 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrassmannian learning mutual subspace method for image set recognition
Nov 08, 2021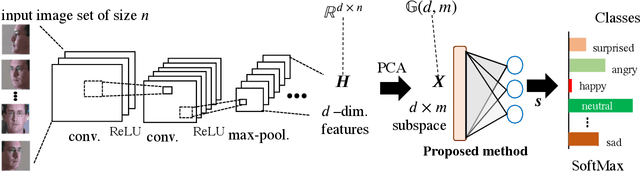
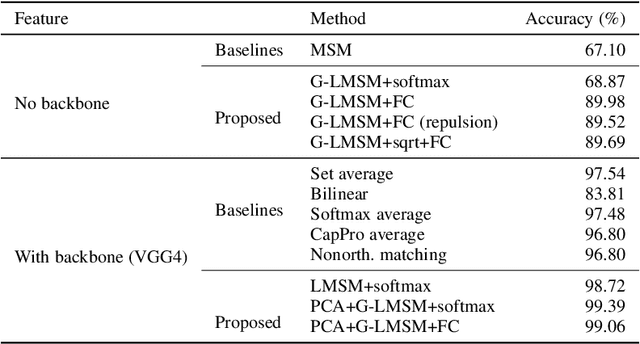
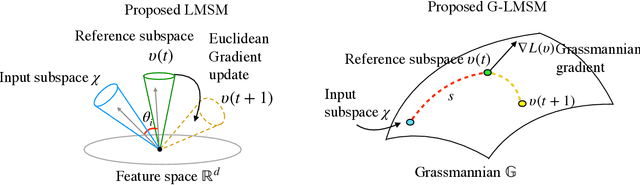
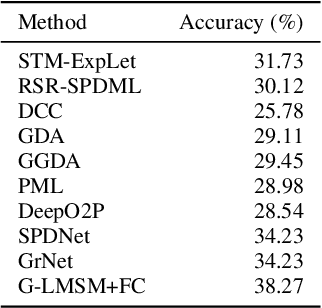
This paper addresses the problem of object recognition given a set of images as input (e.g., multiple camera sources and video frames). Convolutional neural network (CNN)-based frameworks do not exploit these sets effectively, processing a pattern as observed, not capturing the underlying feature distribution as it does not consider the variance of images in the set. To address this issue, we propose the Grassmannian learning mutual subspace method (G-LMSM), a NN layer embedded on top of CNNs as a classifier, that can process image sets more effectively and can be trained in an end-to-end manner. The image set is represented by a low-dimensional input subspace; and this input subspace is matched with reference subspaces by a similarity of their canonical angles, an interpretable and easy to compute metric. The key idea of G-LMSM is that the reference subspaces are learned as points on the Grassmann manifold, optimized with Riemannian stochastic gradient descent. This learning is stable, efficient and theoretically well-grounded. We demonstrate the effectiveness of our proposed method on hand shape recognition, face identification, and facial emotion recognition.
