 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame Representation Hypothesis: Multi-Token LLM Interpretability and Concept-Guided Text Generation
Dec 10, 2024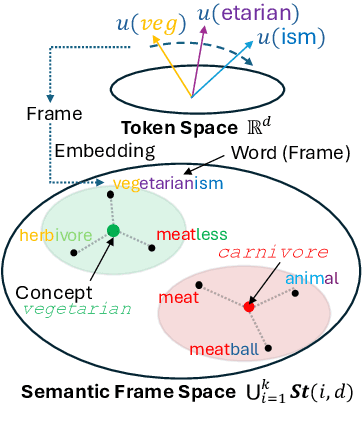

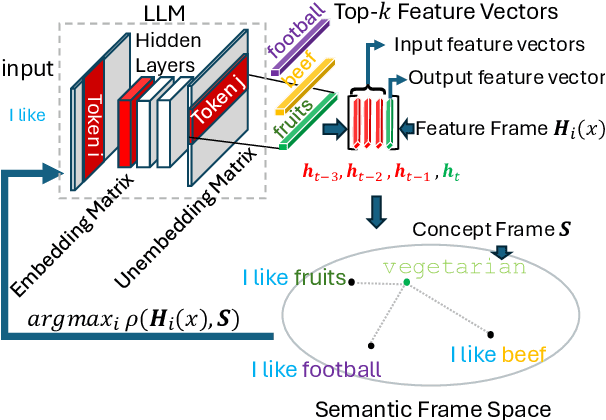
Interpretability is a key challenge in fostering trust for Large Language Models (LLMs), which stems from the complexity of extracting reasoning from model's parameters. We present the Frame Representation Hypothesis, a theoretically robust framework grounded in the Linear Representation Hypothesis (LRH) to interpret and control LLMs by modeling multi-token words. Prior research explored LRH to connect LLM representations with linguistic concepts, but was limited to single token analysis. As most words are composed of several tokens, we extend LRH to multi-token words, thereby enabling usage on any textual data with thousands of concepts. To this end, we propose words can be interpreted as frames, ordered sequences of vectors that better capture token-word relationships. Then, concepts can be represented as the average of word frames sharing a common concept. We showcase these tools through Top-k Concept-Guided Decoding, which can intuitively steer text generation using concepts of choice. We verify said ideas on Llama 3.1, Gemma 2, and Phi 3 families, demonstrating gender and language biases, exposing harmful content, but also potential to remediate them, leading to safer and more transparent LLMs. Code is available at https://github.com/phvv-me/frame-representation-hypothesis.git
Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Sep 26, 2022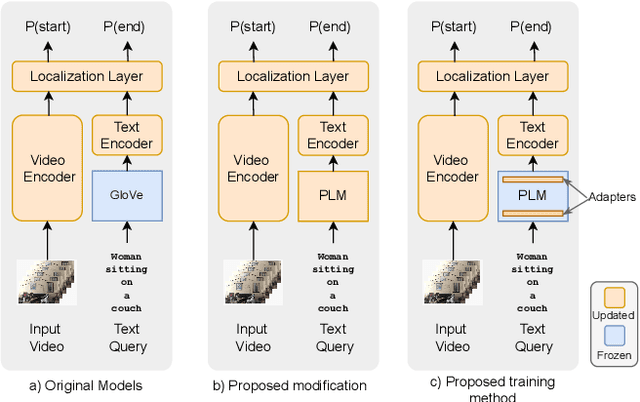
