 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6G-Bench: An Open Benchmark for Semantic Communication and Network-Level Reasoning with Foundation Models in AI-Native 6G Networks
Feb 09, 2026This paper introduces 6G-Bench, an open benchmark for evaluating semantic communication and network-level reasoning in AI-native 6G networks. 6G-Bench defines a taxonomy of 30 decision-making tasks (T1--T30) extracted from ongoing 6G and AI-agent standardization activities in 3GPP, IETF, ETSI, ITU-T, and the O-RAN Alliance, and organizes them into five standardization-aligned capability categories. Starting from 113,475 scenarios, we generate a balanced pool of 10,000 very-hard multiple-choice questions using task-conditioned prompts that enforce multi-step quantitative reasoning under uncertainty and worst-case regret minimization over multi-turn horizons. After automated filtering and expert human validation, 3,722 questions are retained as a high-confidence evaluation set, while the full pool is released to support training and fine-tuning of 6G-specialized models. Using 6G-Bench, we evaluate 22 foundation models spanning dense and mixture-of-experts architectures, short- and long-context designs (up to 1M tokens), and both open-weight and proprietary systems. Across models, deterministic single-shot accuracy (pass@1) spans a wide range from 0.22 to 0.82, highlighting substantial variation in semantic reasoning capability. Leading models achieve intent and policy reasoning accuracy in the range 0.87--0.89, while selective robustness analysis on reasoning-intensive tasks shows pass@5 values ranging from 0.20 to 0.91. To support open science and reproducibility, we release the 6G-Bench dataset on GitHub: https://github.com/maferrag/6G-Bench
$α^3$-SecBench: A Large-Scale Evaluation Suite of Security, Resilience, and Trust for LLM-based UAV Agents over 6G Networks
Jan 26, 2026Autonomous unmanned aerial vehicle (UAV) systems are increasingly deployed in safety-critical, networked environments where they must operate reliably in the presence of malicious adversaries. While recent benchmarks have evaluated large language model (LLM)-based UAV agents in reasoning, navigation, and efficiency, systematic assessment of security, resilience, and trust under adversarial conditions remains largely unexplored, particularly in emerging 6G-enabled settings. We introduce $α^{3}$-SecBench, the first large-scale evaluation suite for assessing the security-aware autonomy of LLM-based UAV agents under realistic adversarial interference. Building on multi-turn conversational UAV missions from $α^{3}$-Bench, the framework augments benign episodes with 20,000 validated security overlay attack scenarios targeting seven autonomy layers, including