Discriminative Singular Spectrum Classifier with Applications on Bioacoustic Signal Recognition
Mar 18, 2021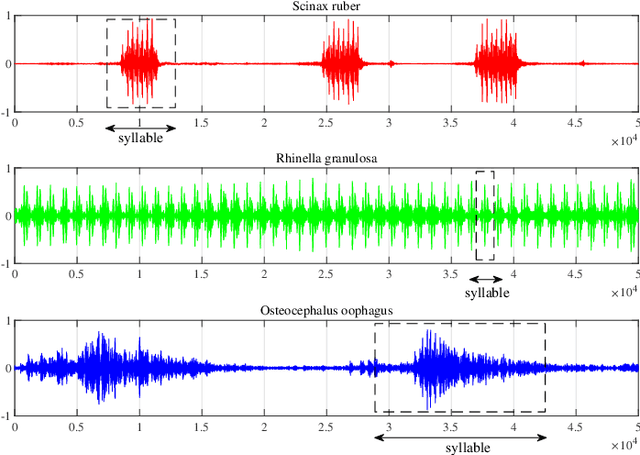
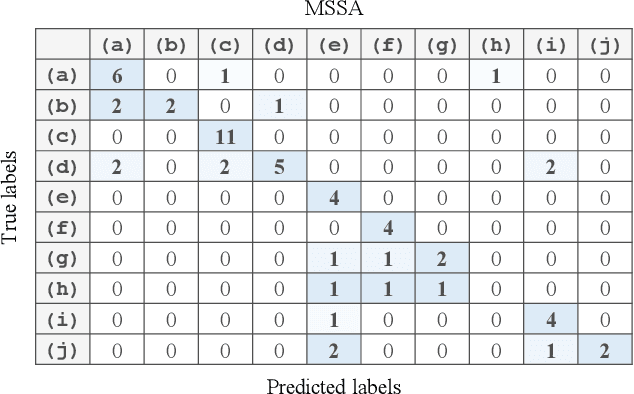
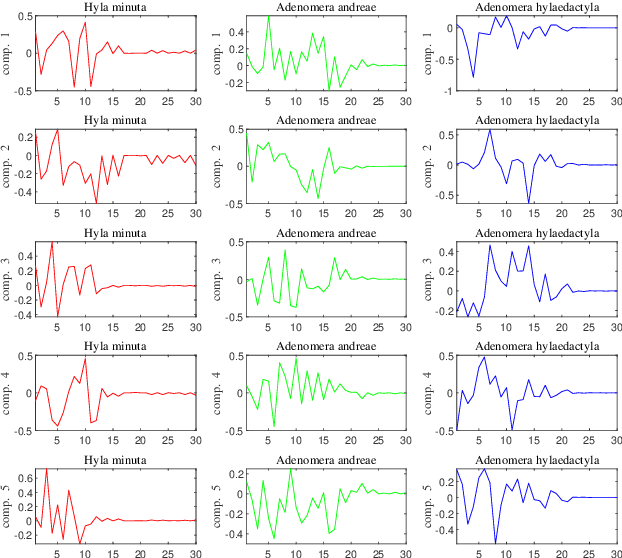
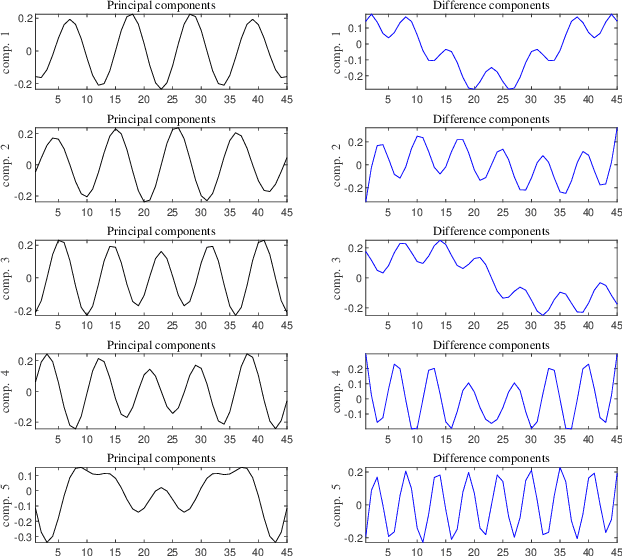
Automatic analysis of bioacoustic signals is a fundamental tool to evaluate the vitality of our planet. Frogs and bees, for instance, may act like biological sensors providing information about environmental changes. This task is fundamental for ecological monitoring still includes many challenges such as nonuniform signal length processing, degraded target signal due to environmental noise, and the scarcity of the labeled samples for training machine learning. To tackle these challenges, we present a bioacoustic signal classifier equipped with a discriminative mechanism to extract useful features for analysis and classification efficiently. The proposed classifier does not require a large amount of training data and handles nonuniform signal length natively. Unlike current bioacoustic recognition methods, which are task-oriented, the proposed model relies on transforming the input signals into vector subspaces generated by applying Singular Spectrum Analysis (SSA). Then, a subspace is designed to expose discriminative features. The proposed model shares end-to-end capabilities, which is desirable in modern machine learning systems. This formulation provides a segmentation-free and noise-tolerant approach to represent and classify bioacoustic signals and a highly compact signal descriptor inherited from SSA. The validity of the proposed method is verified using three challenging bioacoustic datasets containing anuran, bee, and mosquito species. Experimental results on three bioacoustic datasets have shown the competitive performance of the proposed method compared to commonly employed methods for bioacoustics signal classification in terms of accuracy.
