 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFIR-Metric: A Benchmark Dataset for Evaluating Large Language Models in Digital Forensics and Incident Response
May 26, 2025



Digital Forensics and Incident Response (DFIR) involves analyzing digital evidence to support legal investigations. Large Language Models (LLMs) offer new opportunities in DFIR tasks such as log analysis and memory forensics, but their susceptibility to errors and hallucinations raises concerns in high-stakes contexts. Despite growing interest, there is no comprehensive benchmark to evaluate LLMs across both theoretical and practical DFIR domains. To address this gap, we present DFIR-Metric, a benchmark with three components: (1) Knowledge Assessment: a set of 700 expert-reviewed multiple-choice questions sourced from industry-standard certifications and official documentation; (2) Realistic Forensic Challenges: 150 CTF-style tasks testing multi-step reasoning and evidence correlation; and (3) Practical Analysis: 500 disk and memory forensics cases from the NIST Computer Forensics Tool Testing Program (CFTT). We evaluated 14 LLMs using DFIR-Metric, analyzing both their accuracy and consistency across trials. We also introduce a new metric, the Task Understanding Score (TUS), designed to more effectively evaluate models in scenarios where they achieve near-zero accuracy. This benchmark offers a rigorous, reproducible foundation for advancing AI in digital forensics. All scripts, artifacts, and results are available on the project website at https://github.com/DFIR-Metric.
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Apr 28, 2025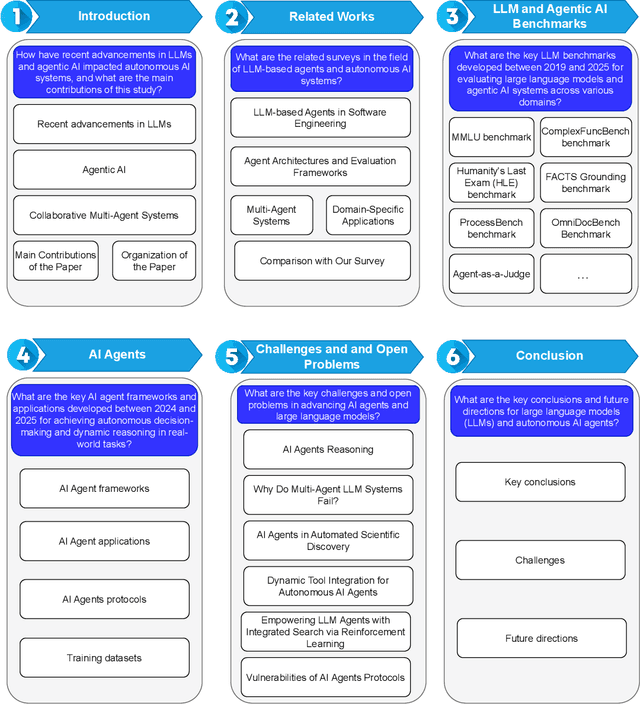
