 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Punchlines to Predictions: A Metric to Assess LLM Performance in Identifying Humor in Stand-Up Comedy
Apr 12, 2025Comedy serves as a profound reflection of the times we live in and is a staple element of human interactions. In light of the widespread adoption of Large Language Models (LLMs), the intersection of humor and AI has become no laughing matter. Advancements in the naturalness of human-computer interaction correlates with improvements in AI systems' abilities to understand humor. In this study, we assess the ability of models in accurately identifying humorous quotes from a stand-up comedy transcript. Stand-up comedy's unique comedic narratives make it an ideal dataset to improve the overall naturalness of comedic understanding. We propose a novel humor detection metric designed to evaluate LLMs amongst various prompts on their capability to extract humorous punchlines. The metric has a modular structure that offers three different scoring methods - fuzzy string matching, sentence embedding, and subspace similarity - to provide an overarching assessment of a model's performance. The model's results are compared against those of human evaluators on the same task. Our metric reveals that regardless of prompt engineering, leading models, ChatGPT, Claude, and DeepSeek, achieve scores of at most 51% in humor detection. Notably, this performance surpasses that of humans who achieve a score of 41%. The analysis of human evaluators and LLMs reveals variability in agreement, highlighting the subjectivity inherent in humor and the complexities involved in extracting humorous quotes from live performance transcripts. Code available at https://github.com/swaggirl9000/humor.
Frame Representation Hypothesis: Multi-Token LLM Interpretability and Concept-Guided Text Generation
Dec 10, 2024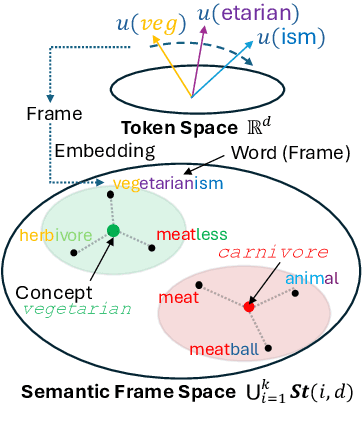

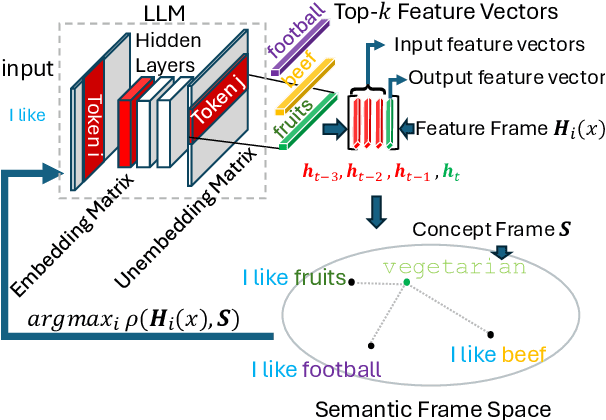
Interpretability is a key challenge in fostering trust for Large Language Models (LLMs), which stems from the complexity of extracting reasoning from model's parameters. We present the Frame Representation Hypothesis, a theoretically robust framework grounded in the Linear Representation Hypothesis (LRH) to interpret and control LLMs by modeling multi-token words. Prior research explored LRH to connect LLM representations with linguistic concepts, but was limited to single token analysis. As most words are composed of several tokens, we extend LRH to multi-token words, thereby enabling usage on any textual data with thousands of concepts. To this end, we propose words can be interpreted as frames, ordered sequences of vectors that better capture token-word relationships. Then, concepts can be represented as the average of word frames sharing a common concept. We showcase these tools through Top-k Concept-Guided Decoding, which can intuitively steer text generation using concepts of choice. We verify said ideas on Llama 3.1, Gemma 2, and Phi 3 families, demonstrating gender and language biases, exposing harmful content, but also potential to remediate them, leading to safer and more transparent LLMs. Code is available at https://github.com/phvv-me/frame-representation-hypothesis.git
Second-order difference subspace
Sep 13, 2024Subspace representation is a fundamental technique in various fields of machine learning. Analyzing a geometrical relationship among multiple subspaces is essential for understanding subspace series' temporal and/or spatial dynamics. This paper proposes the second-order difference subspace, a higher-order extension of the first-order difference subspace between two subspaces that can analyze the geometrical difference between them. As a preliminary for that, we extend the definition of the first-order difference subspace to the more general setting that two subspaces with different dimensions have an intersection. We then define the second-order difference subspace by combining the concept of first-order difference subspace and principal component subspace (Karcher mean) between two subspaces, motivated by the second-order central difference method. We can understand that the first/second-order difference subspaces correspond to the velocity and acceleration of subspace dynamics from the viewpoint of a geodesic on a Grassmann manifold. We demonstrate the validity and naturalness of our second-order difference subspace by showing numerical results on two applications: temporal shape analysis of a 3D object and time series analysis of a biometric signal.
