 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Mining Embeddings: Learning Vector Representations for Petri Nets
Apr 26, 2024

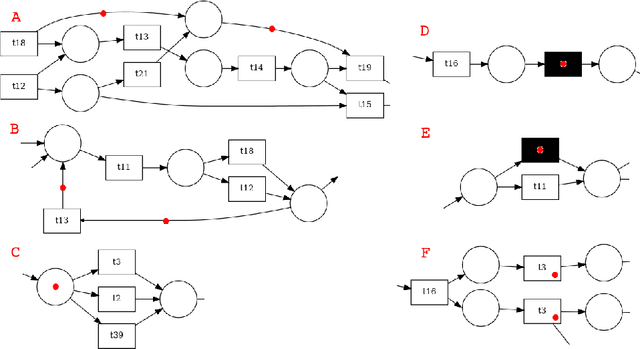

Process mining offers powerful techniques for discovering, analyzing, and enhancing real-world business processes. In this context, Petri nets provide an expressive means of modeling process behavior. However, directly analyzing and comparing intricate Petri net presents challenges. This study introduces PetriNet2Vec, a novel unsupervised methodology based on Natural Language Processing concepts inspired by Doc2Vec and designed to facilitate the effective comparison, clustering, and classification of process models represented as embedding vectors. These embedding vectors allow us to quantify similarities and relationships between different process models. Our methodology was experimentally validated using the PDC Dataset, featuring 96 diverse Petri net models. We performed cluster analysis, created UMAP visualizations, and trained a decision tree to provide compelling evidence for the capability of PetriNet2Vec to discern meaningful patterns and relationships among process models and their constituent tasks. Through a series of experiments, we demonstrated that PetriNet2Vec was capable of learning the structure of Petri nets, as well as the main properties used to simulate the process models of our dataset. Furthermore, our results showcase the utility of the learned embeddings in two crucial downstream tasks within process mining enhancement: process classification and process retrieval.
Tasks People Prompt: A Taxonomy of LLM Downstream Tasks in Software Verification and Falsification Approaches
Apr 14, 2024Prompting has become one of the main approaches to leverage emergent capabilities of Large Language Models [Brown et al. NeurIPS 2020, Wei et al. TMLR 2022, Wei et al. NeurIPS 2022]. During the last year, researchers and practitioners have been playing with prompts to see how to make the most of LLMs. By homogeneously dissecting 80 papers, we investigate in deep how software testing and verification research communities have been abstractly architecting their LLM-enabled solutions. More precisely, first, we want to validate whether downstream tasks are an adequate concept to convey the blueprint of prompt-based solutions. We also aim at identifying number and nature of such tasks in solutions. For such goal, we develop a novel downstream task taxonomy that enables pinpointing some engineering patterns in a rather varied spectrum of Software Engineering problems that encompasses testing, fuzzing, debugging, vulnerability detection, static analysis and program verification approaches.
Catastrophic Forgetting in Deep Learning: A Comprehensive Taxonomy
Dec 16, 2023


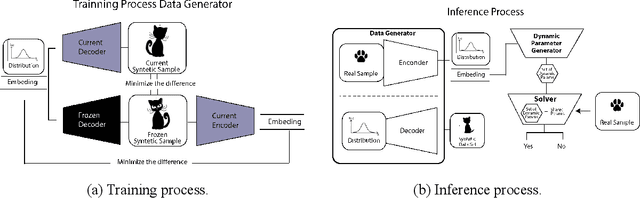
Deep Learning models have achieved remarkable performance in tasks such as image classification or generation, often surpassing human accuracy. However, they can struggle to learn new tasks and update their knowledge without access to previous data, leading to a significant loss of accuracy known as Catastrophic Forgetting (CF). This phenomenon was first observed by McCloskey and Cohen in 1989 and remains an active research topic. Incremental learning without forgetting is widely recognized as a crucial aspect in building better AI systems, as it allows models to adapt to new tasks without losing the ability to perform previously learned ones. This article surveys recent studies that tackle CF in modern Deep Learning models that use gradient descent as their learning algorithm. Although several solutions have been proposed, a definitive solution or consensus on assessing CF is yet to be established. The article provides a comprehensive review of recent solutions, proposes a taxonomy to organize them, and identifies research gaps in this area.
Bag of Tricks for Long-Tail Visual Recognition of Animal Species in Camera Trap Images
Jun 24, 2022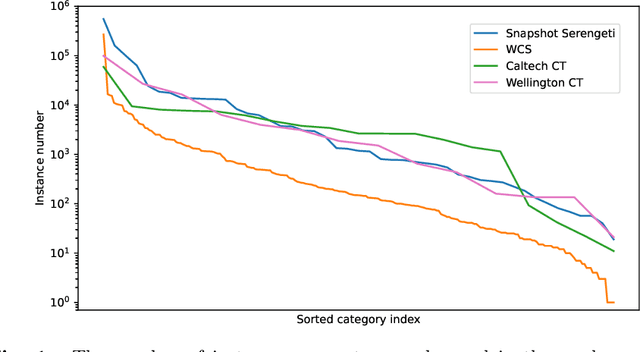
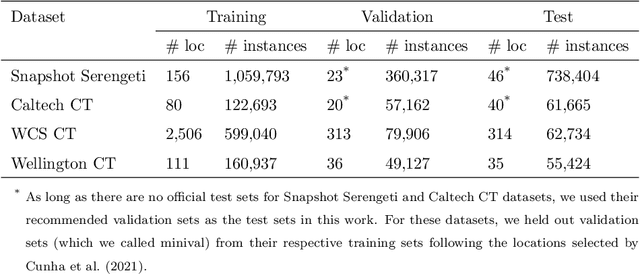