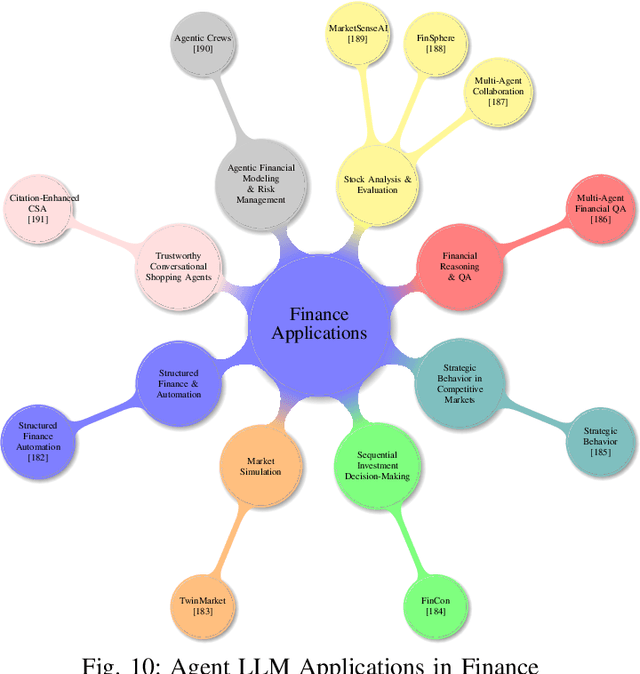
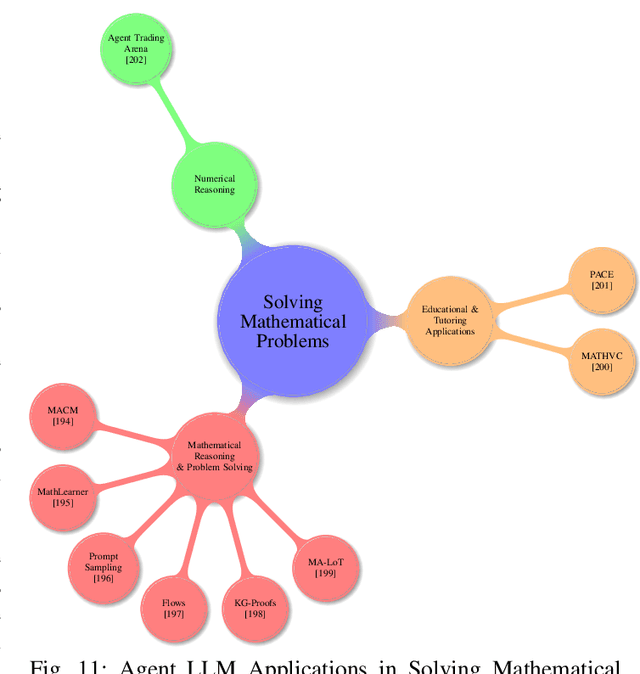
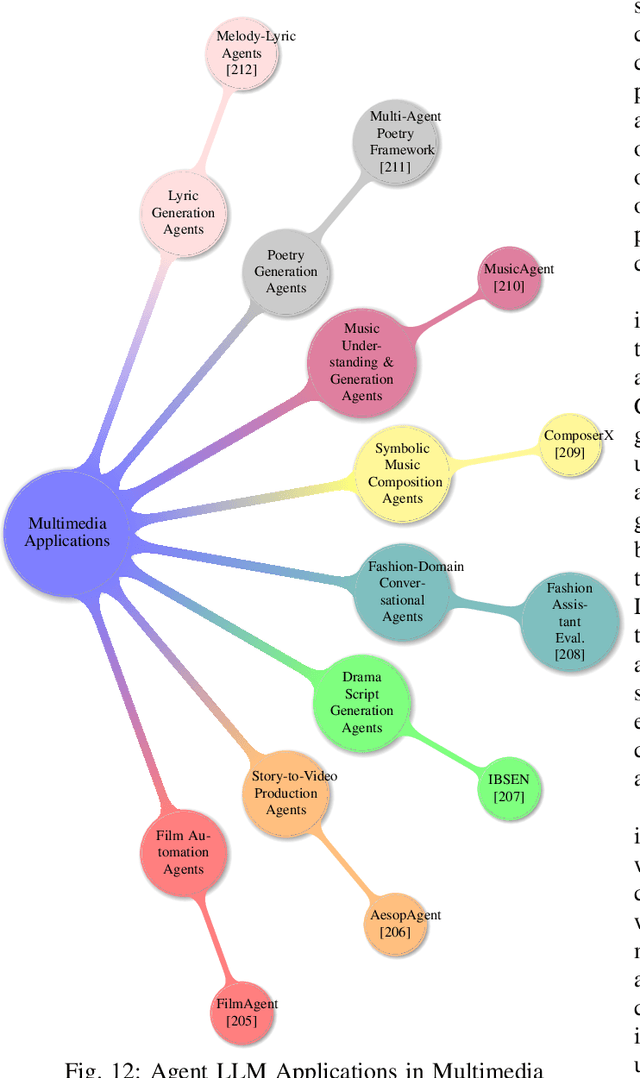
Large language models and autonomous AI agents have evolved rapidly, resulting in a diverse array of evaluation benchmarks, frameworks, and collaboration protocols. However, the landscape remains fragmented and lacks a unified taxonomy or comprehensive survey. Therefore, we present a side-by-side comparison of benchmarks developed between 2019 and 2025 that evaluate these models and agents across multiple domains. In addition, we propose a taxonomy of approximately 60 benchmarks that cover general and academic knowledge reasoning, mathematical problem-solving, code generation and software engineering, factual grounding and retrieval, domain-specific evaluations, multimodal and embodied tasks, task orchestration, and interactive assessments. Furthermore, we review AI-agent frameworks introduced between 2023 and 2025 that integrate large language models with modular toolkits to enable autonomous decision-making and multi-step reasoning. Moreover, we present real-world applications of autonomous AI agents in materials science, biomedical research, academic ideation, software engineering, synthetic data generation, chemical reasoning, mathematical problem-solving, geographic information systems, multimedia, healthcare, and finance. We then survey key agent-to-agent collaboration protocols, namely the Agent Communication Protocol (ACP), the Model Context Protocol (MCP), and the Agent-to-Agent Protocol (A2A). Finally, we discuss recommendations for future research, focusing on advanced reasoning strategies, failure modes in multi-agent LLM systems, automated scientific discovery, dynamic tool integration via reinforcement learning, integrated search capabilities, and security vulnerabilities in agent protocols.
Vulnerability Detection: From Formal Verification to Large Language Models and Hybrid Approaches: A Comprehensive Overview
Mar 13, 2025


Software testing and verification are critical for ensuring the reliability and security of modern software systems. Traditionally, formal verification techniques, such as model checking and theorem proving, have provided rigorous frameworks for detecting bugs and vulnerabilities. However, these methods often face scalability challenges when applied to complex, real-world programs. Recently, the advent of Large Language Models (LLMs) has introduced a new paradigm for software analysis, leveraging their ability to understand insecure coding practices. Although LLMs demonstrate promising capabilities in tasks such as bug prediction and invariant generation, they lack the formal guarantees of classical methods. This paper presents a comprehensive study of state-of-the-art software testing and verification, focusing on three key approaches: classical formal methods, LLM-based analysis, and emerging hybrid techniques, which combine their strengths. We explore each approach's strengths, limitations, and practical applications, highlighting the potential of hybrid systems to address the weaknesses of standalone methods. We analyze whether integrating formal rigor with LLM-driven insights can enhance the effectiveness and scalability of software verification, exploring their viability as a pathway toward more robust and adaptive testing frameworks.
CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection
Mar 12, 2025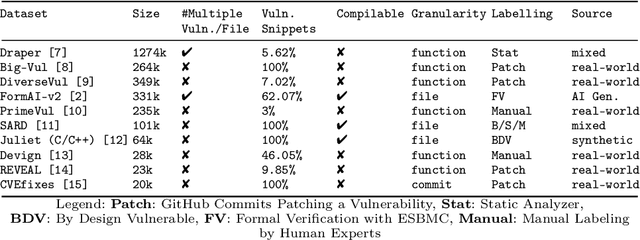
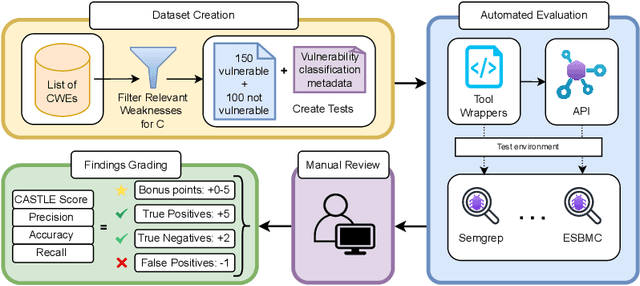
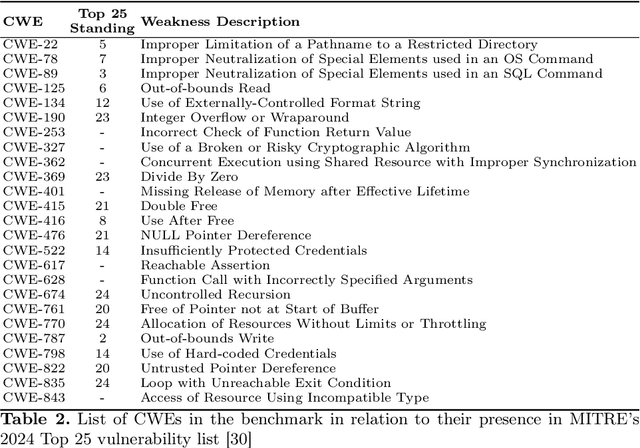
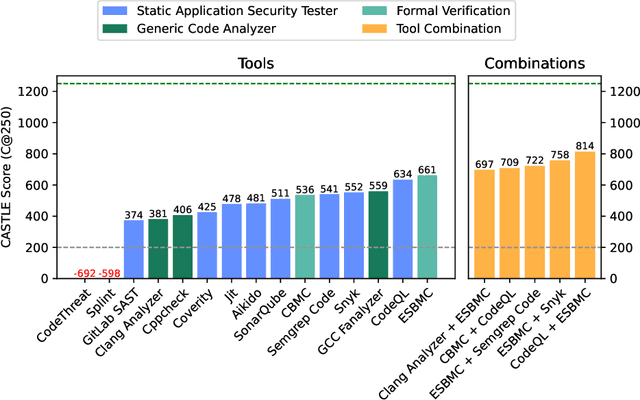
Identifying vulnerabilities in source code is crucial, especially in critical software components. Existing methods such as static analysis, dynamic analysis, formal verification, and recently Large Language Models are widely used to detect security flaws. This paper introduces CASTLE (CWE Automated Security Testing and Low-Level Evaluation), a benchmarking framework for evaluating the vulnerability detection capabilities of different methods. We assess 13 static analysis tools, 10 LLMs, and 2 formal verification tools using a hand-crafted dataset of 250 micro-benchmark programs covering 25 common CWEs. We propose the CASTLE Score, a novel evaluation metric to ensure fair comparison. Our results reveal key differences: ESBMC (a formal verification tool) minimizes false positives but struggles with vulnerabilities beyond model checking, such as weak cryptography or SQL injection. Static analyzers suffer from high false positives, increasing manual validation efforts for developers. LLMs perform exceptionally well in the CASTLE dataset when identifying vulnerabilities in small code snippets. However, their accuracy declines, and hallucinations increase as the code size grows. These results suggest that LLMs could play a pivotal role in future security solutions, particularly within code completion frameworks, where they can provide real-time guidance to prevent vulnerabilities. The dataset is accessible at https://github.com/CASTLE-Benchmark.
