 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelecomGPT: A Framework to Build Telecom-Specfic Large Language Models
Jul 12, 2024



Large Language Models (LLMs) have the potential to revolutionize the Sixth Generation (6G) communication networks. However, current mainstream LLMs generally lack the specialized knowledge in telecom domain. In this paper, for the first time, we propose a pipeline to adapt any general purpose LLMs to a telecom-specific LLMs. We collect and build telecom-specific pre-train dataset, instruction dataset, preference dataset to perform continual pre-training, instruct tuning and alignment tuning respectively. Besides, due to the lack of widely accepted evaluation benchmarks in telecom domain, we extend existing evaluation benchmarks and proposed three new benchmarks, namely, Telecom Math Modeling, Telecom Open QnA and Telecom Code Tasks. These new benchmarks provide a holistic evaluation of the capabilities of LLMs including math modeling, Open-Ended question answering, code generation, infilling, summarization and analysis in telecom domain. Our fine-tuned LLM TelecomGPT outperforms state of the art (SOTA) LLMs including GPT-4, Llama-3 and Mistral in Telecom Math Modeling benchmark significantly and achieve comparable performance in various evaluation benchmarks such as TeleQnA, 3GPP technical documents classification, telecom code summary and generation and infilling.
SecureFalcon: The Next Cyber Reasoning System for Cyber Security
Jul 13, 2023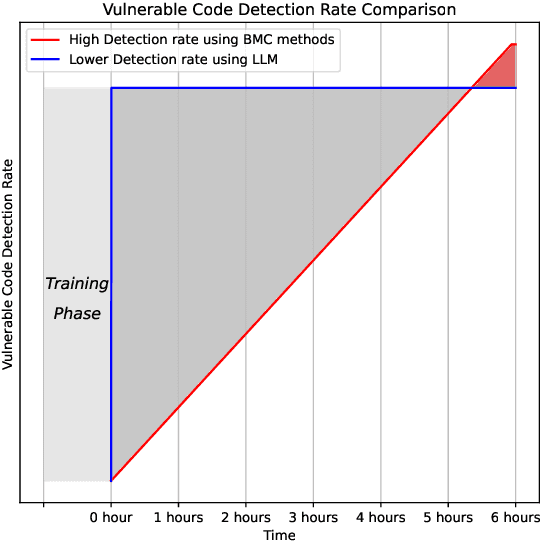
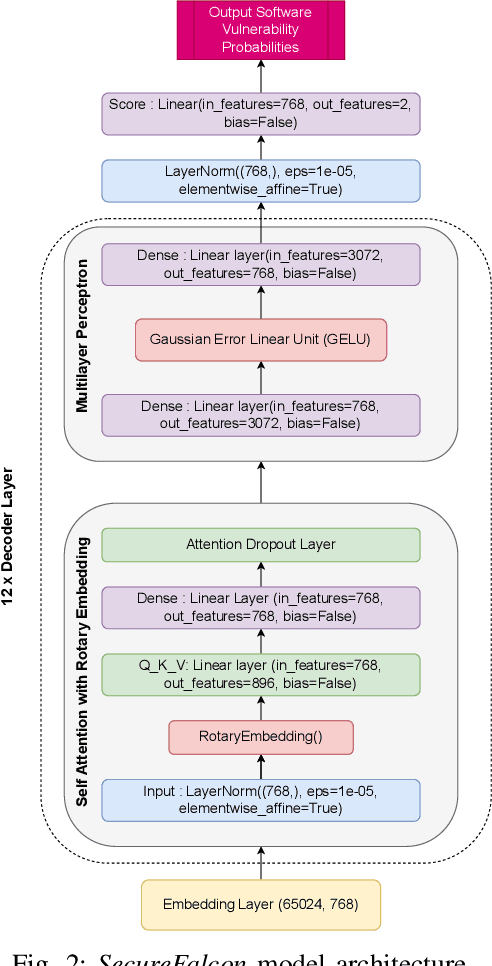
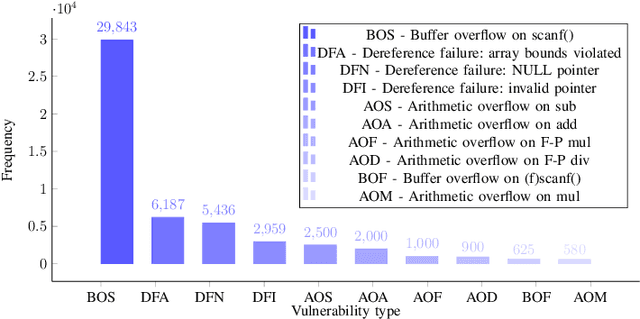
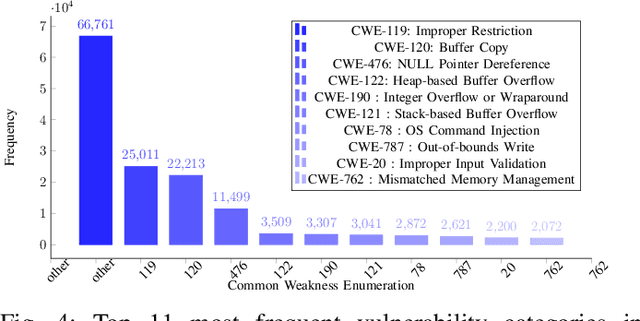
Software vulnerabilities leading to various detriments such as crashes, data loss, and security breaches, significantly hinder the quality, affecting the market adoption of software applications and systems. Although traditional methods such as automated software testing, fault localization, and repair have been intensively studied, static analysis tools are most commonly used and have an inherent false positives rate, posing a solid challenge to developer productivity. Large Language Models (LLMs) offer a promising solution to these persistent issues. Among these, FalconLLM has shown substantial potential in identifying intricate patterns and complex vulnerabilities, hence crucial in software vulnerability detection. In this paper, for the first time, FalconLLM is being fine-tuned for cybersecurity applications, thus introducing SecureFalcon, an innovative model architecture built upon FalconLLM. SecureFalcon is trained to differentiate between vulnerable and non-vulnerable C code samples. We build a new training dataset, FormAI, constructed thanks to Generative Artificial Intelligence (AI) and formal verification to evaluate its performance. SecureFalcon achieved an impressive 94% accuracy rate in detecting software vulnerabilities, emphasizing its significant potential to redefine software vulnerability detection methods in cybersecurity.