sensing, perception, planning, control, communication, edge/cloud infrastructure, and LLM reasoning. $α^{3}$-SecBench evaluates agents across three orthogonal dimensions: security (attack detection and vulnerability attribution), resilience (safe degradation behavior), and trust (policy-compliant tool usage). We evaluate 23 state-of-the-art LLMs from major industrial providers and leading AI labs using thousands of adversarially augmented UAV episodes sampled from a corpus of 113,475 missions spanning 175 threat types. While many models reliably detect anomalous behavior, effective mitigation, vulnerability attribution, and trustworthy control actions remain inconsistent. Normalized overall scores range from 12.9% to 57.1%, highlighting a significant gap between anomaly detection and security-aware autonomous decision-making. We release $α^{3}$-SecBench on GitHub: https://github.com/maferrag/AlphaSecBench
AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems
Jan 23, 2026The rapid advancement of large language models (LLMs) has sparked growing interest in their integration into autonomous systems for reasoning-driven perception, planning, and decision-making. However, evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks. This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for training, fine-tuning, and evaluating autonomous agents under diverse conditions. AgentDrive formalizes a factorized scenario space across seven orthogonal axes: scenario type, driver behavior, environment, road layout, objective, difficulty, and traffic density. An LLM-driven prompt-to-JSON pipeline generates semantically rich, simulation-ready specifications that are validated against physical and schema constraints. Each scenario undergoes simulation rollouts, surrogate safety metric computation, and rule-based outcome labeling. To complement simulation-based evaluation, we introduce AgentDrive-MCQ, a 100,000-question multiple-choice benchmark spanning five reasoning dimensions: physics, policy, hybrid, scenario, and comparative reasoning. We conduct a large-scale evaluation of fifty leading LLMs on AgentDrive-MCQ. Results show that while proprietary frontier models perform best in contextual and policy reasoning, advanced open models are rapidly closing the gap in structured and physics-grounded reasoning. We release the AgentDrive dataset, AgentDrive-MCQ benchmark, evaluation code, and related materials at https://github.com/maferrag/AgentDrive
$α^3$-Bench: A Unified Benchmark of Safety, Robustness, and Efficiency for LLM-Based UAV Agents over 6G Networks