Dynamic Intelligence Assessment: Benchmarking LLMs on the Road to AGI with a Focus on Model Confidence
Oct 20, 2024



As machine intelligence evolves, the need to test and compare the problem-solving abilities of different AI models grows. However, current benchmarks are often overly simplistic, allowing models to perform uniformly well, making it difficult to distinguish their capabilities. Additionally, benchmarks typically rely on static question-answer pairs, which models might memorize or guess. To address these limitations, we introduce the Dynamic Intelligence Assessment (DIA), a novel methodology for testing AI models using dynamic question templates and improved metrics across multiple disciplines such as mathematics, cryptography, cybersecurity, and computer science. The accompanying DIA-Bench dataset, which includes 150 diverse and challenging task templates with mutable parameters, is presented in various formats such as text, PDFs, compiled binaries, and visual puzzles. Our framework introduces four new metrics to assess a model's reliability and confidence across multiple attempts. These metrics revealed that even simple questions are frequently answered incorrectly when posed in varying forms, highlighting significant gaps in models' reliability. Notably, models like GPT-4o tended to overestimate their mathematical abilities, while ChatGPT-4o demonstrated better decision-making and performance through effective tool usage. We evaluated eight state-of-the-art large language models (LLMs) using DIA-Bench, showing that current models struggle with complex tasks and often display unexpectedly low confidence, even with simpler questions. The DIA framework sets a new standard for assessing not only problem-solving but also a model's adaptive intelligence and ability to assess its own limitations. The dataset is publicly available on our project's website.
Generative AI and Large Language Models for Cyber Security: All Insights You Need
May 21, 2024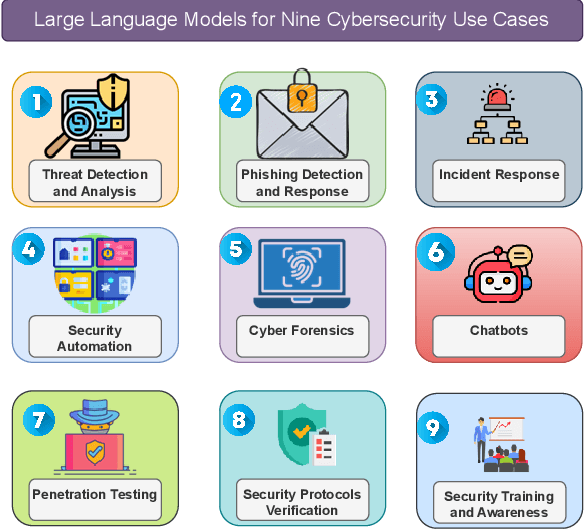
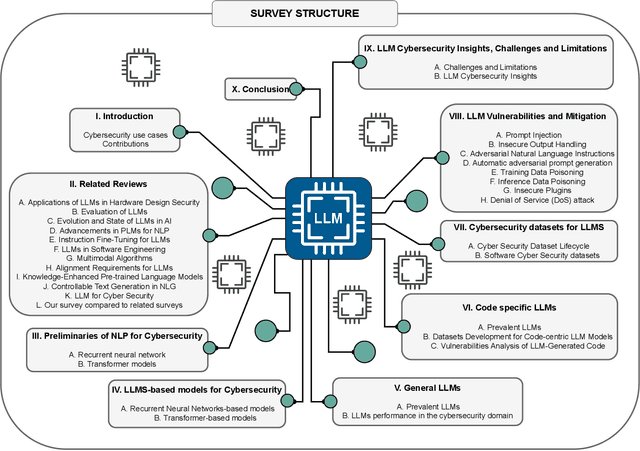
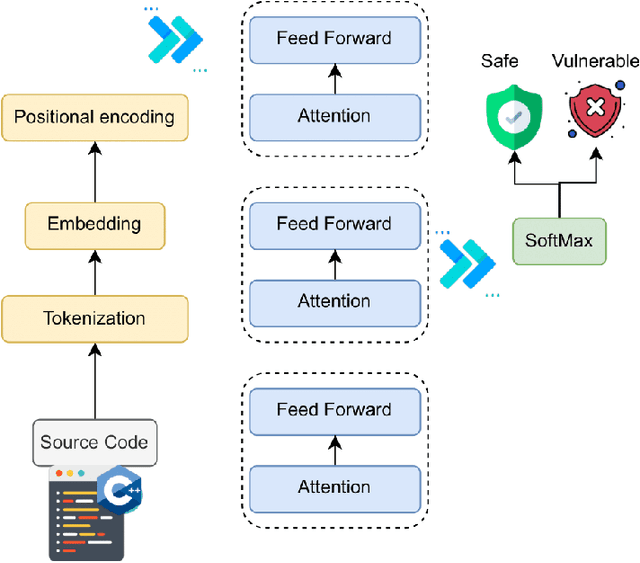
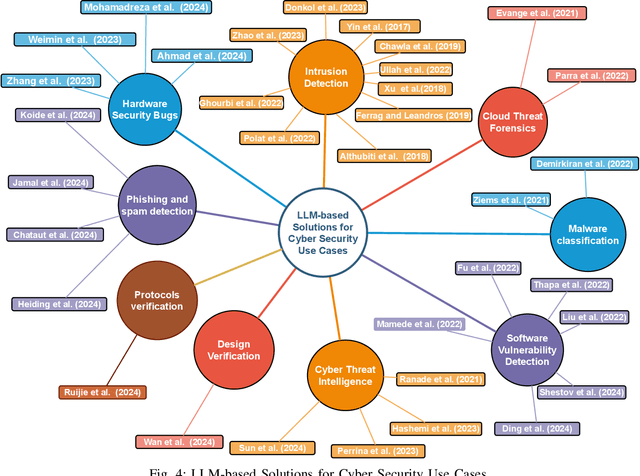
This paper provides a comprehensive review of the future of cybersecurity through Generative AI and Large Language Models (LLMs). We explore LLM applications across various domains, including hardware design security, intrusion detection, software engineering, design verification, cyber threat intelligence, malware detection, and phishing detection. We present an overview of LLM evolution and its current state, focusing on advancements in models such as GPT-4, GPT-3.5, Mixtral-8x7B, BERT, Falcon2, and LLaMA. Our analysis extends to LLM vulnerabilities, such as prompt injection, insecure output handling, data poisoning, DDoS attacks, and adversarial instructions. We