 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFIR-Metric: A Benchmark Dataset for Evaluating Large Language Models in Digital Forensics and Incident Response
May 26, 2025Digital Forensics and Incident Response (DFIR) involves analyzing digital evidence to support legal investigations. Large Language Models (LLMs) offer new opportunities in DFIR tasks such as log analysis and memory forensics, but their susceptibility to errors and hallucinations raises concerns in high-stakes contexts. Despite growing interest, there is no comprehensive benchmark to evaluate LLMs across both theoretical and practical DFIR domains. To address this gap, we present DFIR-Metric, a benchmark with three components: (1) Knowledge Assessment: a set of 700 expert-reviewed multiple-choice questions sourced from industry-standard certifications and official documentation; (2) Realistic Forensic Challenges: 150 CTF-style tasks testing multi-step reasoning and evidence correlation; and (3) Practical Analysis: 500 disk and memory forensics cases from the NIST Computer Forensics Tool Testing Program (CFTT). We evaluated 14 LLMs using DFIR-Metric, analyzing both their accuracy and consistency across trials. We also introduce a new metric, the Task Understanding Score (TUS), designed to more effectively evaluate models in scenarios where they achieve near-zero accuracy. This benchmark offers a rigorous, reproducible foundation for advancing AI in digital forensics. All scripts, artifacts, and results are available on the project website at https://github.com/DFIR-Metric.
Vulnerability Detection: From Formal Verification to Large Language Models and Hybrid Approaches: A Comprehensive Overview
Mar 13, 2025


Software testing and verification are critical for ensuring the reliability and security of modern software systems. Traditionally, formal verification techniques, such as model checking and theorem proving, have provided rigorous frameworks for detecting bugs and vulnerabilities. However, these methods often face scalability challenges when applied to complex, real-world programs. Recently, the advent of Large Language Models (LLMs) has introduced a new paradigm for software analysis, leveraging their ability to understand insecure coding practices. Although LLMs demonstrate promising capabilities in tasks such as bug prediction and invariant generation, they lack the formal guarantees of classical methods. This paper presents a comprehensive study of state-of-the-art software testing and verification, focusing on three key approaches: classical formal methods, LLM-based analysis, and emerging hybrid techniques, which combine their strengths. We explore each approach's strengths, limitations, and practical applications, highlighting the potential of hybrid systems to address the weaknesses of standalone methods. We analyze whether integrating formal rigor with LLM-driven insights can enhance the effectiveness and scalability of software verification, exploring their viability as a pathway toward more robust and adaptive testing frameworks.
Dynamic Intelligence Assessment: Benchmarking LLMs on the Road to AGI with a Focus on Model Confidence
Oct 20, 2024



As machine intelligence evolves, the need to test and compare the problem-solving abilities of different AI models grows. However, current benchmarks are often overly simplistic, allowing models to perform uniformly well, making it difficult to distinguish their capabilities. Additionally, benchmarks typically rely on static question-answer pairs, which models might memorize or guess. To address these limitations, we introduce the Dynamic Intelligence Assessment (DIA), a novel methodology for testing AI models using dynamic question templates and improved metrics across multiple disciplines such as mathematics, cryptography, cybersecurity, and computer science. The accompanying DIA-Bench dataset, which includes 150 diverse and challenging task templates with mutable parameters, is presented in various formats such as text, PDFs, compiled binaries, and visual puzzles. Our framework introduces four new metrics to assess a model's reliability and confidence across multiple attempts. These metrics revealed that even simple questions are frequently answered incorrectly when posed in varying forms, highlighting significant gaps in models' reliability. Notably, models like GPT-4o tended to overestimate their mathematical abilities, while ChatGPT-4o demonstrated better decision-making and performance through effective tool usage. We evaluated eight state-of-the-art large language models (LLMs) using DIA-Bench, showing that current models struggle with complex tasks and often display unexpectedly low confidence, even with simpler questions. The DIA framework sets a new standard for assessing not only problem-solving but also a model's adaptive intelligence and ability to assess its own limitations. The dataset is publicly available on our project's website.