Camera traps are a strategy for monitoring wildlife that collects a large number of pictures. The number of images collected from each species usually follows a long-tail distribution, i.e., a few classes have a large number of instances while a lot of species have just a small percentage. Although in most cases these rare species are the classes of interest to ecologists, they are often neglected when using deep learning models because these models require a large number of images for the training. In this work, we systematically evaluate recently proposed techniques - namely, square-root re-sampling, class-balanced focal loss, and balanced group softmax - to address the long-tail visual recognition of animal species in camera trap images. To achieve a more general conclusion, we evaluated the selected methods on four families of computer vision models (ResNet, MobileNetV3, EfficientNetV2, and Swin Transformer) and four camera trap datasets with different characteristics. Initially, we prepared a robust baseline with the most recent training tricks and then we applied the methods for improving long-tail recognition. Our experiments show that the Swin transformer can reach high performance for rare classes without applying any additional method for handling imbalance, with an overall accuracy of 88.76% for WCS dataset and 94.97% for Snapshot Serengeti, considering a location-based train/test split. In general, the square-root sampling was the method that most improved the performance for minority classes by around 10%, but at the cost of reducing the majority classes accuracy at least 4%. These results motivated us to propose a simple and effective approach using an ensemble combining square-root sampling and the baseline. The proposed approach achieved the best trade-off between the performance of the tail class and the cost of the head classes' accuracy.
Filtering Empty Camera Trap Images in Embedded Systems
Apr 18, 2021
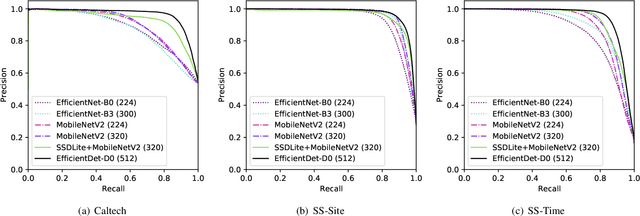