Revolutionizing Cyber Threat Detection with Large Language Models
Jun 25, 2023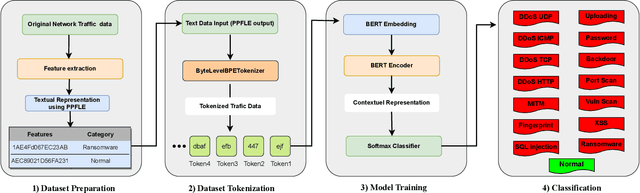
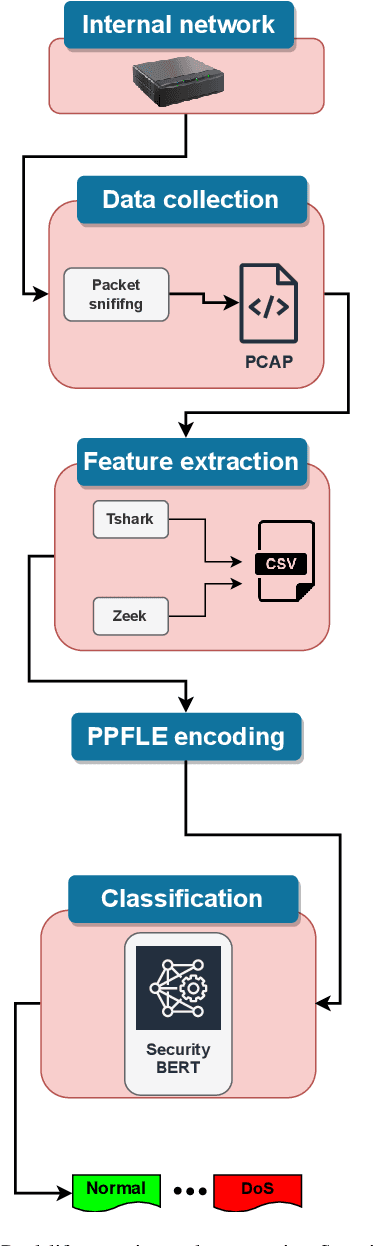
Natural Language Processing (NLP) domain is experiencing a revolution due to the capabilities of Pre-trained Large Language Models ( LLMs), fueled by ground-breaking Transformers architecture, resulting into unprecedented advancements. Their exceptional aptitude for assessing probability distributions of text sequences is the primary catalyst for outstanding improvement of both the precision and efficiency of NLP models. This paper introduces for the first time SecurityLLM, a pre-trained language model designed for cybersecurity threats detection. The SecurityLLM model is articulated around two key generative elements: SecurityBERT and FalconLLM. SecurityBERT operates as a cyber threat detection mechanism, while FalconLLM is an incident response and recovery system. To the best of our knowledge, SecurityBERT represents the inaugural application of BERT in cyber threat detection. Despite the unique nature of the input data and features, such as the reduced significance of syntactic structures in content classification, the suitability of BERT for this duty demonstrates unexpected potential, thanks to our pioneering study. We reveal that a simple classification model, created from scratch, and consolidated with LLMs, exceeds the performance of established traditional Machine Learning (ML) and Deep Learning (DL) methods in cyber threat detection, like Convolutional Neural Networks (CNN) or Recurrent Neural Networks (RNN). The experimental analysis, conducted using a collected cybersecurity dataset, proves that our SecurityLLM model can identify fourteen (14) different types of attacks with an overall accuracy of 98%
An Incremental Gray-box Physical Adversarial Attack on Neural Network Training
Feb 20, 2023


Neural networks have demonstrated remarkable success in learning and solving complex tasks in a variety of fields. Nevertheless, the rise of those networks in modern computing has been accompanied by concerns regarding their vulnerability to adversarial attacks. In this work, we propose a novel gradient-free, gray box, incremental attack that targets the training process of neural networks. The proposed attack, which implicitly poisons the intermediate data structures that retain the training instances between training epochs acquires its high-risk property from attacking data structures that are typically unobserved by professionals. Hence, the attack goes unnoticed despite the damage it can cause. Moreover, the attack can be executed without the attackers' knowledge of the neural network structure or training data making it more dangerous. The attack was tested under a sensitive application of secure cognitive cities, namely, biometric authentication. The conducted experiments showed that the proposed attack is effective and stealthy. Finally, the attack effectiveness property was concluded from the fact that it was able to flip the sign of the loss gradient in the conducted experiments to become positive, which indicated noisy and unstable training. Moreover, the attack was able to decrease the inference probability in the poisoned networks compared to their unpoisoned counterparts by 15.37%, 14.68%, and 24.88% for the Densenet, VGG, and Xception, respectively. Finally, the attack retained its stealthiness despite its high effectiveness. This was demonstrated by the fact that the attack did not cause a notable increase in the training time, in addition, the Fscore values only dropped by an average of 1.2%, 1.9%, and 1.5% for the poisoned Densenet, VGG, and Xception, respectively.