Generative AI and Large Language Models for Cyber Security: All Insights You Need
May 21, 2024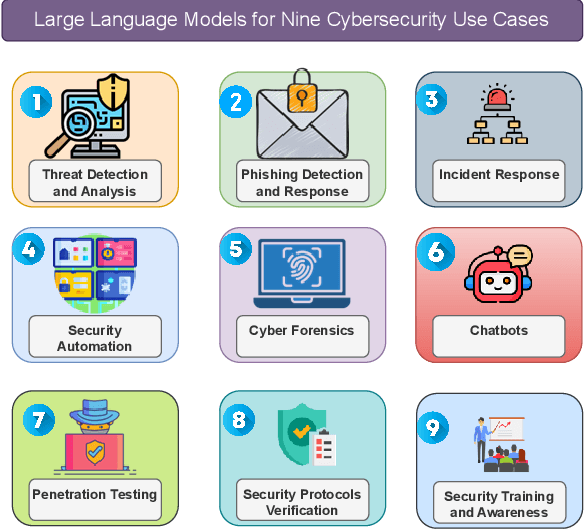
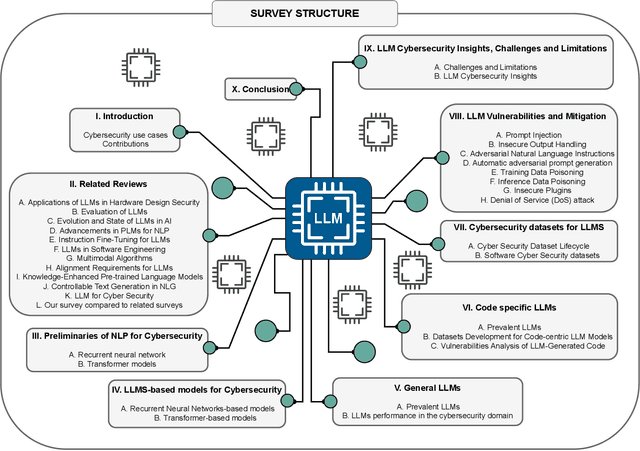
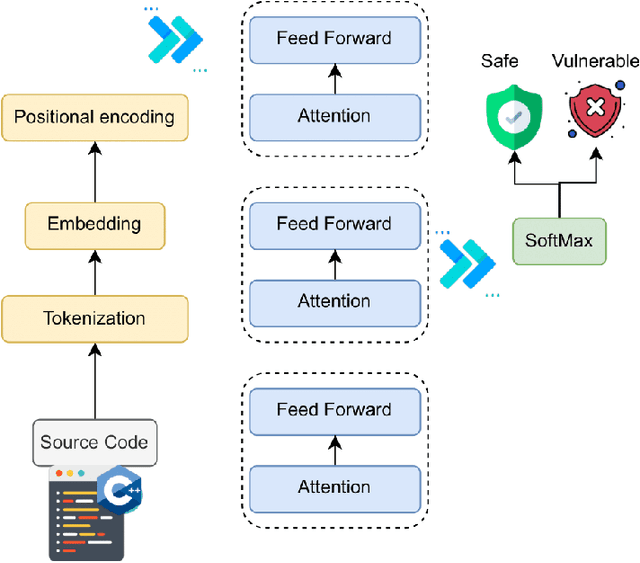
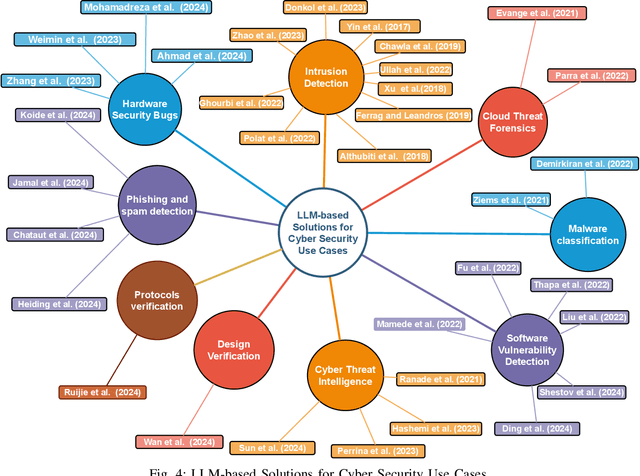
This paper provides a comprehensive review of the future of cybersecurity through Generative AI and Large Language Models (LLMs). We explore LLM applications across various domains, including hardware design security, intrusion detection, software engineering, design verification, cyber threat intelligence, malware detection, and phishing detection. We present an overview of LLM evolution and its current state, focusing on advancements in models such as GPT-4, GPT-3.5, Mixtral-8x7B, BERT, Falcon2, and LLaMA. Our analysis extends to LLM vulnerabilities, such as prompt injection, insecure output handling, data poisoning, DDoS attacks, and adversarial instructions. We delve into mitigation strategies to protect these models, providing a comprehensive look at potential attack scenarios and prevention techniques. Furthermore, we evaluate the performance of 42 LLM models in cybersecurity knowledge and hardware security, highlighting their strengths and weaknesses. We thoroughly evaluate cybersecurity datasets for LLM training and testing, covering the lifecycle from data creation to usage and identifying gaps for future research. In addition, we review new strategies for leveraging LLMs, including techniques like Half-Quadratic Quantization (HQQ), Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO), Quantized Low-Rank Adapters (QLoRA), and Retrieval-Augmented Generation (RAG). These insights aim to enhance real-time cybersecurity defenses and improve the sophistication of LLM applications in threat detection and response. Our paper provides a foundational understanding and strategic direction for integrating LLMs into future cybersecurity frameworks, emphasizing innovation and robust model deployment to safeguard against evolving cyber threats.