Jan 01, 2026Large Language Models (LLMs) are increasingly used as high level controllers for autonomous Unmanned Aerial Vehicle (UAV) missions. However, existing evaluations rarely assess whether such agents remain safe, protocol compliant, and effective under realistic next generation networking constraints. This paper introduces $α^3$-Bench, a benchmark for evaluating LLM driven UAV autonomy as a multi turn conversational reasoning and control problem operating under dynamic 6G conditions. Each mission is formulated as a language mediated control loop between an LLM based UAV agent and a human operator, where decisions must satisfy strict schema validity, mission policies, speaker alternation, and safety constraints while adapting to fluctuating network slices, latency, jitter, packet loss, throughput, and edge load variations. To reflect modern agentic workflows, $α^3$-Bench integrates a dual action layer supporting both tool calls and agent to agent coordination, enabling evaluation of tool use consistency and multi agent interactions. We construct a large scale corpus of 113k conversational UAV episodes grounded in UAVBench scenarios and evaluate 17 state of the art LLMs using a fixed subset of 50 episodes per scenario under deterministic decoding. We propose a composite $α^3$ metric that unifies six pillars: Task Outcome, Safety Policy, Tool Consistency, Interaction Quality, Network Robustness, and Communication Cost, with efficiency normalized scores per second and per thousand tokens. Results show that while several models achieve high mission success and safety compliance, robustness and efficiency vary significantly under degraded 6G conditions, highlighting the need for network aware and resource efficient LLM based UAV agents. The dataset is publicly available on GitHub : https://github.com/maferrag/AlphaBench
UAVBench: An Open Benchmark Dataset for Autonomous and Agentic AI UAV Systems via LLM-Generated Flight Scenarios
Nov 14, 2025



Autonomous aerial systems increasingly rely on large language models (LLMs) for mission planning, perception, and decision-making, yet the lack of standardized and physically grounded benchmarks limits systematic evaluation of their reasoning capabilities. To address this gap, we introduce UAVBench, an open benchmark dataset comprising 50,000 validated UAV flight scenarios generated through taxonomy-guided LLM prompting and multi-stage safety validation. Each scenario is encoded in a structured JSON schema that includes mission objectives, vehicle configuration, environmental conditions, and quantitative risk labels, providing a unified representation of UAV operations across diverse domains. Building on this foundation, we present UAVBench_MCQ, a reasoning-oriented extension containing 50,000 multiple-choice questions spanning ten cognitive and ethical reasoning styles, ranging from aerodynamics and navigation to multi-agent coordination and integrated