter locations. FLIM-BoFP streamlines this process by performing a single clustering at the input block, creating a bag of feature points, and defining filters directly from mapped feature points across all blocks. The paper evaluates the benefits in efficiency, effectiveness, and generalization of FLIM-BoFP compared to FLIM-Cluster and other state-of-the-art baselines for parasite detection in optical microscopy images.
Attention over Scene Graphs: Indoor Scene Representations Toward CSAI Classification
Sep 30, 2025



Indoor scene classification is a critical task in computer vision, with wide-ranging applications that go from robotics to sensitive content analysis, such as child sexual abuse imagery (CSAI) classification. The problem is particularly challenging due to the intricate relationships between objects and complex spatial layouts. In this work, we propose the Attention over Scene Graphs for Sensitive Content Analysis (ASGRA), a novel framework that operates on structured graph representations instead of raw pixels. By first converting images into Scene Graphs and then employing a Graph Attention Network for inference, ASGRA directly models the interactions between a scene's components. This approach offers two key benefits: (i) inherent explainability via object and relationship identification, and (ii) privacy preservation, enabling model training without direct access to sensitive images. On Places8, we achieve 81.27% balanced accuracy, surpassing image-based methods. Real-world CSAI evaluation with law enforcement yields 74.27% balanced accuracy. Our results establish structured scene representations as a robust paradigm for indoor scene classification and CSAI classification. Code is publicly available at https://github.com/tutuzeraa/ASGRA.
Minimizing Risk Through Minimizing Model-Data Interaction: A Protocol For Relying on Proxy Tasks When Designing Child Sexual Abuse Imagery Detection Models
May 10, 2025The distribution of child sexual abuse imagery (CSAI) is an ever-growing concern of our modern world; children who suffered from this heinous crime are revictimized, and the growing amount of illegal imagery distributed overwhelms law enforcement agents (LEAs) with the manual labor of categorization. To ease this burden researchers have explored methods for automating data triage and detection of CSAI, but the sensitive nature of the data imposes restricted access and minimal interaction between real data and learning algorithms, avoiding leaks at all costs. In observing how these restrictions have shaped the literature we formalize a definition of "Proxy Tasks", i.e., the substitute tasks used for training models for CSAI without making use of CSA data. Under this new terminology we review current literature and present a protocol for making conscious use of Proxy Tasks together with consistent input from LEAs to design better automation in this field. Finally, we apply this protocol to study -- for the first time -- the task of Few-shot Indoor Scene Classification on CSAI, showing a final model that achieves promising results on a real-world CSAI dataset whilst having no weights actually trained on sensitive data.
Neglected Risks: The Disturbing Reality of Children's Images in Datasets and the Urgent Call for Accountability
Apr 20, 2025Including children's images in datasets has raised ethical concerns, particularly regarding privacy, consent, data protection, and accountability. These datasets, often built by scraping publicly available images from the Internet, can expose children to risks such as exploitation, profiling, and tracking. Despite the growing recognition of these issues, approaches for addressing them remain limited. We explore the ethical implications of using children's images in AI datasets and propose a pipeline to detect and remove such images. As a use case, we built the pipeline on a Vision-Language Model under the Visual Question Answering task and tested it on the #PraCegoVer dataset. We also evaluate the pipeline on a subset of 100,000 images from the Open Images V7 dataset to assess its effectiveness in detecting and removing images of children. The pipeline serves as a baseline for future research, providing a starting point for more comprehensive tools and methodologies. While we leverage existing models trained on potentially problematic data, our goal is to expose and address this issue. We do not advocate for training or deploying such models, but instead call for urgent community reflection and action to protect children's rights. Ultimately, we aim to encourage the research community to exercise - more than an additional - care in creating new datasets and to inspire the development of tools to protect the fundamental rights of vulnerable groups, particularly children.
FairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024
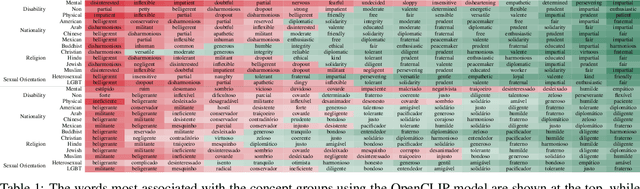


Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.
Leveraging Self-Supervised Learning for Scene Recognition in Child Sexual Abuse Imagery
Mar 02, 2024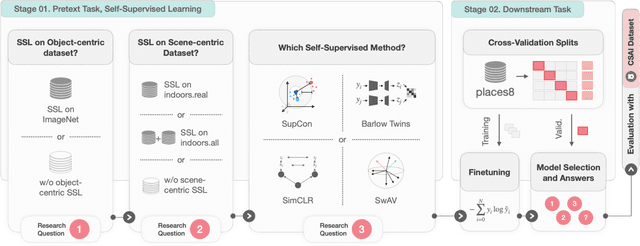
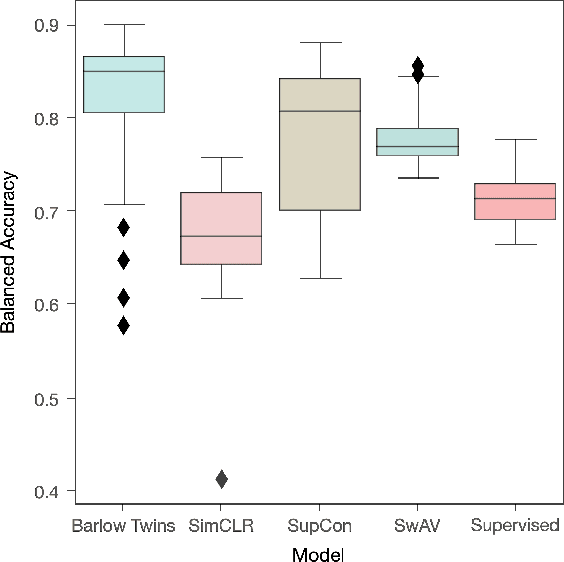

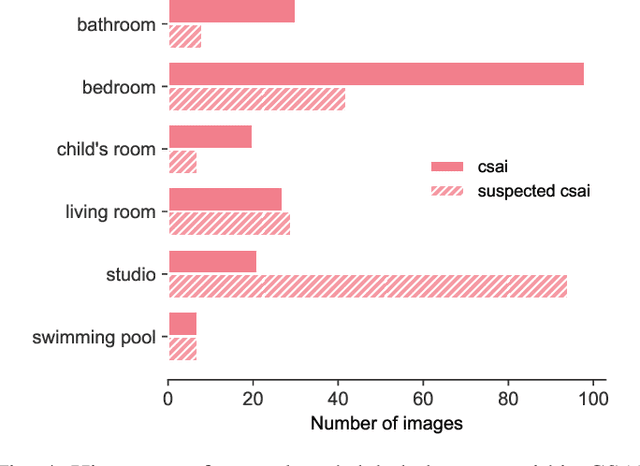
Crime in the 21st century is split into a virtual and real world. However, the former has become a global menace to people's well-being and security in the latter. The challenges it presents must be faced with unified global cooperation, and we must rely more than ever on automated yet trustworthy tools to combat the ever-growing nature of online offenses. Over 10 million child sexual abuse reports are submitted to the US National Center for Missing & Exploited Children every year, and over 80% originated from online sources. Therefore, investigation centers and clearinghouses cannot manually process and correctly investigate all imagery. In light of that, reliable automated tools that can securely and efficiently deal with this data are paramount. In this sense, the scene recognition task looks for contextual cues in the environment, being able to group and classify child sexual abuse data without requiring to be trained on sensitive material. The scarcity and limitations of working with child sexual abuse images lead to self-supervised learning, a machine-learning methodology that leverages unlabeled data to produce powerful representations that can be more easily transferred to target tasks. This work shows that self-supervised deep learning models pre-trained