 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFIR-Metric: A Benchmark Dataset for Evaluating Large Language Models in Digital Forensics and Incident Response
May 26, 2025



Digital Forensics and Incident Response (DFIR) involves analyzing digital evidence to support legal investigations. Large Language Models (LLMs) offer new opportunities in DFIR tasks such as log analysis and memory forensics, but their susceptibility to errors and hallucinations raises concerns in high-stakes contexts. Despite growing interest, there is no comprehensive benchmark to evaluate LLMs across both theoretical and practical DFIR domains. To address this gap, we present DFIR-Metric, a benchmark with three components: (1) Knowledge Assessment: a set of 700 expert-reviewed multiple-choice questions sourced from industry-standard certifications and official documentation; (2) Realistic Forensic Challenges: 150 CTF-style tasks testing multi-step reasoning and evidence correlation; and (3) Practical Analysis: 500 disk and memory forensics cases from the NIST Computer Forensics Tool Testing Program (CFTT). We evaluated 14 LLMs using DFIR-Metric, analyzing both their accuracy and consistency across trials. We also introduce a new metric, the Task Understanding Score (TUS), designed to more effectively evaluate models in scenarios where they achieve near-zero accuracy. This benchmark offers a rigorous, reproducible foundation for advancing AI in digital forensics. All scripts, artifacts, and results are available on the project website at https://github.com/DFIR-Metric.
Harnessing Chain-of-Thought Metadata for Task Routing and Adversarial Prompt Detection
Mar 27, 2025

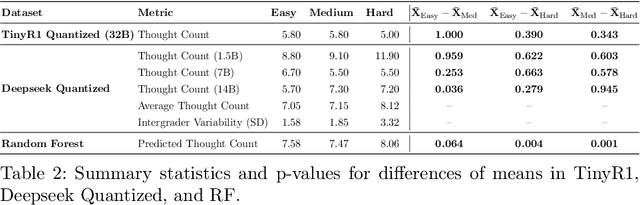

In this work, we propose a metric called Number of Thoughts (NofT) to determine the difficulty of tasks pre-prompting and support Large Language Models (LLMs) in production contexts. By setting thresholds based on the number of thoughts, this metric can discern the difficulty of prompts and support more effective prompt routing. A 2% decrease in latency is achieved when routing prompts from the MathInstruct dataset through quantized, distilled versions of Deepseek with 1.7 billion, 7 billion, and 14 billion parameters. Moreover, this metric can be used to detect adversarial prompts used in prompt injection attacks with high efficacy. The Number of Thoughts can inform a classifier that achieves 95% accuracy in adversarial prompt detection. Our experiments ad datasets used are available on our GitHub page: https://github.com/rymarinelli/Number_Of_Thoughts/tree/main.
Vulnerability Detection: From Formal Verification to Large Language Models and Hybrid Approaches: A Comprehensive Overview
Mar 13, 2025


Software testing and verification are critical for ensuring the reliability and security of modern software systems. Traditionally, formal verification techniques, such as model checking and theorem proving, have provided rigorous frameworks for detecting bugs and vulnerabilities. However, these methods often face scalability challenges when applied to complex, real-world programs. Recently, the advent of Large Language Models (LLMs) has introduced a new paradigm for software analysis, leveraging their ability to understand insecure coding practices. Although LLMs demonstrate promising capabilities in tasks such as bug prediction and invariant generation, they lack the formal guarantees of classical methods. This paper presents a comprehensive study of state-of-the-art software testing and verification, focusing on three key approaches: classical formal methods, LLM-based analysis, and emerging hybrid techniques, which combine their strengths. We explore each approach's strengths, limitations, and practical applications, highlighting the potential of hybrid systems to address the weaknesses of standalone methods. We analyze whether integrating formal rigor with LLM-driven insights can enhance the effectiveness and scalability of software verification, exploring their viability as a pathway toward more robust and adaptive testing frameworks.
Dynamic Intelligence Assessment: Benchmarking LLMs on the Road to AGI with a Focus on Model Confidence
Oct 20, 2024