reasoning. This framework enables interpretable and machine-checkable assessment of UAV-specific cognition under realistic operational contexts. We evaluate 32 state-of-the-art LLMs, including GPT-5, ChatGPT-4o, Gemini 2.5 Flash, DeepSeek V3, Qwen3 235B, and ERNIE 4.5 300B, and find strong performance in perception and policy reasoning but persistent challenges in ethics-aware and resource-constrained decision-making. UAVBench establishes a reproducible and physically grounded foundation for benchmarking agentic AI in autonomous aerial systems and advancing next-generation UAV reasoning intelligence. To support open science and reproducibility, we release the UAVBench dataset, the UAVBench_MCQ benchmark, evaluation scripts, and all related materials on GitHub at https://github.com/maferrag/UAVBench
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Apr 28, 2025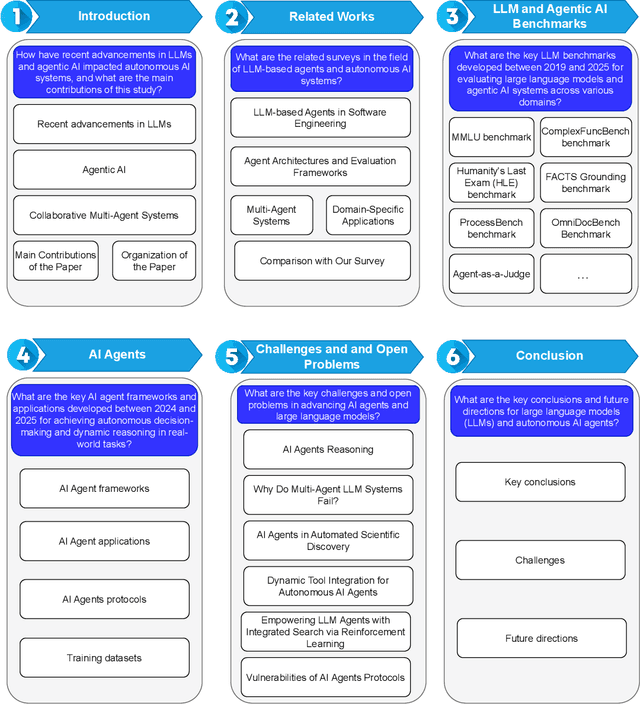
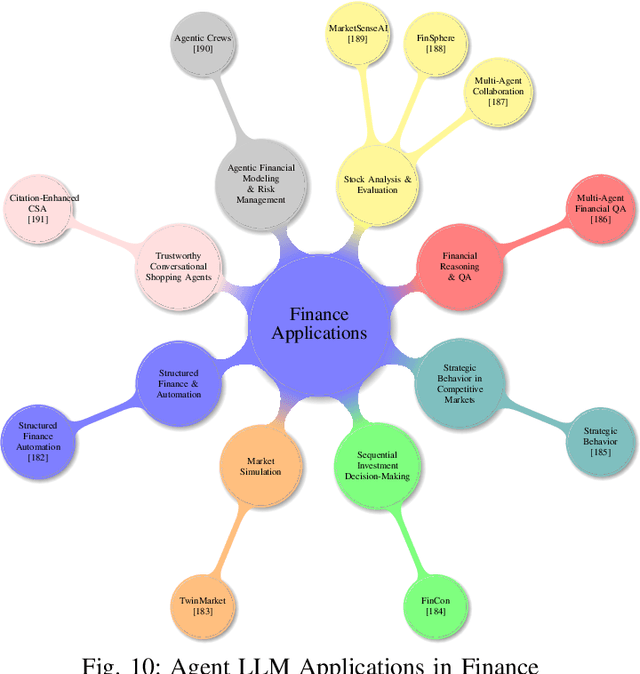
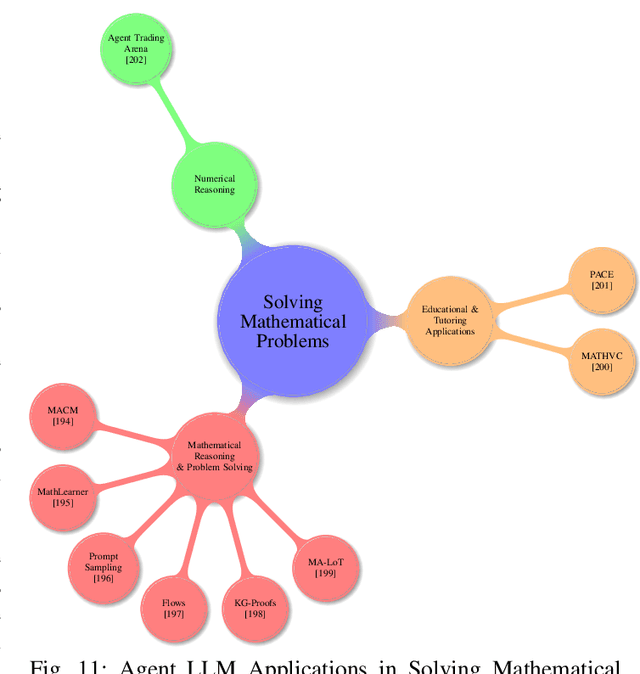
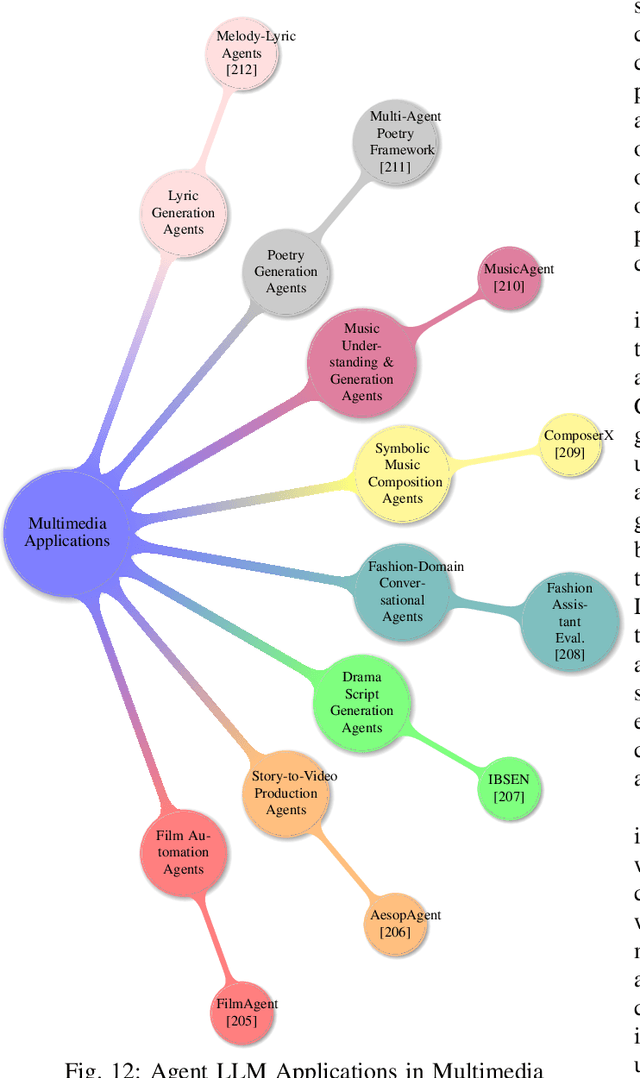
Large language models and autonomous AI agents have evolved rapidly, resulting in a diverse array of evaluation benchmarks, frameworks, and collaboration protocols. However, the landscape remains fragmented and lacks a unified taxonomy or comprehensive survey. Therefore, we present a side-by-side comparison of benchmarks developed between 2019 and 2025 that evaluate these models and agents across multiple domains. In addition, we propose a taxonomy of approximately 60 benchmarks that cover general and academic knowledge reasoning, mathematical problem-solving, code generation and software engineering, factual grounding and retrieval, domain-specific evaluations, multimodal and embodied tasks, task orchestration, and interactive assessments. Furthermore, we review AI-agent frameworks introduced between 2023 and 2025 that integrate large language models with modular toolkits to enable autonomous decision-making and multi-step reasoning. Moreover, we present real-world applications of autonomous AI agents in materials science, biomedical research, academic ideation, software engineering, synthetic data generation, chemical reasoning, mathematical problem-solving, geographic information systems, multimedia, healthcare, and finance. We then survey key agent-to-agent collaboration protocols, namely the Agent Communication Protocol (ACP), the Model Context Protocol (MCP), and the Agent-to-Agent Protocol (A2A). Finally, we discuss recommendations for future research, focusing on advanced reasoning strategies, failure modes in multi-agent LLM systems, automated scientific discovery, dynamic tool integration via reinforcement learning, integrated search capabilities, and security vulnerabilities in agent protocols.