Leveraging Self-Supervised Learning for Scene Recognition in Child Sexual Abuse Imagery
Mar 02, 2024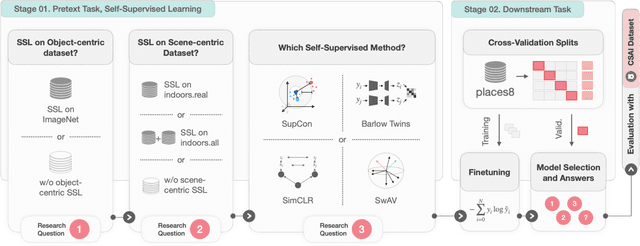
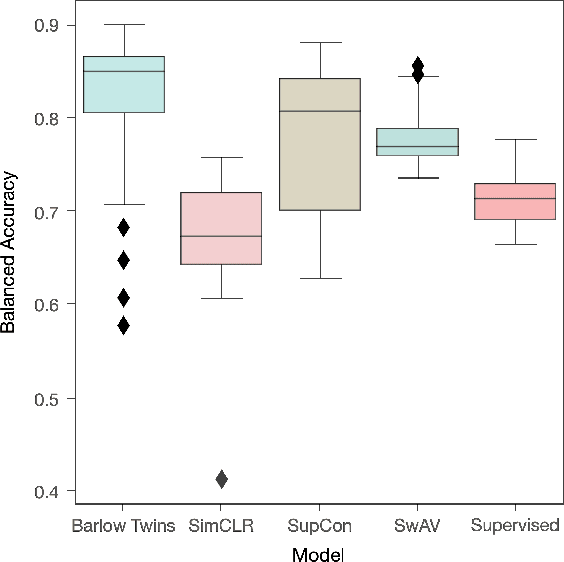

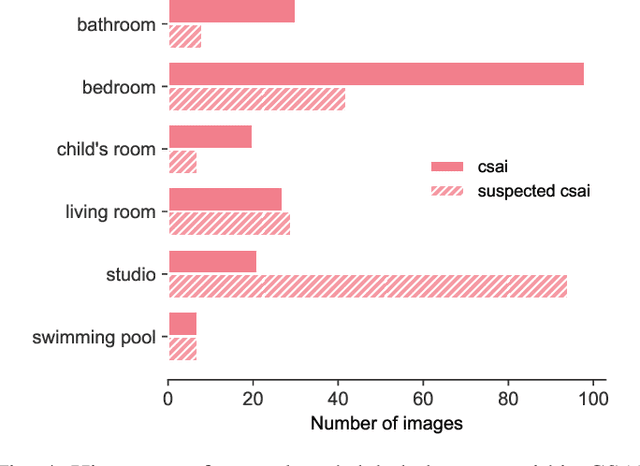
Crime in the 21st century is split into a virtual and real world. However, the former has become a global menace to people's well-being and security in the latter. The challenges it presents must be faced with unified global cooperation, and we must rely more than ever on automated yet trustworthy tools to combat the ever-growing nature of online offenses. Over 10 million child sexual abuse reports are submitted to the US National Center for Missing & Exploited Children every year, and over 80% originated from online sources. Therefore, investigation centers and clearinghouses cannot manually process and correctly investigate all imagery. In light of that, reliable automated tools that can securely and efficiently deal with this data are paramount. In this sense, the scene recognition task looks for contextual cues in the environment, being able to group and classify child sexual abuse data without requiring to be trained on sensitive material. The scarcity and limitations of working with child sexual abuse images lead to self-supervised learning, a machine-learning methodology that leverages unlabeled data to produce powerful representations that can be more easily transferred to target tasks. This work shows that self-supervised deep learning models pre-trained on scene-centric data can reach 71.6% balanced accuracy on our indoor scene classification task and, on average, 2.2 percentage points better performance than a fully supervised version. We cooperate with Brazilian Federal Police experts to evaluate our indoor classification model on actual child abuse material. The results demonstrate a notable discrepancy between the features observed in widely used scene datasets and those depicted on sensitive materials.