As machine intelligence evolves, the need to test and compare the problem-solving abilities of different AI models grows. However, current benchmarks are often overly simplistic, allowing models to perform uniformly well, making it difficult to distinguish their capabilities. Additionally, benchmarks typically rely on static question-answer pairs, which models might memorize or guess. To address these limitations, we introduce the Dynamic Intelligence Assessment (DIA), a novel methodology for testing AI models using dynamic question templates and improved metrics across multiple disciplines such as mathematics, cryptography, cybersecurity, and computer science. The accompanying DIA-Bench dataset, which includes 150 diverse and challenging task templates with mutable parameters, is presented in various formats such as text, PDFs, compiled binaries, and visual puzzles. Our framework introduces four new metrics to assess a model's reliability and confidence across multiple attempts. These metrics revealed that even simple questions are frequently answered incorrectly when posed in varying forms, highlighting significant gaps in models' reliability. Notably, models like GPT-4o tended to overestimate their mathematical abilities, while ChatGPT-4o demonstrated better decision-making and performance through effective tool usage. We evaluated eight state-of-the-art large language models (LLMs) using DIA-Bench, showing that current models struggle with complex tasks and often display unexpectedly low confidence, even with simpler questions. The DIA framework sets a new standard for assessing not only problem-solving but also a model's adaptive intelligence and ability to assess its own limitations. The dataset is publicly available on our project's website.
Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models
Apr 29, 2024This study provides a comparative analysis of state-of-the-art large language models (LLMs), analyzing how likely they generate vulnerabilities when writing simple C programs using a neutral zero-shot prompt. We address a significant gap in the literature concerning the security properties of code produced by these models without specific directives. N. Tihanyi et al. introduced the FormAI dataset at PROMISE '23, containing 112,000 GPT-3.5-generated C programs, with over 51.24% identified as vulnerable. We expand that work by introducing the FormAI-v2 dataset comprising 265,000 compilable C programs generated using various LLMs, including robust models such as Google's GEMINI-pro, OpenAI's GPT-4, and TII's 180 billion-parameter Falcon, to Meta's specialized 13 billion-parameter CodeLLama2 and various other compact models. Each program in the dataset is labelled based on the vulnerabilities detected in its source code through formal verification using the Efficient SMT-based Context-Bounded Model Checker (ESBMC). This technique eliminates false positives by delivering a counterexample and ensures the exclusion of false negatives by completing the verification process. Our study reveals that at least 63.47% of the generated programs are vulnerable. The differences between the models are minor, as they all display similar coding errors with slight variations. Our research highlights that while LLMs offer promising capabilities for code generation, deploying their output in a production environment requires risk assessment and validation.
LLMs in Web-Development: Evaluating LLM-Generated PHP code unveiling vulnerabilities and limitations
Apr 21, 2024
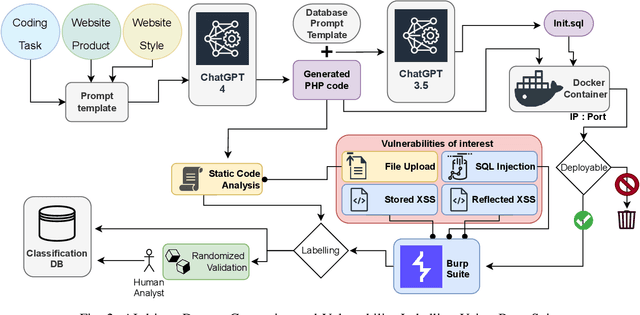

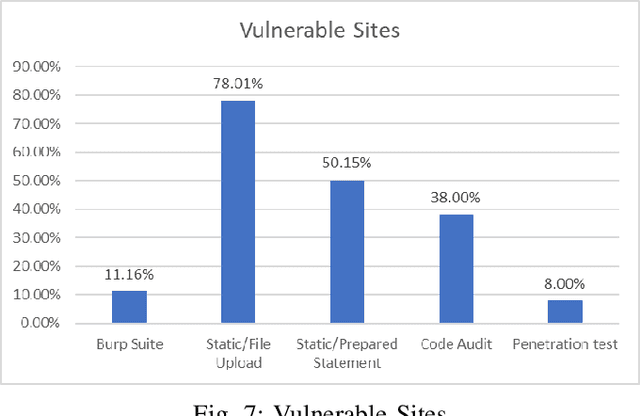
This research carries out a comprehensive examination of web application code security, when generated by Large Language Models through analyzing a dataset comprising 2,500 small dynamic PHP websites. These AI-generated sites are scanned for security vulnerabilities after being deployed as standalone websites in Docker containers. The evaluation of the websites was conducted using a hybrid methodology, incorporating the Burp Suite active scanner, static analysis, and manual checks. Our investigation zeroes in on identifying and analyzing File Upload, SQL Injection, Stored XSS, and Reflected XSS. This approach not only underscores the potential security flaws within AI-generated PHP code but also provides a critical perspective on the reliability and security implications of deploying such code in real-world scenarios. Our evaluation confirms that 27% of the programs generated by GPT-4 verifiably contains vulnerabilities in the PHP code, where this number -- based on static scanning and manual verification -- is potentially much higher. This poses a substantial risks to software safety and security. In an effort to contribute to the research community and foster further analysis, we have made the source codes publicly available, alongside a record enumerating the detected vulnerabilities for each sample. This study not only sheds light on the security aspects of AI-generated code but also underscores the critical need for rigorous testing and evaluation of such technologies for software development.
The FormAI Dataset: Generative AI in Software Security Through the Lens of Formal Verification
Jul 05, 2023This paper presents the FormAI dataset, a large collection of 112,000 AI-generated compilable and independent C programs with vulnerability classification. We introduce a dynamic zero-shot prompting technique, constructed to spawn a diverse set of programs utilizing Large Language Models (LLMs). The dataset is generated by GPT-3.5-turbo and comprises programs with varying levels of complexity. Some programs handle complicated tasks such as network management, table games, or encryption, while others deal with simpler tasks like string manipulation. Every program is labeled with the vulnerabilities found within the source code, indicating the type, line number, and vulnerable function name. This is accomplished by employing a formal verification method using the Efficient SMT-based Bounded Model Checker (ESBMC), which performs model checking, abstract interpretation, constraint programming, and satisfiability modulo theories, to reason over safety/security properties in programs. This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports. This property of the dataset makes it suitable for evaluating the effectiveness of various static and dynamic analysis tools. Furthermore, we have associated the identified vulnerabilities with relevant Common Weakness Enumeration (CWE) numbers. We make the source code available for the 112,000 programs, accompanied by a comprehensive list detailing the vulnerabilities detected in each individual program including location and function name, which makes the dataset ideal to train LLMs and machine learning algorithms.