 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Repair of AI Code with Large Language Models and Formal Verification
May 14, 2024

The next generation of AI systems requires strong safety guarantees. This report looks at the software implementation of neural networks and related memory safety properties, including NULL pointer deference, out-of-bound access, double-free, and memory leaks. Our goal is to detect these vulnerabilities, and automatically repair them with the help of large language models. To this end, we first expand the size of NeuroCodeBench, an existing dataset of neural network code, to about 81k programs via an automated process of program mutation. Then, we verify the memory safety of the mutated neural network implementations with ESBMC, a state-of-the-art software verifier. Whenever ESBMC spots a vulnerability, we invoke a large language model to repair the source code. For the latest task, we compare the performance of various state-of-the-art prompt engineering techniques, and an iterative approach that repeatedly calls the large language model.
Tasks People Prompt: A Taxonomy of LLM Downstream Tasks in Software Verification and Falsification Approaches
Apr 14, 2024Prompting has become one of the main approaches to leverage emergent capabilities of Large Language Models [Brown et al. NeurIPS 2020, Wei et al. TMLR 2022, Wei et al. NeurIPS 2022]. During the last year, researchers and practitioners have been playing with prompts to see how to make the most of LLMs. By homogeneously dissecting 80 papers, we investigate in deep how software testing and verification research communities have been abstractly architecting their LLM-enabled solutions. More precisely, first, we want to validate whether downstream tasks are an adequate concept to convey the blueprint of prompt-based solutions. We also aim at identifying number and nature of such tasks in solutions. For such goal, we develop a novel downstream task taxonomy that enables pinpointing some engineering patterns in a rather varied spectrum of Software Engineering problems that encompasses testing, fuzzing, debugging, vulnerability detection, static analysis and program verification approaches.
A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification
May 24, 2023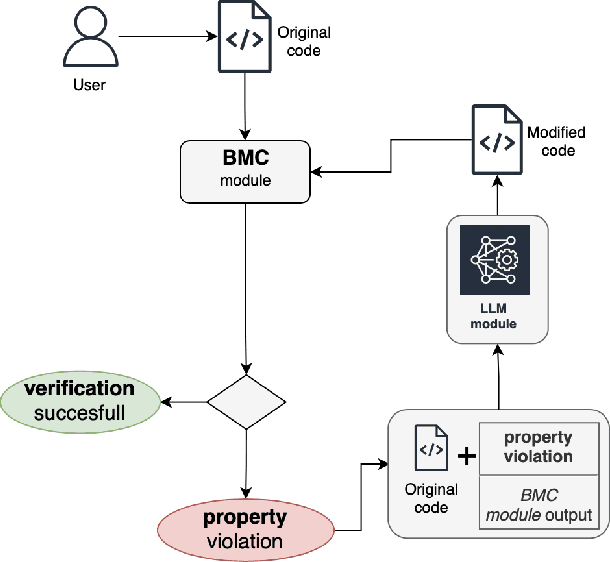

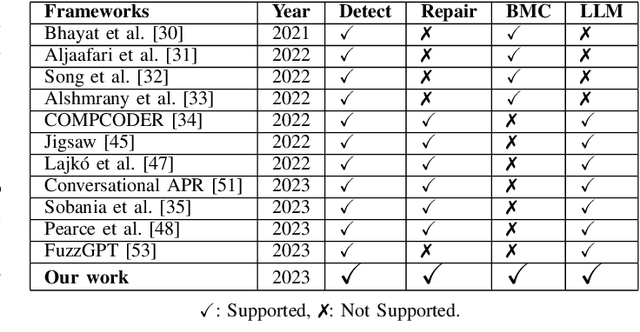

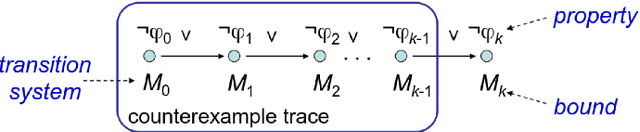
In this paper we present a novel solution that combines the capabilities of Large Language Models (LLMs) with Formal Verification strategies to verify and automatically repair software vulnerabilities. Initially, we employ Bounded Model Checking (BMC) to locate the software vulnerability and derive a counterexample. The counterexample provides evidence that the system behaves incorrectly or contains a vulnerability. The counterexample that has been detected, along with the source code, are provided to the LLM engine. Our approach involves establishing a specialized prompt language for conducting code debugging and generation to understand the vulnerability's root cause and repair the code. Finally, we use BMC to verify the corrected version of the code generated by the LLM. As a proof of concept, we create ESBMC-AI based on the Efficient SMT-based Context-Bounded Model Checker (ESBMC) and a pre-trained Transformer model, specifically gpt-3.5-turbo, to detect and fix errors in C programs. Our experimentation involved generating a dataset comprising 1000 C code samples, each consisting of 20 to 50 lines of code. Notably, our proposed method achieved an impressive success rate of up to 80% in repairing vulnerable code encompassing buffer overflow and pointer dereference failures. We assert that this automated approach can effectively incorporate into the software development lifecycle's continuous integration and deployment (CI/CD) process.