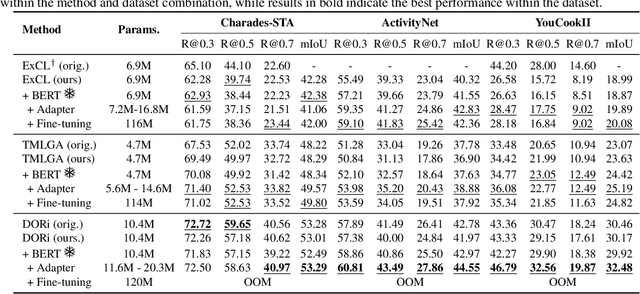
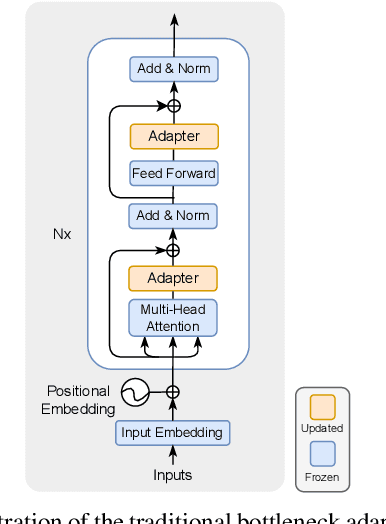
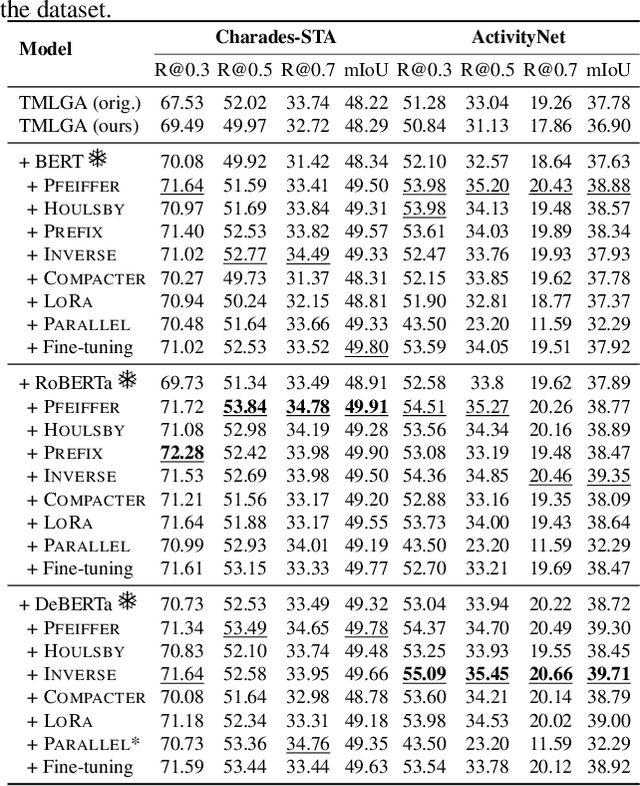
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.
Text Classification based on Word Subspace with Term-Frequency
Jun 08, 2018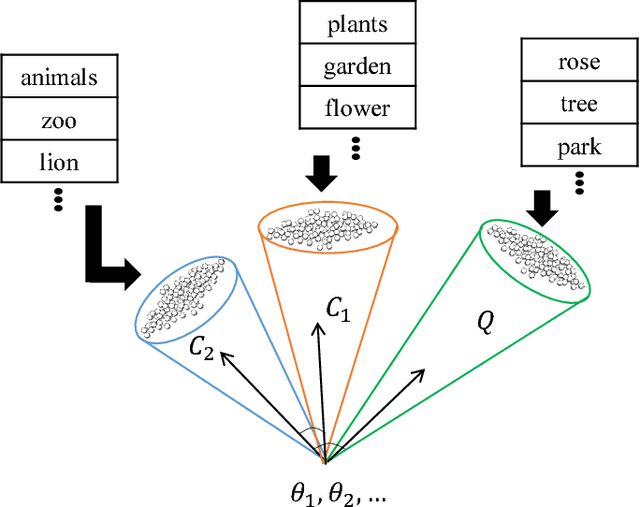
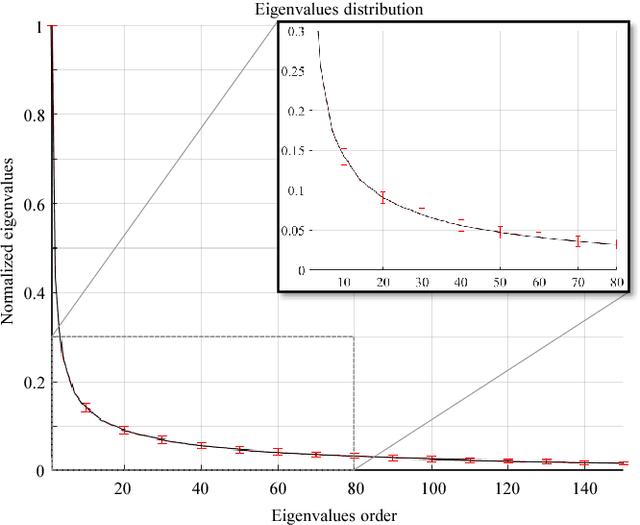

Text classification has become indispensable due to the rapid increase of text in digital form. Over the past three decades, efforts have been made to approach this task using various learning algorithms and statistical models based on bag-of-words (BOW) features. Despite its simple implementation, BOW features lack semantic meaning representation. To solve this problem, neural networks started to be employed to learn word vectors, such as the word2vec. Word2vec embeds word semantic structure into vectors, where the angle between vectors indicates the meaningful similarity between words. To measure the similarity between texts, we propose the novel concept of word subspace, which can represent the intrinsic variability of features in a set of word vectors. Through this concept, it is possible to model text from word vectors while holding semantic information. To incorporate the word frequency directly in the subspace model, we further extend the word subspace to the term-frequency (TF) weighted word subspace. Based on these new concepts, text classification can be performed under the mutual subspace method (MSM) framework. The validity of our modeling is shown through experiments on the Reuters text database, comparing the results to various state-of-art algorithms.