Tensor Analysis with n-Mode Generalized Difference Subspace
Sep 04, 2019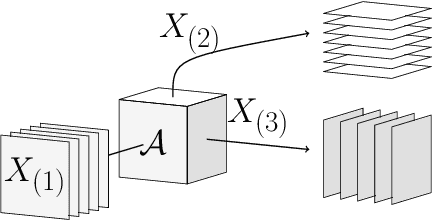


The increasing use of multiple sensors requires more efficient methods to represent and classify multi-dimensional data, since these applications produce a large amount of data, demanding modern techniques for data processing. Considering these observations, we present in this paper a new method for multi-dimensional data classification which relies on two premises: 1) multi-dimensional data are usually represented by tensors, due to benefits from multilinear algebra and the established tensor factorization methods; and 2) this kind of data can be described by a subspace lying within a vector space. Subspace representation has been consistently employed for pattern-set recognition, and its tensor representation counterpart is also available in the literature. However, traditional methods do not employ discriminative information of the tensors, which degrades the classification accuracy. In this scenario, generalized difference subspace (GDS) may provide an enhanced subspace representation by reducing data redundancy and revealing discriminative structures. Since GDS is not able to directly handle tensor data, we propose a new projection called n-mode GDS, which efficiently handles tensor data. In addition, n-mode Fisher score is introduced as a class separability index and an improved metric based on the geodesic distance is provided to measure the similarity between tensor data. To confirm the advantages of the proposed method, we address the problem of representing and classifying tensor data for gesture and action recognition. The experimental results have shown that the proposed approach outperforms methods commonly used in the literature without adopting pre-trained models or transfer learning.
Text Classification based on Word Subspace with Term-Frequency
Jun 08, 2018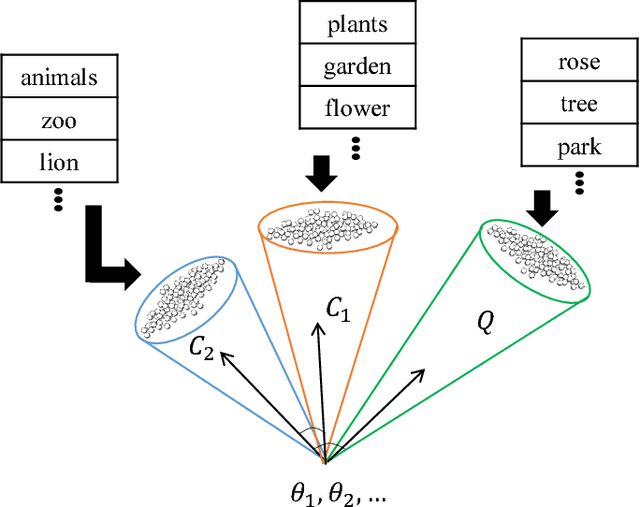

Text classification has become indispensable due to the rapid increase of text in digital form. Over the past three decades, efforts have been made to approach this task using various learning algorithms and statistical models based on bag-of-words (BOW) features. Despite its simple implementation, BOW features lack semantic meaning representation. To solve this problem, neural networks started to be employed to learn word vectors, such as the word2vec. Word2vec embeds word semantic structure into vectors, where the angle between vectors indicates the meaningful similarity between words. To measure the similarity between texts, we propose the novel concept of word subspace, which can represent the intrinsic variability of features in a set of word vectors. Through this concept, it is possible to model text from word vectors while holding semantic information. To incorporate the word frequency directly in the subspace model, we further extend the word subspace to the term-frequency (TF) weighted word subspace. Based on these new concepts, text classification can be performed under the mutual subspace method (MSM) framework. The validity of our modeling is shown through experiments on the Reuters text database, comparing the results to various state-of-art algorithms.