 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification based on Word Subspace with Term-Frequency
Paper and Code
Jun 08, 2018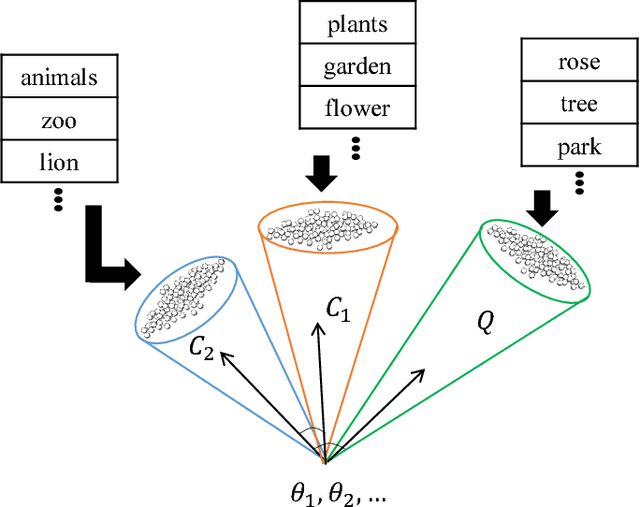

Text classification has become indispensable due to the rapid increase of text in digital form. Over the past three decades, efforts have been made to approach this task using various learning algorithms and statistical models based on bag-of-words (BOW) features. Despite its simple implementation, BOW features lack semantic meaning representation. To solve this problem, neural networks started to be employed to learn word vectors, such as the word2vec. Word2vec embeds word semantic structure into vectors, where the angle between vectors indicates the meaningful similarity between words. To measure the similarity between texts, we propose the novel concept of word subspace, which can represent the intrinsic variability of features in a set of word vectors. Through this concept, it is possible to model text from word vectors while holding semantic information. To incorporate the word frequency directly in the subspace model, we further extend the word subspace to the term-frequency (TF) weighted word subspace. Based on these new concepts, text classification can be performed under the mutual subspace method (MSM) framework. The validity of our modeling is shown through experiments on the Reuters text database, comparing the results to various state-of-art algorithms.