delve into mitigation strategies to protect these models, providing a comprehensive look at potential attack scenarios and prevention techniques. Furthermore, we evaluate the performance of 42 LLM models in cybersecurity knowledge and hardware security, highlighting their strengths and weaknesses. We thoroughly evaluate cybersecurity datasets for LLM training and testing, covering the lifecycle from data creation to usage and identifying gaps for future research. In addition, we review new strategies for leveraging LLMs, including techniques like Half-Quadratic Quantization (HQQ), Reinforcement Learning with Human Feedback (RLHF), Direct Preference Optimization (DPO), Quantized Low-Rank Adapters (QLoRA), and Retrieval-Augmented Generation (RAG). These insights aim to enhance real-time cybersecurity defenses and improve the sophistication of LLM applications in threat detection and response. Our paper provides a foundational understanding and strategic direction for integrating LLMs into future cybersecurity frameworks, emphasizing innovation and robust model deployment to safeguard against evolving cyber threats.
Do Neutral Prompts Produce Insecure Code? FormAI-v2 Dataset: Labelling Vulnerabilities in Code Generated by Large Language Models
Apr 29, 2024This study provides a comparative analysis of state-of-the-art large language models (LLMs), analyzing how likely they generate vulnerabilities when writing simple C programs using a neutral zero-shot prompt. We address a significant gap in the literature concerning the security properties of code produced by these models without specific directives. N. Tihanyi et al. introduced the FormAI dataset at PROMISE '23, containing 112,000 GPT-3.5-generated C programs, with over 51.24% identified as vulnerable. We expand that work by introducing the FormAI-v2 dataset comprising 265,000 compilable C programs generated using various LLMs, including robust models such as Google's GEMINI-pro, OpenAI's GPT-4, and TII's 180 billion-parameter Falcon, to Meta's specialized 13 billion-parameter CodeLLama2 and various other compact models. Each program in the dataset is labelled based on the vulnerabilities detected in its source code through formal verification using the Efficient SMT-based Context-Bounded Model Checker (ESBMC). This technique eliminates false positives by delivering a counterexample and ensures the exclusion of false negatives by completing the verification process. Our study reveals that at least 63.47% of the generated programs are vulnerable. The differences between the models are minor, as they all display similar coding errors with slight variations. Our research highlights that while LLMs offer promising capabilities for code generation, deploying their output in a production environment requires risk assessment and validation.