on scene-centric data can reach 71.6% balanced accuracy on our indoor scene classification task and, on average, 2.2 percentage points better performance than a fully supervised version. We cooperate with Brazilian Federal Police experts to evaluate our indoor classification model on actual child abuse material. The results demonstrate a notable discrepancy between the features observed in widely used scene datasets and those depicted on sensitive materials.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
YOLOv7 for Mosquito Breeding Grounds Detection and Tracking
Oct 16, 2023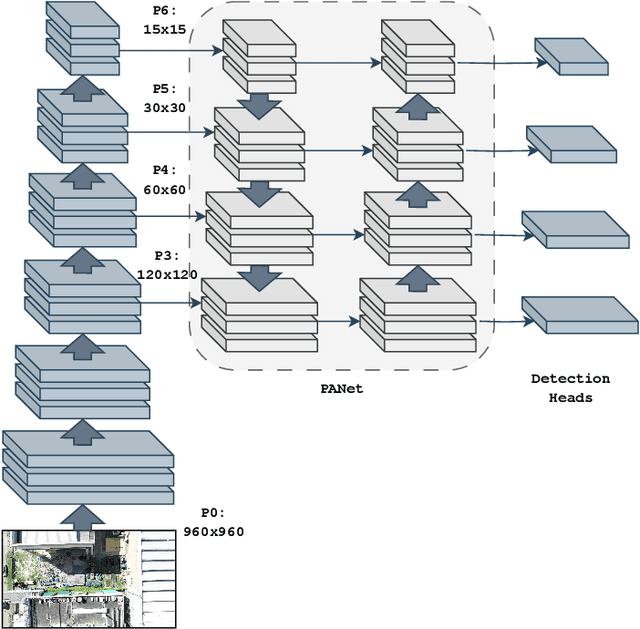
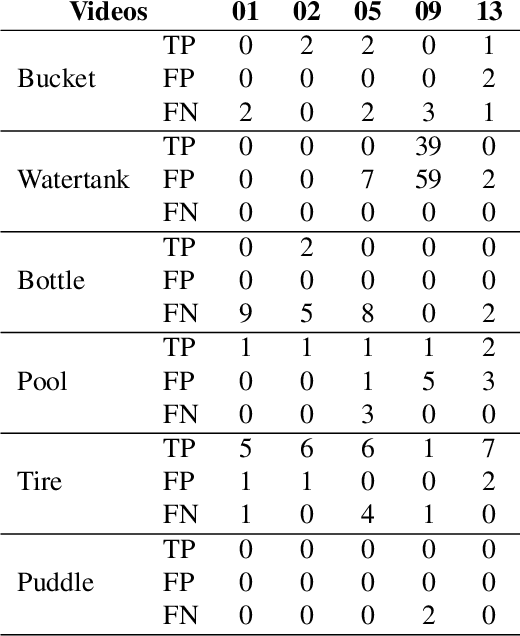


With the looming threat of climate change, neglected tropical diseases such as dengue, zika, and chikungunya have the potential to become an even greater global concern. Remote sensing technologies can aid in controlling the spread of Aedes Aegypti, the transmission vector of such diseases, by automating the detection and mapping of mosquito breeding sites, such that local entities can properly intervene. In this work, we leverage YOLOv7, a state-of-the-art and computationally efficient detection approach, to localize and track mosquito foci in videos captured by unmanned aerial vehicles. We experiment on a dataset released to the public as part of the ICIP 2023 grand challenge entitled Automatic Detection of Mosquito Breeding Grounds. We show that YOLOv7 can be directly applied to detect larger foci categories such as pools, tires, and water tanks and that a cheap and straightforward aggregation of frame-by-frame detection can incorporate time consistency into the tracking process.