Vulnerability Detection: From Formal Verification to Large Language Models and Hybrid Approaches: A Comprehensive Overview
Mar 13, 2025


Software testing and verification are critical for ensuring the reliability and security of modern software systems. Traditionally, formal verification techniques, such as model checking and theorem proving, have provided rigorous frameworks for detecting bugs and vulnerabilities. However, these methods often face scalability challenges when applied to complex, real-world programs. Recently, the advent of Large Language Models (LLMs) has introduced a new paradigm for software analysis, leveraging their ability to understand insecure coding practices. Although LLMs demonstrate promising capabilities in tasks such as bug prediction and invariant generation, they lack the formal guarantees of classical methods. This paper presents a comprehensive study of state-of-the-art software testing and verification, focusing on three key approaches: classical formal methods, LLM-based analysis, and emerging hybrid techniques, which combine their strengths. We explore each approach's strengths, limitations, and practical applications, highlighting the potential of hybrid systems to address the weaknesses of standalone methods. We analyze whether integrating formal rigor with LLM-driven insights can enhance the effectiveness and scalability of software verification, exploring their viability as a pathway toward more robust and adaptive testing frameworks.
CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection
Mar 12, 2025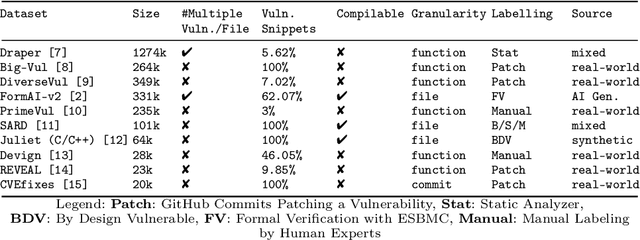
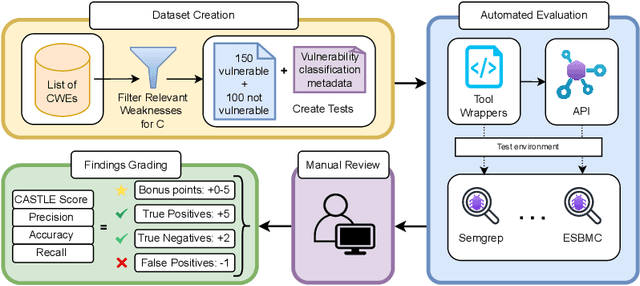
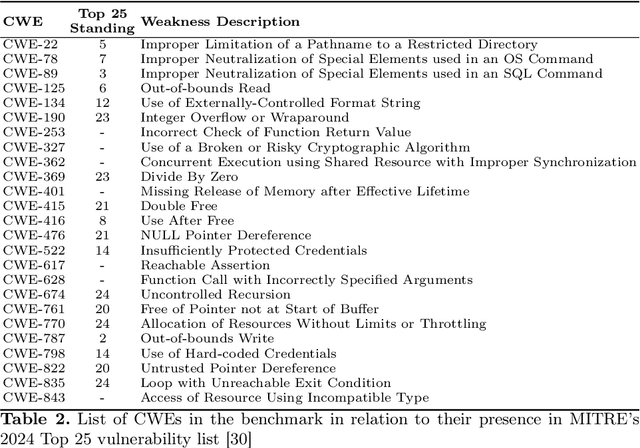
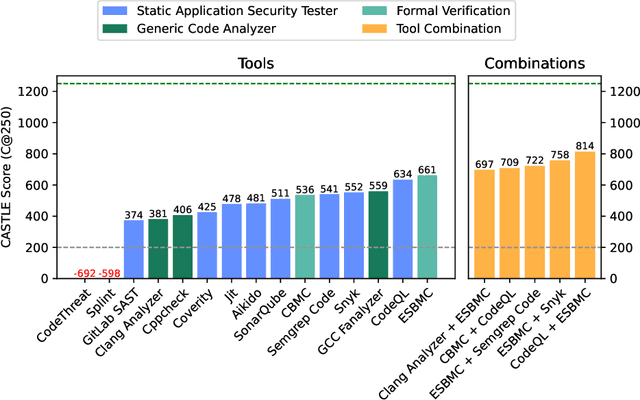
Identifying vulnerabilities in source code is crucial, especially in critical software components. Existing methods such as static analysis, dynamic analysis, formal verification, and recently Large Language Models are widely used to detect security flaws. This paper introduces CASTLE (CWE Automated Security Testing and Low-Level Evaluation), a benchmarking framework for evaluating the vulnerability detection capabilities of different methods. We assess 13 static analysis tools, 10 LLMs, and 2 formal verification tools using a hand-crafted dataset of 250 micro-benchmark programs covering 25 common CWEs. We propose the CASTLE Score, a novel evaluation metric to ensure fair comparison. Our results reveal key differences: ESBMC (a formal verification tool) minimizes false positives but struggles with vulnerabilities beyond model checking, such as weak cryptography or SQL injection. Static analyzers suffer from high false positives, increasing manual validation efforts for developers. LLMs perform exceptionally well in the CASTLE dataset when identifying vulnerabilities in small code snippets. However, their accuracy declines, and hallucinations increase as the code size grows. These results suggest that LLMs could play a pivotal role in future security solutions, particularly within code completion frameworks, where they can provide real-time guidance to prevent vulnerabilities. The dataset is accessible at https://github.com/CASTLE-Benchmark.