CyberMetric: A Benchmark Dataset for Evaluating Large Language Models Knowledge in Cybersecurity
Feb 12, 2024



Large Language Models (LLMs) excel across various domains, from computer vision to medical diagnostics. However, understanding the diverse landscape of cybersecurity, encompassing cryptography, reverse engineering, and managerial facets like risk assessment, presents a challenge, even for human experts. In this paper, we introduce CyberMetric, a benchmark dataset comprising 10,000 questions sourced from standards, certifications, research papers, books, and other publications in the cybersecurity domain. The questions are created through a collaborative process, i.e., merging expert knowledge with LLMs, including GPT-3.5 and Falcon-180B. Human experts spent over 200 hours verifying their accuracy and relevance. Beyond assessing LLMs' knowledge, the dataset's main goal is to facilitate a fair comparison between humans and different LLMs in cybersecurity. To achieve this, we carefully selected 80 questions covering a wide range of topics within cybersecurity and involved 30 participants of diverse expertise levels, facilitating a comprehensive comparison between human and machine intelligence in this area. The findings revealed that LLMs outperformed humans in almost every aspect of cybersecurity.
SecureFalcon: The Next Cyber Reasoning System for Cyber Security
Jul 13, 2023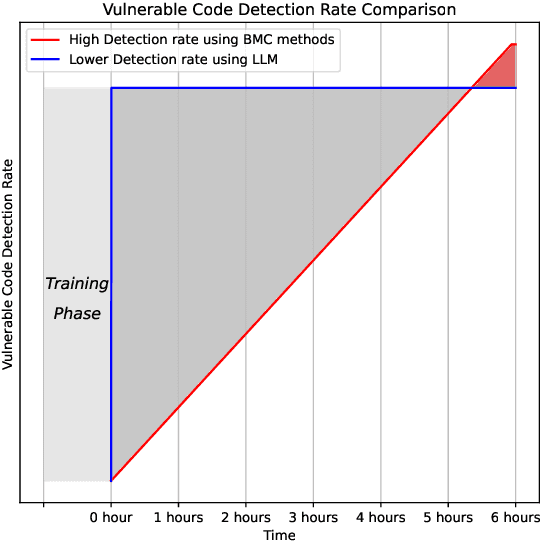
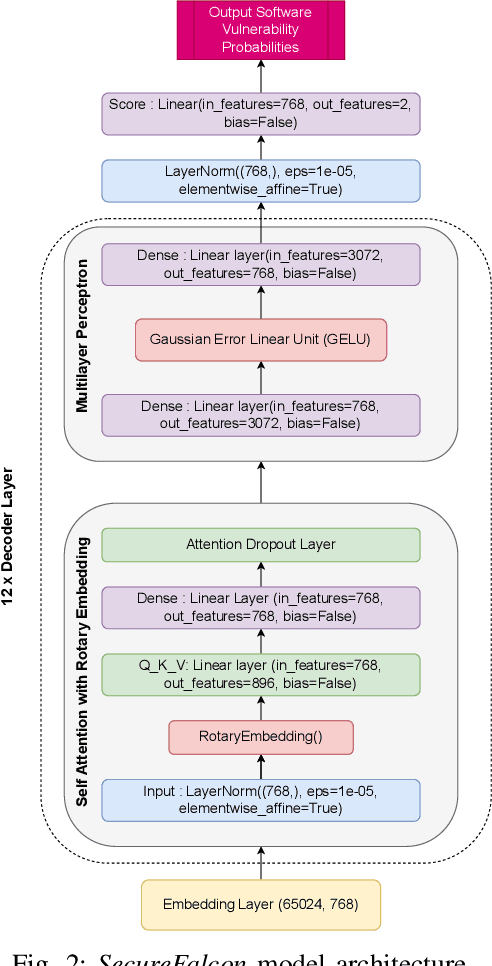
Software vulnerabilities leading to various detriments such as crashes, data loss, and security breaches, significantly hinder the quality, affecting the market adoption of software applications and systems. Although traditional methods such as automated software testing, fault localization, and repair have been intensively studied, static analysis tools are most commonly used and have an inherent false positives rate, posing a solid challenge to developer productivity. Large Language Models (LLMs) offer a promising solution to these persistent issues. Among these, FalconLLM has shown substantial potential in identifying intricate patterns and complex vulnerabilities, hence crucial in software vulnerability detection. In this paper, for the first time, FalconLLM is being fine-tuned for cybersecurity applications, thus