Monitoring wildlife through camera traps produces a massive amount of images, whose a significant portion does not contain animals, being later discarded. Embedding deep learning models to identify animals and filter these images directly in those devices brings advantages such as savings in the storage and transmission of data, usually resource-constrained in this type of equipment. In this work, we present a comparative study on animal recognition models to analyze the trade-off between precision and inference latency on edge devices. To accomplish this objective, we investigate classifiers and object detectors of various input resolutions and optimize them using quantization and reducing the number of model filters. The confidence threshold of each model was adjusted to obtain 96% recall for the nonempty class, since instances from the empty class are expected to be discarded. The experiments show that, when using the same set of images for training, detectors achieve superior performance, eliminating at least 10% more empty images than classifiers with comparable latencies. Considering the high cost of generating labels for the detection problem, when there is a massive number of images labeled for classification (about one million instances, ten times more than those available for detection), classifiers are able to reach results comparable to detectors but with half latency.
Discriminative Singular Spectrum Classifier with Applications on Bioacoustic Signal Recognition
Mar 18, 2021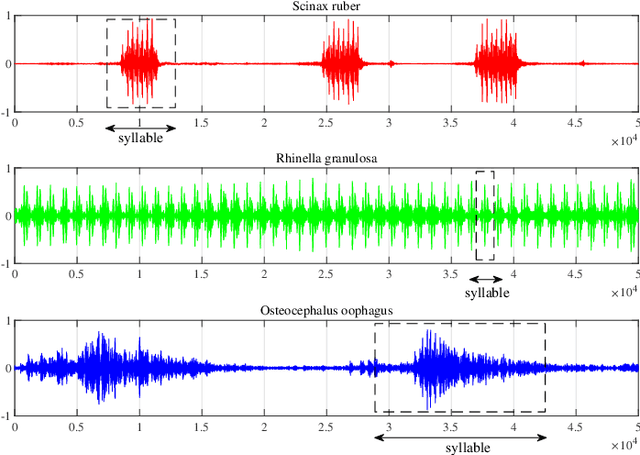
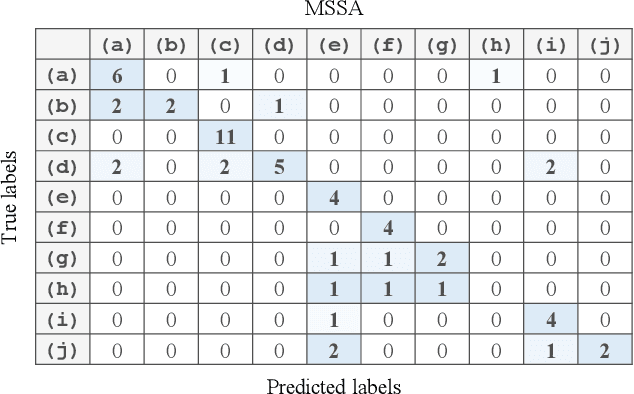
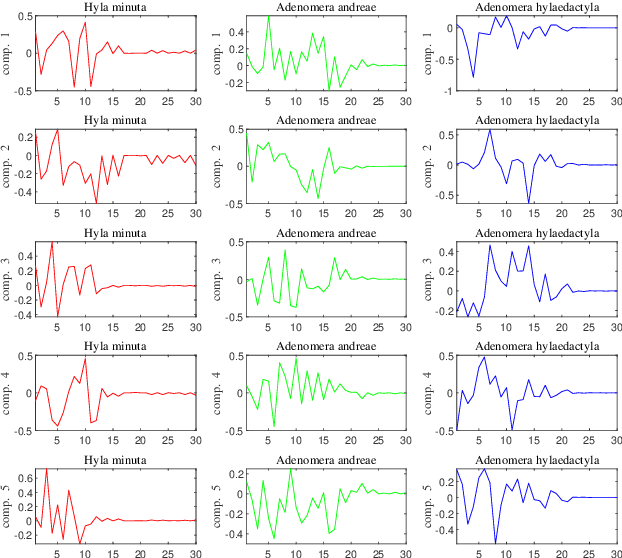
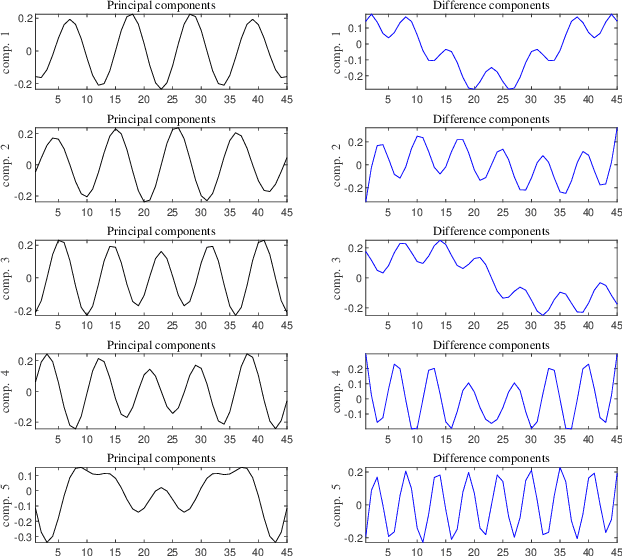
Automatic analysis of bioacoustic signals is a fundamental tool to evaluate the vitality of our planet. Frogs and bees, for instance, may act like biological sensors providing information about environmental changes. This task is fundamental for ecological monitoring still includes many challenges such as nonuniform signal length processing, degraded target signal due to environmental noise, and the scarcity of the labeled samples for training machine learning. To tackle these challenges, we present a bioacoustic signal classifier equipped with a discriminative mechanism to extract useful features for analysis and classification efficiently. The proposed classifier does not require a large amount of training data and handles nonuniform signal length natively. Unlike current bioacoustic recognition methods, which are task-oriented, the proposed model relies on transforming the input signals into vector subspaces generated by applying Singular Spectrum Analysis (SSA). Then, a subspace is designed to expose discriminative features. The proposed model shares end-to-end capabilities, which is desirable in modern machine learning systems. This formulation provides a segmentation-free and noise-tolerant approach to represent and classify bioacoustic signals and a highly compact signal descriptor inherited from SSA. The validity of the proposed method is verified using three challenging bioacoustic datasets containing anuran, bee, and mosquito species. Experimental results on three bioacoustic datasets have shown the competitive performance of the proposed method compared to commonly employed methods for bioacoustics signal classification in terms of accuracy.