Dynamic Intelligence Assessment: Benchmarking LLMs on the Road to AGI with a Focus on Model Confidence
Oct 20, 2024



As machine intelligence evolves, the need to test and compare the problem-solving abilities of different AI models grows. However, current benchmarks are often overly simplistic, allowing models to perform uniformly well, making it difficult to distinguish their capabilities. Additionally, benchmarks typically rely on static question-answer pairs, which models might memorize or guess. To address these limitations, we introduce the Dynamic Intelligence Assessment (DIA), a novel methodology for testing AI models using dynamic question templates and improved metrics across multiple disciplines such as mathematics, cryptography, cybersecurity, and computer science. The accompanying DIA-Bench dataset, which includes 150 diverse and challenging task templates with mutable parameters, is presented in various formats such as text, PDFs, compiled binaries, and visual puzzles. Our framework introduces four new metrics to assess a model's reliability and confidence across multiple attempts. These metrics revealed that even simple questions are frequently answered incorrectly when posed in varying forms, highlighting significant gaps in models' reliability. Notably, models like GPT-4o tended to overestimate their mathematical abilities, while ChatGPT-4o demonstrated better decision-making and performance through effective tool usage. We evaluated eight state-of-the-art large language models (LLMs) using DIA-Bench, showing that current models struggle with complex tasks and often display unexpectedly low confidence, even with simpler questions. The DIA framework sets a new standard for assessing not only problem-solving but also a model's adaptive intelligence and ability to assess its own limitations. The dataset is publicly available on our project's website.
Generative AI and Large Language Models for Cyber Security: All Insights You Need