introducing SecureFalcon, an innovative model architecture built upon FalconLLM. SecureFalcon is trained to differentiate between vulnerable and non-vulnerable C code samples. We build a new training dataset, FormAI, constructed thanks to Generative Artificial Intelligence (AI) and formal verification to evaluate its performance. SecureFalcon achieved an impressive 94% accuracy rate in detecting software vulnerabilities, emphasizing its significant potential to redefine software vulnerability detection methods in cybersecurity.
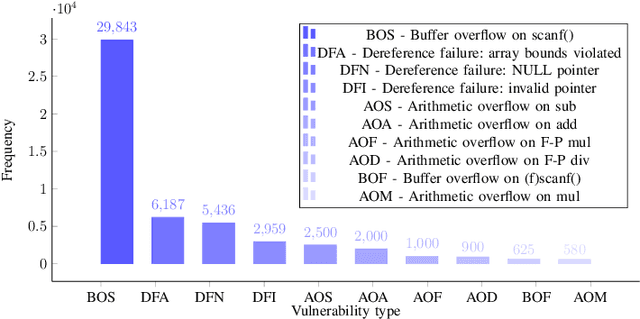
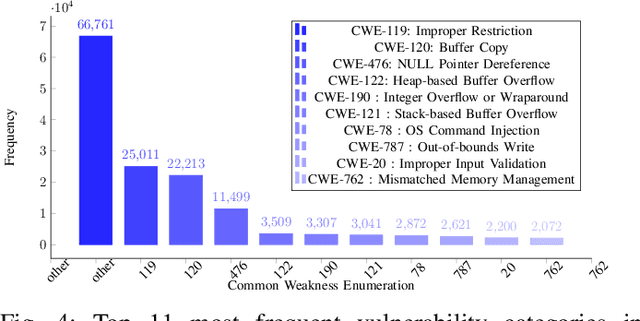
The FormAI Dataset: Generative AI in Software Security Through the Lens of Formal Verification
Jul 05, 2023This paper presents the FormAI dataset, a large collection of 112,000 AI-generated compilable and independent C programs with vulnerability classification. We introduce a dynamic zero-shot prompting technique, constructed to spawn a diverse set of programs utilizing Large Language Models (LLMs). The dataset is generated by GPT-3.5-turbo and comprises programs with varying levels of complexity. Some programs handle complicated tasks such as network management, table games, or encryption, while others deal with simpler tasks like string manipulation. Every program is labeled with the vulnerabilities found within the source code, indicating the type, line number, and vulnerable function name. This is accomplished by employing a formal verification method using the Efficient SMT-based Bounded Model Checker (ESBMC), which performs model checking, abstract interpretation, constraint programming, and satisfiability modulo theories, to reason over safety/security properties in programs. This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports. This property of the dataset makes it suitable for evaluating the effectiveness of various static and dynamic analysis tools. Furthermore, we have associated the identified vulnerabilities with relevant Common Weakness Enumeration (CWE) numbers. We make the source code available for the 112,000 programs, accompanied by a comprehensive list detailing the vulnerabilities detected in each individual program including location and function name, which makes the dataset ideal to train LLMs and machine learning algorithms.