May 21, 2024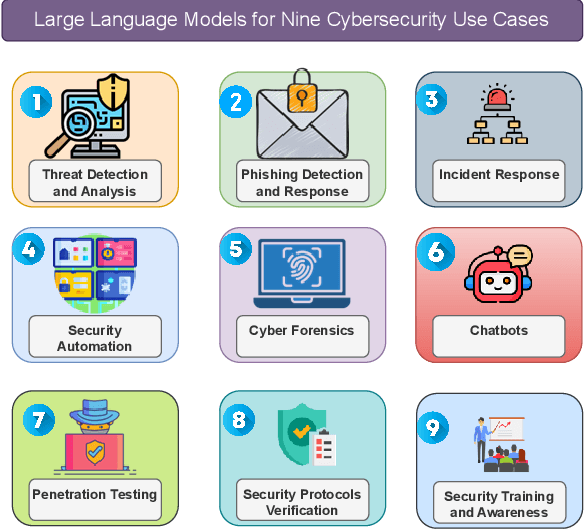
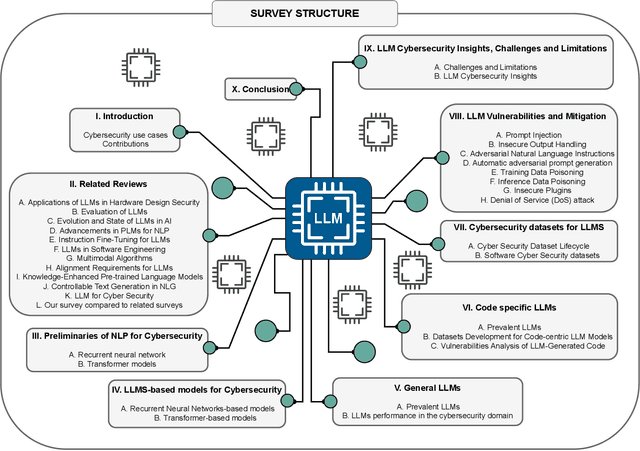
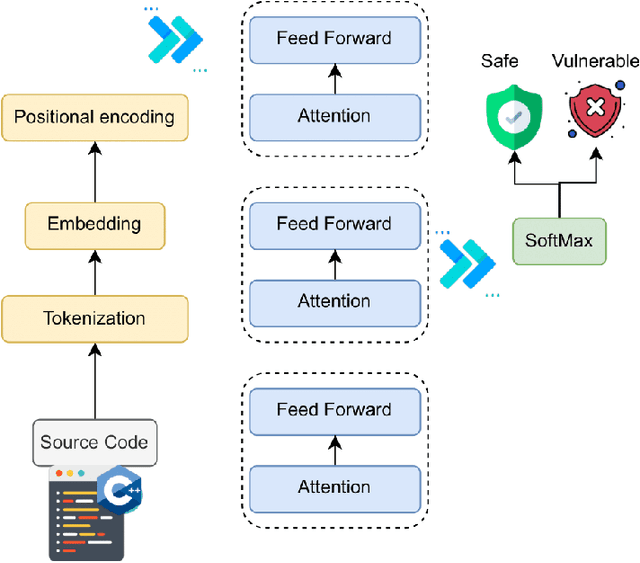
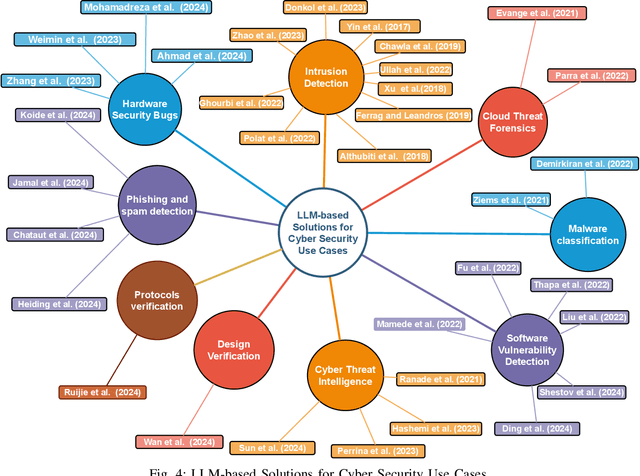
This paper provides a comprehensive review of the future of cybersecurity through Generative AI and Large Language Models (LLMs). We explore LLM applications across various domains, including hardware design security, intrusion detection, software engineering, design verification, cyber threat intelligence, malware detection, and phishing detection. We present an overview of LLM evolution and its current state, focusing on advancements in models such as GPT-4, GPT-3.5, Mixtral-8x7B, BERT, Falcon2, and LLaMA. Our analysis extends to LLM vulnerabilities, such as prompt injection, insecure output handling, data poisoning, DDoS attacks, and adversarial instructions. We delve into mitigation strategies to protect these models, providing a comprehensive look at potential attack scenarios and prevention techniques. Furthermore, we evaluate the performance of 42 LLM models in cybersecurity knowledge and hardware security, highlighting their strengths and weaknesses. We thoroughly evaluate cybersecurity datasets for LLM training and testing, covering the lifecycle from data creation to usage and identifying gaps for future research. In addition, we review new strategies for leveraging LLMs, including techniques like Half-Quadratic Quantization (HQQ), Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO), Quantized Low-Rank Adapters (QLoRA), and Retrieval-Augmented Generation (RAG). These insights aim to enhance real-time cybersecurity defenses and improve the sophistication of LLM applications in threat detection and response. Our paper provides a foundational understanding and strategic direction for integrating LLMs into future cybersecurity frameworks, emphasizing innovation and robust model deployment to safeguard against evolving cyber threats.